
TensorFlow2.0+TPUでData AugmentationしながらCIFAR-10


TensorFlow2.0+TPUでData AugmentationしながらCIFAR-10を分類するサンプルです。Data Augmentationはtf.dataでやるのがポイントです。
目次
TensorFlowを2.Xに上げる
まずは、ランタイム切り替えで「TPU」を選択しましょう。無料で利用できます。
現在(2019/10/16時点)のColabではTF1.X系が入っているので、2.X系にアップデートします。これはTF2.0.0にアップデートするケースです。2.X系のバージョンはだんだん上がっていくので順次値を変えましょう。
!pip install tensorflow==2.0.0
TPU使用のための下準備
GPUやCPUは何も準備要らないのに対し、TPUは使用開始のために下準備(おまじない)が必要になります。
import tensorflow as tf
import os
# tpu用
# 詳細 https://www.tensorflow.org/guide/distributed_training#tpustrategy
tpu_grpc_url = "grpc://" + os.environ["COLAB_TPU_ADDR"]
tpu_cluster_resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu_grpc_url)
tf.config.experimental_connect_to_cluster(tpu_cluster_resolver) # TF2.0の場合、ここを追加
tf.tpu.experimental.initialize_tpu_system(tpu_cluster_resolver) # TF2.0の場合、今後experimentialが取れる可能性がある
strategy = tf.distribute.experimental.TPUStrategy(tpu_cluster_resolver) # ここも同様
後々使うのは「strategy」という変数なので、これを最初に実行しておきましょう。
訓練コード
CIFAR-10を10層モデルで訓練するプログラムです。訓練データにData Augmentationを入れ、Horizontal flip+Random Cropを入れています。
import tensorflow.keras.layers as layers
import numpy as np
import pickle
def data_augmentation(image):
x = tf.cast(image, tf.float32) / 255.0 # uint8 -> float32
x = tf.image.random_flip_left_right(x) # horizontal flip
x = tf.pad(x, tf.constant([[2, 2], [2, 2], [0, 0]]), "REFLECT") # pad 2 (outsize:36x36)
# 黒い領域を作らないようにReflect padとしている(KerasのImageDataGeneratorと同じ)
x = tf.image.random_crop(x, size=[32, 32, 3]) # random crop (outsize:32xx32)
return x
def conv_bn_relu(inputs, ch, reps):
x = inputs
for i in range(reps):
x = layers.Conv2D(ch, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
return x
def create_model():
inputs = layers.Input((32, 32, 3))
x = conv_bn_relu(inputs, 64, 3)
x = layers.AveragePooling2D(2)(x)
x = conv_bn_relu(x, 128, 3)
x = layers.AveragePooling2D(2)(x)
x = conv_bn_relu(x, 256, 3)
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(10, activation="softmax")(x)
return tf.keras.models.Model(inputs, x)
def load_dataset():
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar10.load_data()
trainset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
trainset = trainset.map(
lambda image, label: (data_augmentation(image), tf.cast(label, tf.float32))
).shuffle(buffer_size=1024).repeat().batch(128)
testset = tf.data.Dataset.from_tensor_slices((X_test, y_test))
testset = testset.map(
lambda image, label: (tf.cast(image, tf.float32) / 255.0, tf.cast(label, tf.float32))
).batch(128)
return trainset, testset
def lr_scheduler(epoch):
if epoch <= 60: return 0.1
elif epoch <= 85: return 0.01
else: return 0.001
def main():
trainset, testset = load_dataset()
with strategy.scope():
model = create_model()
loss = tf.keras.losses.SparseCategoricalCrossentropy()
acc = tf.keras.metrics.SparseCategoricalAccuracy()
optim = tf.keras.optimizers.SGD(0.1, momentum=0.9)
# callback
scheduler = tf.keras.callbacks.LearningRateScheduler(lr_scheduler)
hist = tf.keras.callbacks.History()
# train
model.compile(optimizer=optim, loss=loss, metrics=[acc])
model.fit(trainset, validation_data=testset, epochs=100, steps_per_epoch=50000 // 128,
callbacks=[scheduler, hist])
history = hist.history
with open("history.dat", "wb") as fp:
pickle.dump(history, fp)
オプティマイザはモメンタムで、学習率は0.1、バッチサイズは128、60エポックと85エポックで学習率を1/10にしています。
1点注意なのが、tf.dataをfitに入れる場合はデータが一周するとデータセットが終わって訓練が止まってしまうためrepeat()を入れましょう。tf.dataのデータセットをfitに食わせるというのは昔のKerasではありませんでしたが、TF2.X系以降は1つの選択肢になりました。便利なのでtf.dataに慣れましょう。
また、repeat()については、fit内のvalidationについてはどうも入れなくてもいいようです。train側のデータセットのみrepeatを入れた所正常に動きました。また、データセットをrepeat()で無限ループさせる場合は、「steps_per_epoch」で1エポックあたりのステップ数を指定しましょう。
ラベルの値はもとのuint8だとTPUの訓練に失敗する(この記事を書いた時点)ので、Floatにキャストするのが無難です。
学習曲線の確認
訓練がうまくいっているか学習曲線を描いてみます。特に学習率の減衰あたりが正常に動作しているのか気になりますね。
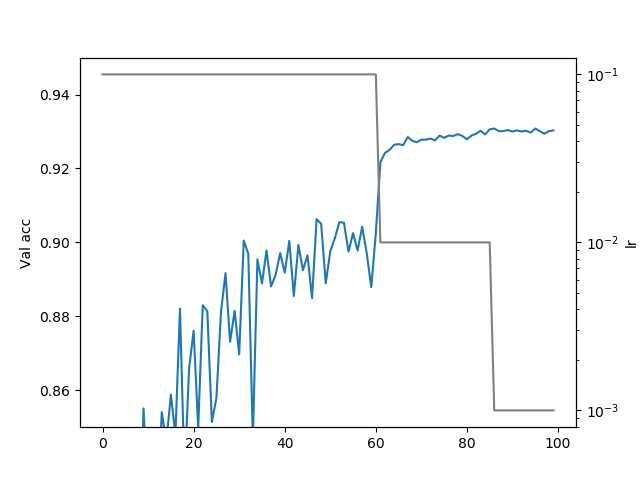
うまくいっています。学習率を下げたタイミングでVal accが大きく上がっているのでうまくいっています。いつの間にかHistoryに学習率を記録するようになったらしいです(いいこと)。
CIFARをTPUで動かせるということは、NNの教師あり学習が一通りできそうなので、TF2.0+TPUで遊ぶと楽しそうです。自分もGPUが埋まっているときにTPUで遊んでみたいと思います。
Colabノートブック
https://colab.research.google.com/drive/1IcRt4By4wTyh7IimGbKXBzVYZ40DR3YK
訓練所要時間:15分ぐらいです
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー