
論文まとめ:Vision Grid Transformer for Document Layout Analysis+OSS紹介

![]()
Vision TransformerとGrid Transformerを組み合わせ、視覚・テキストの両面からマルチモーダル情報を効果的に活用する手法VGTを提案。多様な文書タイプと詳細なレイアウトカテゴリを含む新データセットD4LAを構築し、既存手法を上回る高精度を達成した。
目次
OSS紹介
- PDF Document Layout Analysis
- Apache 2.0で利用可能
- 公式でDocker Hubが用意されており、手軽にCloneできる
- 日本語のデータで特化した訓練をしているわけではないのに、日本語ドキュメントでも結構行ける。OCRは日本語非対応
- レイアウト解析
$ curl localhost:5060/info
{"sys":"3.11.9 (main, Apr 19 2024, 16:48:06) [GCC 11.2.0]","tesseract_version":"tesseract 4.1.1\n leptonica-1.82.0\n libgif 5.1.9 : libjpeg 8d (libjpeg-turbo 2.1.1) : libpng 1.6.37 : libtiff 4.3.0 : zlib 1.2.11 : libwebp 1.2.2 : libopenjp2 2.4.0\n Found AVX2\n Found AVX\n Found FMA\n Found SSE\n Found libarchive 3.6.0 zlib/1.2.11 liblzma/5.2.5 bz2lib/1.0.8 liblz4/1.9.3 libzstd/1.4.8\n","ocrmypdf_version":"13.4.0+dfsg\n","supported_languages":["ar","zh-Hans","de","en","fr","hi","my","es","ta","th","tr","uk"]}
セグメント例1(AWS試験)
日本語文章。通常モード

セグメント例2(OpenAI論文)
英語文章:https://arxiv.org/abs/2502.06807
Fastモード
2502.06807v1_segment
セグメント例3(決算短信)
タイミーの決算短信を例に使う
Fastモード
1401202412125374111_segment_fast
通常モード
1401202412125374111_segment
テキスト抽出
OCRを使わずに、レイアウト解析の結果からテキスト抽出を行うことも可能。PDFからテキストを抜いているだけなので日本語も対応。参考
curl -X POST -F 'file=@/PATH/TO/PDF/pdf_name.pdf' localhost:5060/text
curl -X POST -F 'file=@/PATH/TO/PDF/pdf_name.pdf' localhost:5080 -F "types=text, title, section header, list item"
こんな感じに出てくる。結構すごい

モデル
- デフォルトのモデルはVision Grid Transformer。DocLayNetも使える
- 2種類目のモデルはLightGBMで(!!!!??)、Popplerで抽出したXML情報をベースにレイアウト検出している
ここで使ってるモデルが、Vision Grid Transformerなのでついでにその論文を読む(後述)
使ってみた感想
- Docker Hubあるのがめっちゃ嬉しい。Apache 2.0が◎
- Fastモードは早いがちょっとずれる。Dockerが立ち上がってればCPUで数秒で返ってくる
- 日本語データセットではおそらく訓練していないのになぜかうまくいく不思議(中国語のデータのせい?)
- 通常モードはちょっと遅い。CPUだと1ページ10秒ちょいかかる。ある程度大量に噛ませるならGPUが必須かもしれない
- ライブラリがもりもりなのでDockerイメージがまあまあ重い(展開時に21.2GB)。立ち上がりの速さは期待しないほうがいいかも
- このOSSはGrok3のDeepSearchが見つけてきたので、イーロン結構有能
論文要約 By Gemini
Vision Grid Transformer for Document Layout Analysis
https://arxiv.org/abs/2308.14978
この論文について、各質問への回答を以下に示します。
1. この論文において解決したい課題は何?
既存の文書レイアウト解析(DLA)手法は、視覚情報またはテキスト情報のいずれかに依存しており、複数モダリティの情報を十分に活用できていない。また、既存のDLAデータセットは科学論文に偏っており、種類やレイアウトカテゴリの多様性が不足している。この論文は、複数モダリティ情報を効果的に活用するDLA手法を提案し、多様な文書タイプと詳細なレイアウトカテゴリを含む新しいデータセットを構築することで、これらの課題を解決することを目指している。
2. 先行研究だとどういう点が課題だった?
先行研究のDLAモデルは、テキスト特徴または視覚特徴のいずれかに依存しており、マルチモーダルな情報を十分に活用できていなかった。グリッドベースの手法はマルチモーダルだが、事前学習の効果を無視していた。また、既存のDLAデータセットは科学論文に偏っていて、現実世界の多様な文書に対応できていなかった。
3. 先行研究と比較したとき、提案手法の独自性や貢献は何?
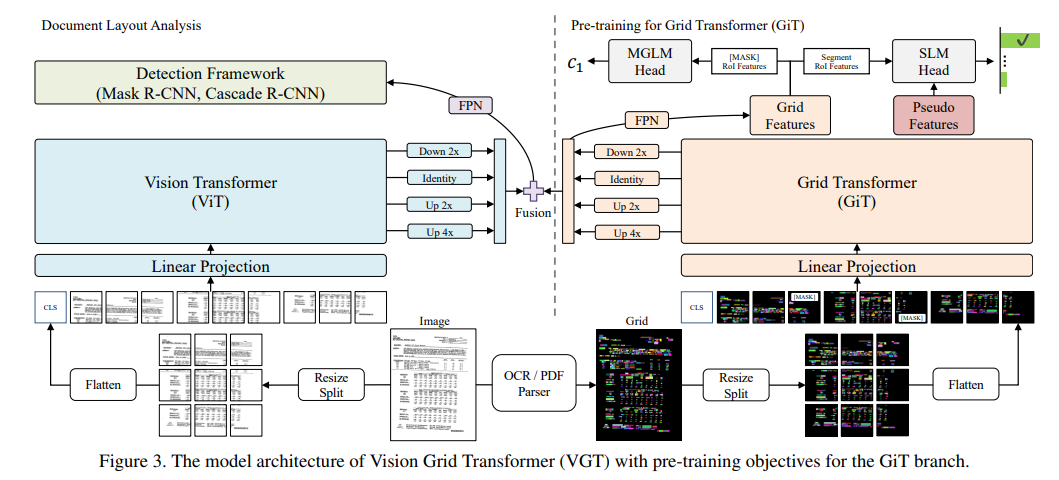
提案手法VGTは、Vision Transformer(ViT)とGrid Transformer(GiT)の2ストリーム構造を採用し、視覚情報とテキスト情報の両方を活用する。GiTは、2Dトークンレベルとセグメントレベルの理解のために、Masked Grid Language Modeling (MGLM)とSegment Language Modeling (SLM)という2つの新しい事前学習目標で学習される。さらに、多様な文書タイプと詳細なレイアウトカテゴリを含む新しいベンチマークデータセットD4LAを提案している。
4. 提案手法の手法を初心者でもわかるように詳細に説明して
VGTは、画像をViTで処理し、OCR結果をグリッド形式に変換してGiTで処理する2ストリームモデルです。GiTは、BERTのようにマスクされたトークンを予測するMGLMと、LayoutLMで生成された疑似特徴とセグメント特徴を整合させるSLMによって事前学習されます。ViTとGiTの特徴はマルチスケールで融合され、Cascade R-CNNを用いてレイアウト検出が行われます。
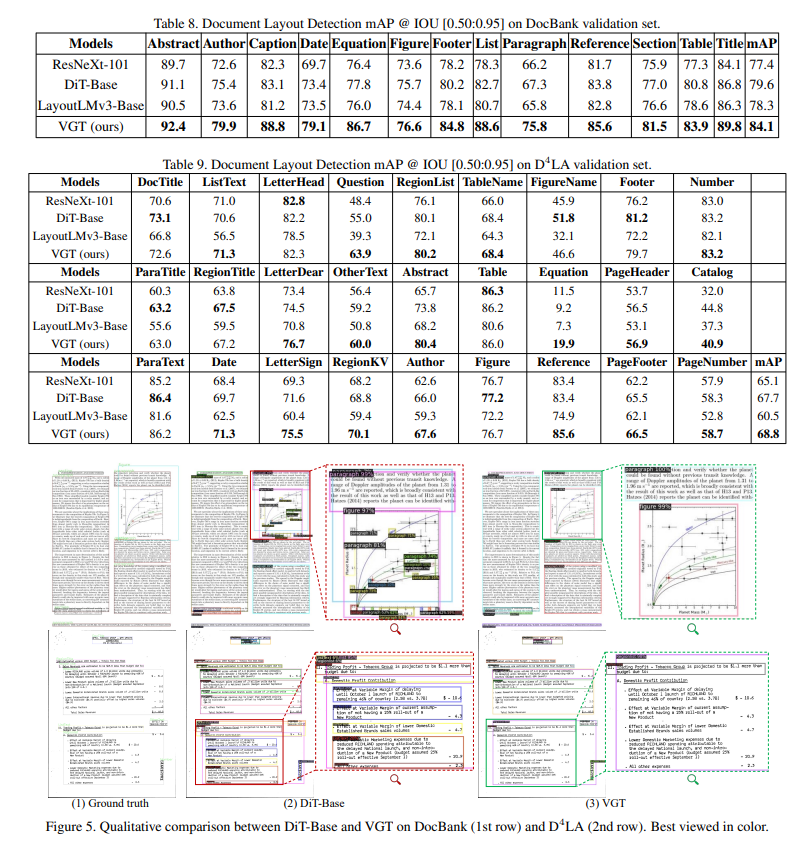
5. 提案手法の有効性をどのように定量・定性評価した?
PubLayNet、DocBank、そして提案データセットD4LAを用いて定量評価を行い、平均平均適合率(mAP)でSOTAを達成した。定性評価では、図表内のテキストを誤って段落と認識するといった誤りが、VGTによって修正される例を示し、2D言語モデリングの有効性を実証した。
6. この論文における限界は?
2ストリーム構造のためパラメータ数(243M)が多く、推論時間(460ms)が長い。また、画像中心の手法であるため、情報抽出などのテキスト中心タスクへの拡張が今後の課題。
7. 次に読むべき論文は?
・LayoutLM: https://arxiv.org/abs/1912.13318
・DiT: https://arxiv.org/abs/2206.11377
・LayoutLMv3: https://arxiv.org/abs/2204.08387
・VSR: https://arxiv.org/abs/2103.15311
コード:
https://github.com/AlibabaResearch/AdvancedLiterateMachinery (論文中に記載されているURL)
補足
このへんが新し目
- アーキテクチャーの改善:普通のパッチとグリッドベースのパッチの両方を考慮する
- D4LAデータセットの構築:既存の手法は科学論文に寄っていたが、それをもう少しデータのバリエーション増やした。キャプションやリストといった細かなアノテーションもつけている
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー