
WarmupとData Augmentationのバッチサイズ別の精度低下について


大きいバッチサイズで訓練する際は、バッチサイズの増加にともなう精度低下が深刻になります。この精度低下を抑制することはできるのですが、例えばData Augmentationのようなデータ増強・正則化による精度向上とは何が違うのでしょうか。それを調べてみました。
目次
きっかけ
この記事を書いたときに、「Warmupってバッチサイズを大きくしても、確かに精度が劣化しにくい。でもそれって、精度が上がるからであって、一般的なData Augmentationをして精度全体を底上げしたら、同じことが起こるんじゃないの? WarmupとData Augmentationでバッチサイズを上げたときの精度劣化ってどう違うの?」って思ったのです。そこで、同一のData Augmentationをバッチサイズを変えて精度変化をプロットし、WarmupとData Augmentationによる劣化の違いを比較します。
ここでの精度劣化とは、バッチサイズを上げることによる副作用で、バッチサイズをどんどん上げていくと、あるところから急に精度が下落するという点です。
実験
この記事を拡張した実験をCIFAR-10で行います。以下の4条件を比較します。
- Data Augmentationなし
- 中程度のData Augmentation。いわゆるStandard Data Augmentation。4ピクセルの上下左右シフトと、水平反転。
- 強いData Augmentation。具体的にはこの記事のmode-4のジェネレーター。
- Warmupを使うケース(比較用)。バックで使っているData Augmentationは2(中程度)と同じ。1~3はWarmupなし。
WarmupのコードはQiitaの記事を参照してください。1~3のコードは末尾に示します。
結果
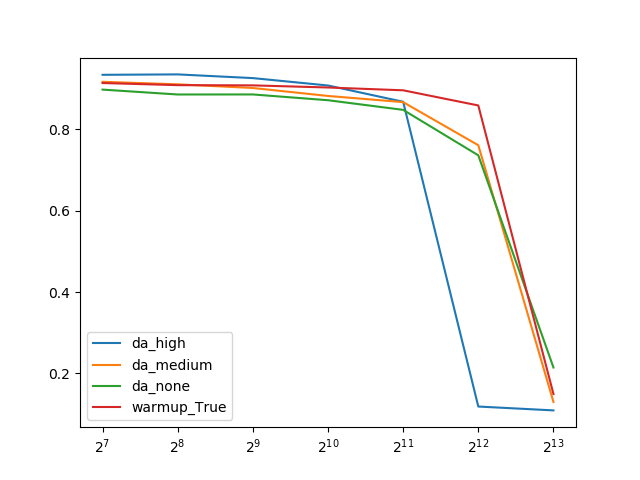
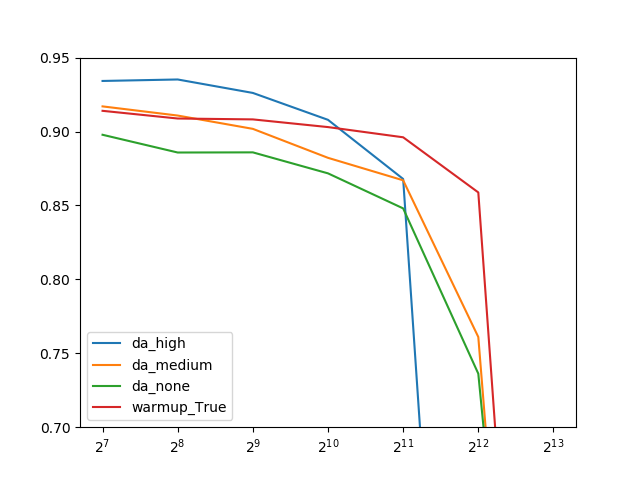
強いData Augmentationは低いバッチサイズで確かに高い精度を出しているのですが、バッチサイズを大きくするともっとも早く精度が急落しやすいということがわかりました。
つまり、Data Augmentationと精度の急落は別の次元の話で、Data Augmentationで精度を上げたからといって必ずしも急落が改善される(急落がくるのを遅らせられる)というわけではないということです。
一方で、中程度のData Augmentationでも、Warmupを使ったケースでは高バッチサイズ(2^12=2048)で最も高い精度を出しているので、Warmupのような急落を遅らせる技術というのも確かに存在するようです。
まとめ
Data Augmentationによる精度の向上の場合は、必ずしもバッチサイズの増加による精度の急落を改善できるわけではない。つまり、「低いバッチサイズで精度が上がったから、イコール高いバッチサイズ領域でも高い精度を出しますよ」は必ずしも成立はしない。
一方で、Warmmupは急落の改善に対して効いているため、Data Augmentationによる精度向上とWarmupによる精度向上は、次元の違う話である。ということでした。
コード
import tensorflow as tf
import tensorflow.keras as keras
import tensorflow.keras.layers as layers
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import numpy as np
import os
import pickle
from tensorflow.contrib.tpu.python.tpu import keras_support
def create_block(input, ch, reps):
x = input
for i in range(reps):
x = layers.Conv2D(ch, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
return x
def create_model():
input = layers.Input((32,32,3))
x = create_block(input, 64, 3)
x = layers.AveragePooling2D(2)(x)
x = create_block(x, 128, 3)
x = layers.AveragePooling2D(2)(x)
x = create_block(x, 256, 3)
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(10, activation="softmax")(x)
return keras.models.Model(input, x)
def wrap_scheduler(initial_lr):
def lr_scheduler(epoch):
x = initial_lr
if epoch >= 60: x /= 10.0
if epoch >= 85: x /= 10.0
return x
return lr_scheduler
def random_erasing(image, prob=0.5, sl=0.05, sh=0.2, r1=0.2, r2=0.8):
# パラメーター
# - image = 入力画像
# - prob = random erasingをする確率
# - sl, sh = random erasingする面積の比率[sl, sh]
# - r1, r2 = random erasingのアスペクト比[r1, r2]
assert image.ndim == 3
assert image.dtype == np.float32
if np.random.rand() >= prob:
return image
else:
H, W, C = image.shape # 縦横チャンネル
S = H * W # 面積
while True:
S_eps = np.random.uniform(sl, sh) * S
r_eps = np.random.uniform(r1, r2)
H_eps, W_eps = np.sqrt(S_eps*r_eps), np.sqrt(S_eps/r_eps)
x_eps, y_eps = np.random.uniform(0, W), np.random.uniform(0, H)
if x_eps + W_eps <= W and y_eps + H_eps <= H:
out_image = image.copy()
out_image[int(y_eps):int(y_eps+H_eps), int(x_eps):int(x_eps+W_eps),
:] = np.random.uniform(0, 1.0)
return out_image
def strong_data_augmentation(X, y, batch_size):
gen = ImageDataGenerator(rescale=1.0/255, horizontal_flip=True,
width_shift_range=4.0/32.0, height_shift_range=4.0/32.0,
zoom_range=[0.75, 1.25], channel_shift_range=50.0,
rotation_range=10)
for X_base, y in gen.flow(X, y, batch_size=batch_size, shuffle=True):
X = X_base.copy()
for i in range(X.shape[0]):
X[i] = random_erasing(X_base[i])
yield X, y
def train(batch_size, da_stregth):
tf.logging.set_verbosity(tf.logging.FATAL)
(X_train, y_train), (X_test, y_test) = keras.datasets.cifar10.load_data()
y_train = keras.utils.to_categorical(y_train)
y_test = keras.utils.to_categorical(y_test)
if da_stregth == "none":
train_gen = keras.preprocessing.image.ImageDataGenerator(
rescale=1.0/255.0,
).flow(X_train, y_train, batch_size=batch_size, shuffle=True)
elif da_stregth == "medium":
train_gen = keras.preprocessing.image.ImageDataGenerator(
rescale=1.0/255.0,
width_shift_range=4.0/32.0,
height_shift_range=4.0/32.0
).flow(X_train, y_train, batch_size=batch_size, shuffle=True)
elif da_stregth == "high":
train_gen = strong_data_augmentation(X_train, y_train, batch_size)
val_gen = keras.preprocessing.image.ImageDataGenerator(
rescale=1.0/255.0
).flow(X_test, y_test, batch_size=1000, shuffle=False)
initial_lr = 0.1 * batch_size / 128
scheduler = keras.callbacks.LearningRateScheduler(wrap_scheduler(initial_lr))
hist = keras.callbacks.History()
model = create_model()
model.compile(keras.optimizers.SGD(initial_lr, 0.9), "categorical_crossentropy", ["acc"])
tpu_grpc_url = "grpc://"+os.environ["COLAB_TPU_ADDR"]
tpu_cluster_resolver = tf.contrib.cluster_resolver.TPUClusterResolver(tpu_grpc_url)
strategy = keras_support.TPUDistributionStrategy(tpu_cluster_resolver)
model = tf.contrib.tpu.keras_to_tpu_model(model, strategy=strategy)
model.fit_generator(train_gen, steps_per_epoch=X_train.shape[0]//batch_size,
validation_data=val_gen, validation_steps=X_test.shape[0]//1000,
callbacks=[scheduler, hist], epochs=100, verbose=0, max_queue_size=3)
return hist.history
def train_all(da_flag):
result = {}
for batch_size in [128,256,512,1024,2048,4096,8192]:
print(batch_size, "Starts")
result[batch_size] = train(batch_size, da_flag)
with open(f"da_type_{da_flag}.pkl", "wb") as fp:
pickle.dump(result, fp)
if __name__ == "__main__":
train_all("none")
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー