
論文まとめ:Visual Programming: Compositional visual reasoning without training
Posted On 2023-09-21


- タイトル:Visual Programming: Compositional visual reasoning without training
- 著者:Tanmay Gupta, Aniruddha Kembhavi
- 論文URL:https://arxiv.org/abs/2211.11559
- カンファ:CVPR 2023(Best Paper)
- プロジェクトページ:https://prior.allenai.org/projects/visprog
目次
概要
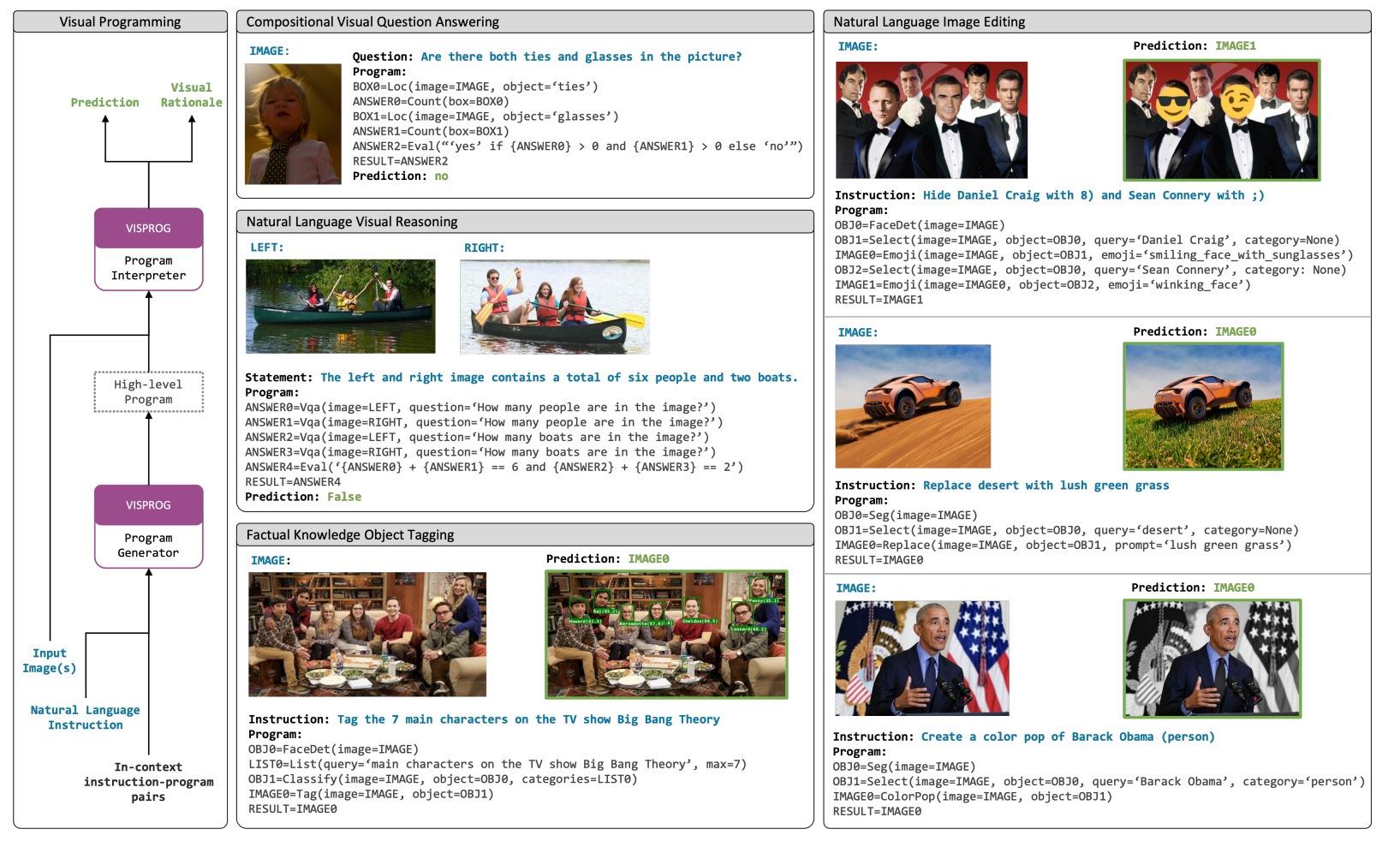
- 複数のツールを組み合わせて、Questionベースから実行するための画像処理のパイプラインをゼロショットで作るためのフレームワーク
- Instructに対応するツールのパイプラインをGPT3にIncontext Learningさせる
- モデルの訓練なしで画像処理のパイプラインが構築可能。CVPR 2023 BestPaper
- 以前の手法だと微分可能レンダリングなどを用いていたが、GPTを使うことでそれに必ずしもこだわる必要がなくなったのがポイント

評価
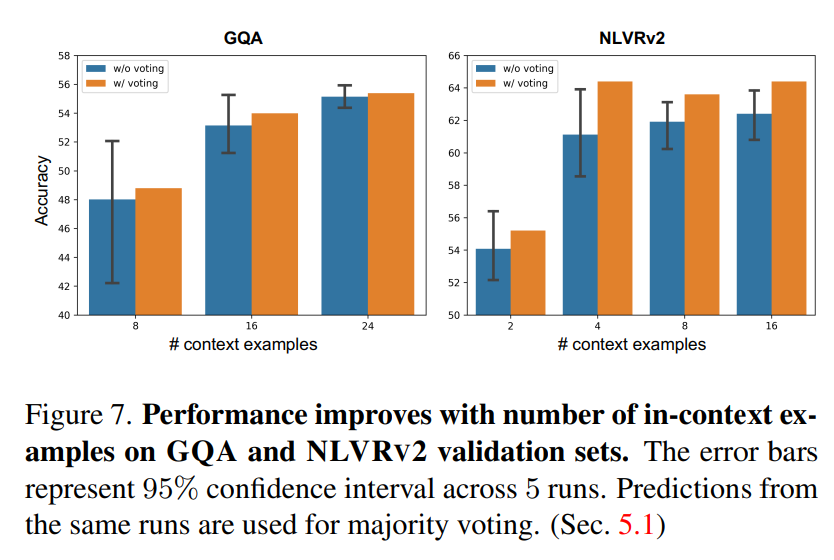
- Incontextの数(Few-shot example)を増やすと当然下流タスク(分類)の精度はよくなる
- 5回実行して結果をVotingさせると精度がちょっと伸びる(それはそう)
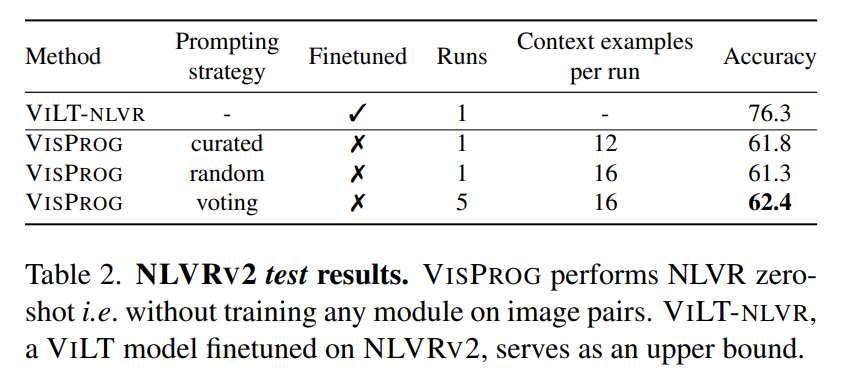
- ViLTというVQA(Visual Question Answering)のタスクを、NLVRv2データセットで評価したところ、ゼロショットのViLTモデル+VisProgでNLVRv2のデータセットでFine-tuningしたViLTより14%劣る精度を出せた
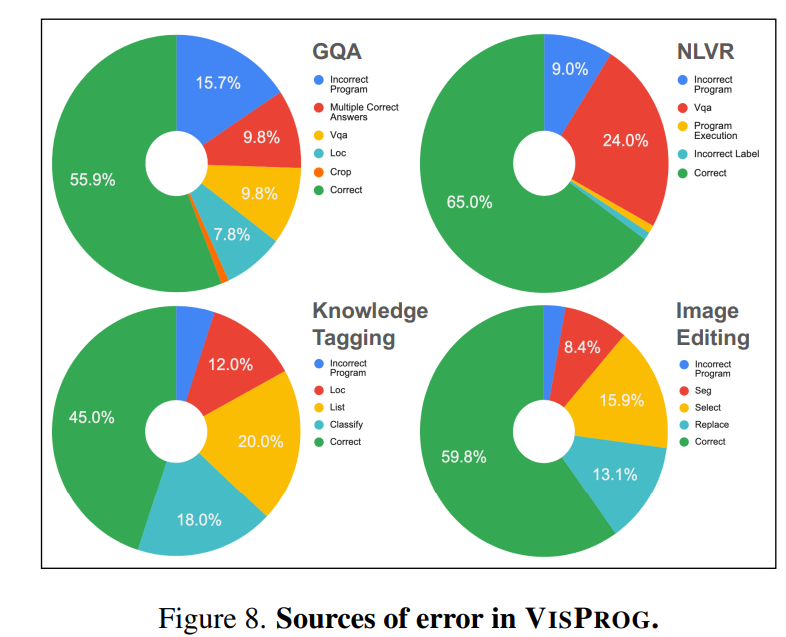
- VisProgのエラー分析。パイプライン構築の失敗(Incorrect Program)も多いが、NLVRのようにコンポーネント(VQAモデル)の失敗が支配的な結果もあった
- ユーザーによるプロンプトエンジニアリング。「IBMのCEOを検出して」というと失敗するが、「IBMの最新のCEOを検出して」というとうまくいく
- (訳注)本文ではInstruct Tuningと言っているが、LLMを再訓練するというInstruct Tuningの文脈ではなく、ただのプロンプトエンジニアリングだと思われる

所感
- 2022年11月の論文で、当時としてはChatGPTもなかったので目新しかったが、今となっては当たり前感がすごい
- これでCVPR 2023 BestPaperをとったのがかなり謎い
- ReActの精度向上のために、Incontext Learningするのはめっちゃ有り得そう。あるいはReActのデータベースを用意してRetrievalしてContextとして突っ込む
- 失敗例はIncontext Learningやメッセージ履歴として使ったら精度向上しそうな気がする
- (この論文のInstruct Tuningの文脈ではないが)、今のLLMの文脈でInstruct Tuningしてツールセットの流れを学習させるってのはありそう。あるいはGPTのFine-tuningなど
- 読むのが楽でよかった!
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー