
TPUでも大きなバッチサイズに対して精度を出す
Posted On 2019-02-18


TPUでは大きなバッチサイズを適用することが訓練の高速化につながりますが、これは精度と引き換えになることがあります。大きなバッチサイズでも精度を出す方法を論文をもとに調べてみました。
目次
背景
Qiitaに書いたGoogle Brainの論文「学習率を落とすな、バッチサイズを増やせ」を読むの続き。自分でも調べてみました。
実験
CIFAR-10で実験、10層のレイヤーのネットワークを作り以下の条件で調べる。オプティマイザーはモメンタム(特に断りなければ係数0.9)でGoogle ColabのTPUで調べました。すべて250エポック訓練させます。
- バッチサイズを128、初期学習率を0.1として、100、150、200エポックで学習率を1/5ずつ減衰(baseline)。
- バッチサイズを128、初期学習率を0.1として、100、150、200エポックでバッチサイズを5倍ずつ増やす。128→640→3200→16000となる(increase batch size)
- バッチサイズを640、初期学習率を0.1、モメンタム係数を0.98として、100、150、200エポックで学習率を1/5ずつ減衰(increase momentum)
- バッチサイズを640、初期学習率を0.5として、100、150、200エポックで学習率を1/5ずつ減衰
理論的には、ノイズスケールはすべて一緒で、
- 1と2の学習曲線は一緒になるはず
- 3は1,2と比べると、モメンタムの係数を増やしているので若干テスト精度が落ちるはず
- 4は3との比較用で、仮に「初期の学習率」を上げた場合、精度の落ち方は3と比べてどのぐらいなのか
ということを確認していく。
コード
結果
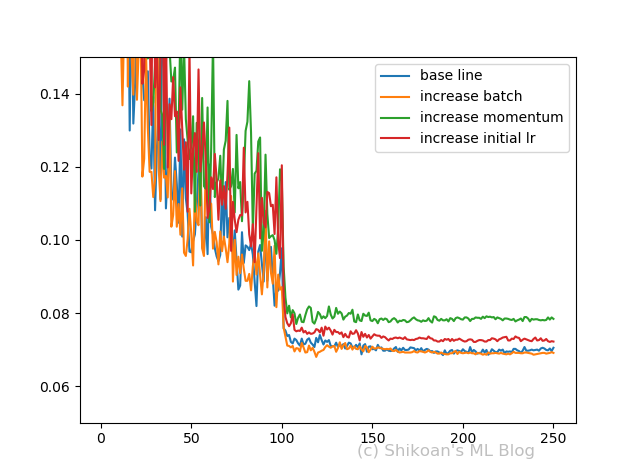
縦軸はValidationのエラーレートで、横軸はエポック数です
考察
- 1と2の学習曲線は一緒?→一緒、つまり学習率を下げることとバッチサイズを上げることは同じ
- モメンタムの係数を上げた3場合は?→だいたい学習曲線は一緒に見えるが、やはりテスト精度は下がっている
- モメンタム係数ではなく学習率を上げると?(4の場合)→テスト精度の落ち方がややマイルドになる。ただしこれは元の学習率によりけりなので、必ずしもこうなるとは限らない。
ほぼ論文の実験の通りの結果になりました。よりわかったことは、バッチサイズを上げる前提でいじる優先順位は、初期学習率>>モメンタム係数で、初期学習率を上げるとテスト精度が大きく下がってしまうケースではモメンタム係数を上げてみるというところではないでしょうか。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー