
論文まとめ:Weak to Strong Generalization: Eliciting Strong Capabilities with Weak SUPERVISION
Posted On 2023-12-21


- タイトル:Weak to Strong Generalization: Eliciting Strong Capabilities with Weak SUPERVISION
- 著者:OpenAIの方々
- 論文URL:https://cdn.openai.com/papers/weak-to-strong-generalization.pdf
- コード:https://github.com/openai/weak-to-strong
目次
ざっくりいうと
- 弱いモデルで強いモデルを訓練し汎化するスーパーアラインメントの研究
- GPT-4/GPT3.5を生徒、GPT-2レベルを教師としてファインチューニング。NLPタスクでは汎化が容易だったが、人間の嗜好を学習するChatGPTのリワードモデルでは難しく、RLHFのスケーラビリティが課題
- スーパーアラインメントを今後実証研究進められることの示唆を提示した
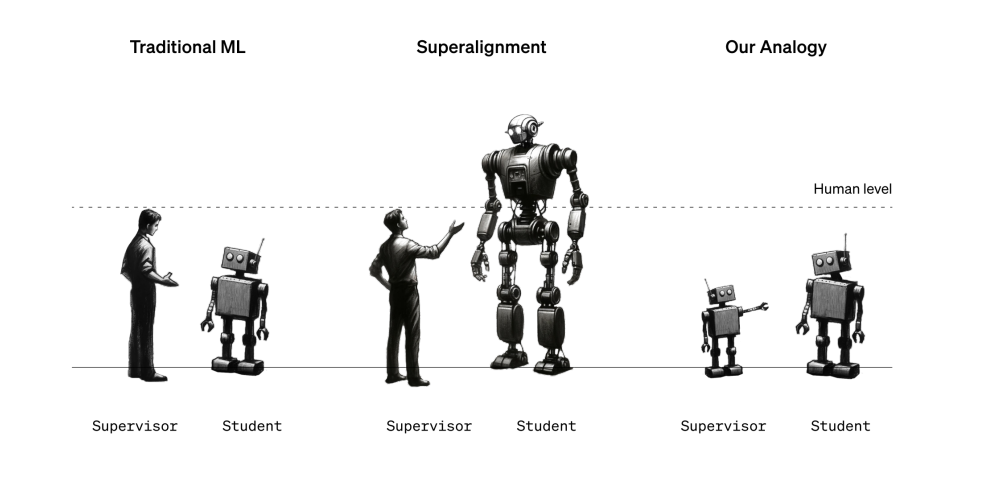
背景
- ChatGPTではRLHFが有効でとても強かった
- モデルが生成した回答が人間が意図したものか(質問に関連したものか、生成コードが安全かどうか)のタスクをアラインメントという
- 超人的なモデルでは、人間が十分に理解できない創造的な行動を行う。例えば、100万行のコードを見せられても、本当にアラインメントしているかは人間に判断できない
- 人間が確実に監督できないような、複雑な行動を生成するような超人的なモデルに対するファインチューニング
- この問題に対して、弱いモデルを教師として強いモデルをファインチューニングすることは可能化か?というアナロジーを行う(Weak-to-Strong Learning)
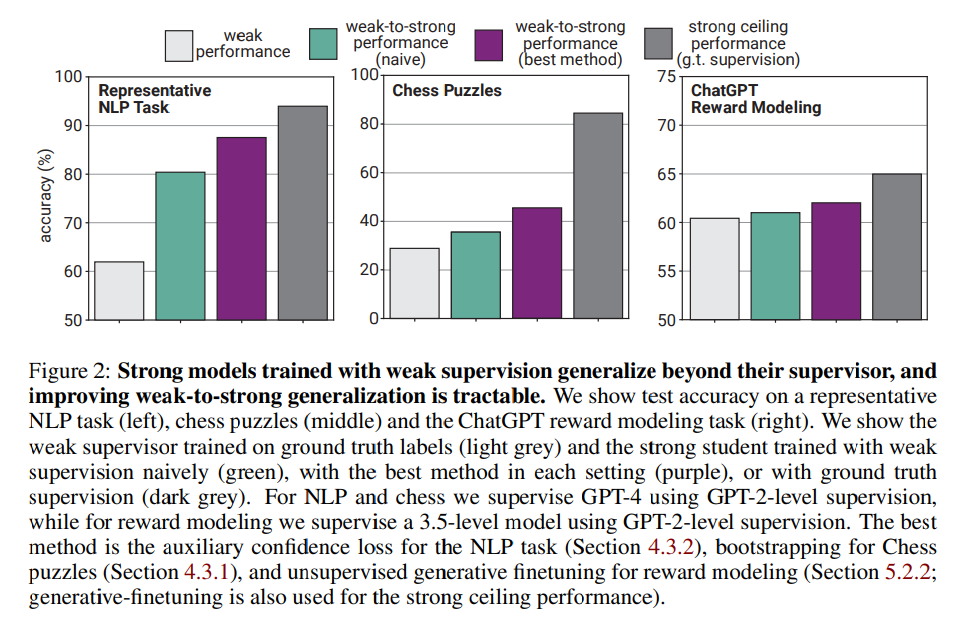
- GPT-4/GPT3.5をGPT-2のラベルを使ってファインチューニングするという例で検証
- 強い事前学習済みモデルは、弱い教師を超えて自然に一般化される。
- 弱いモデルによって生成ラベルを使って素朴に強いモデルをファインチューニングすると、それらは弱いモデルより常に優れている
- NLPのタスクで、GPT-2のラベルでGPT-4をファインチューニングすると、2つのモデル間の性能差の約半分を回復する
- 私の注釈:最初強いモデルが劣化しているだけかと思ったが、継続的に訓練しても精度が上がっていたので回復するという表現は適切
- 弱いモデルによって生成ラベルを使って素朴に強いモデルをファインチューニングすると、それらは弱いモデルより常に優れている
- 弱い教師で素朴にファインチューニングするだけでは十分ではない。グランドトゥルースのラベルで訓練された強いモデルとの間の性能差はまだ強く、特にChatGPTの報酬モデル(RM)では顕著
- ナイーブなRLHFが、追加作業なしでは超人的なモデルにはスケールしない可能性が高いという証拠
- 弱から強への汎化の改善しやすい
- 中間モデルでの教師ブートストラップ(bootstrapping supervision with intermediate models)
- 補助損失による信頼度の予測(confident predictions with an auxiliary
loss)- 補助損失を用いて、GPT-4をGPT-2レベルの教師でファインチューニングすると、性能差の80%近くを回復
- 教師なし学習によるモデル表現の改善(improving model representations with unsupervised finetuning)
関連研究
- 弱教師あり学習
- Student-Teacherモデル、知識蒸留
- 大規模データでの事前学習を行うことで、分布外性能への一般化
- デバイアス(偏った学習データからの学習)
- 強化学習や模倣学習
手法
Performance Gap Recovered(PGR)
Weak to StrongにおけるKPIを定義
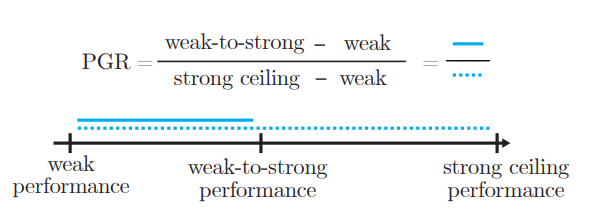
PGRが1ならWeak-to-Strongが完璧、0なら優れていない
結果
タスク
- NLPの22タスク。二値分類(倫理、常識的推論、自然言語推論、感情分析)
- チェスのパズル。生成的タスク
- ChatGPTの報酬モデリング。強化学習(RLHF)
- RLHFの重要なステップは、モデル応答間の人間の嗜好を予測するために報酬モデル(RM)を学習すること
素朴なファインチューニング
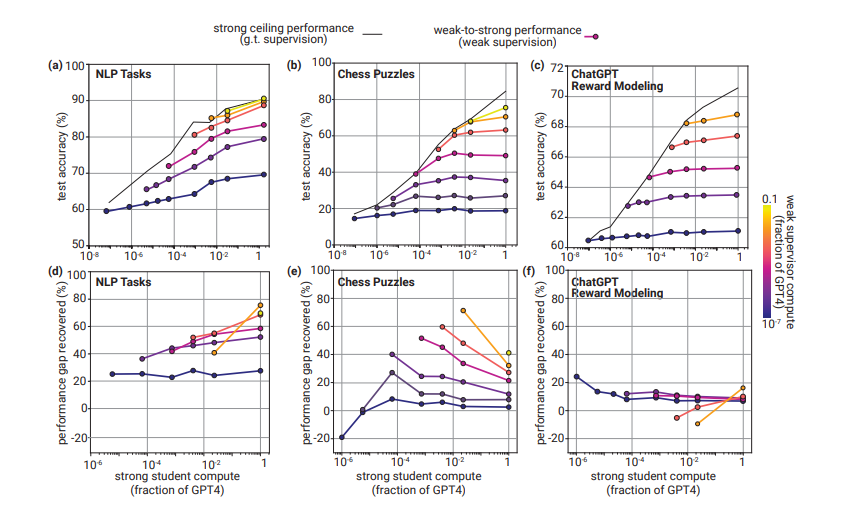
- 上図
- 横軸:GPT-4に対するモデルサイズの比率
- 縦軸:テスト精度
- 下図
- 横軸:GPT-4に対するモデルサイズの比率
- 縦軸:PGRの比率
- Weak-to-Strongの汎化は常に期待できるが、大きいモデルになるほどPGRが低下する
- NLPのタスクでは汎化が容易なものの、チェスのパズルやRMでは困難
素朴なファインチューニングからの改良
中間モデルを使ってブートストラップする
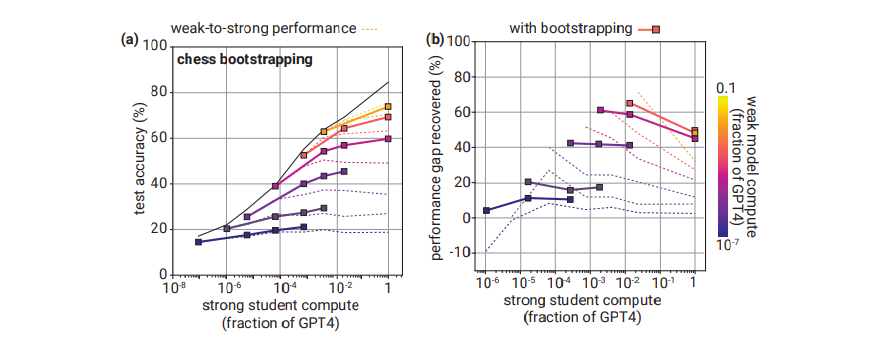
- ブートストラップはアラインメントにおいてずっと使われている
- 超人的なモデルをいきなりアラインメントするのではなく、超人的より若干弱い中間モデルを最初にアラインメントして、それを使って超人的なモデルをアラインメントする
- ここでのブートストラップ=中間モデルを使うということ
- これにより、チェスタスクのWeak-to-Strongの汎化が改善
補助損失を使うとNLPタスクが劇的に改善
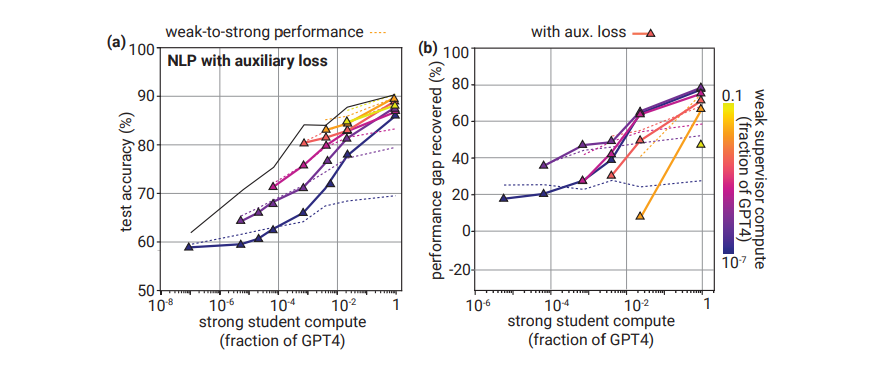
- 補助損失を導入すると、NLPのタスクを劇的に改善できる
- 補助損失を導入したい動機は、弱いモデルによる間違った教師データを模倣しないように正則化したい
- クロスエントロピーに、目的語の補助的な損失項を追加
- 半教師あり学習で有名な手法である「条件付きエントロピー最小化」に関連
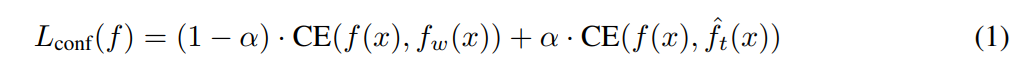
Weak-to-Strongの理解
弱いモデルへのオーバーフィット
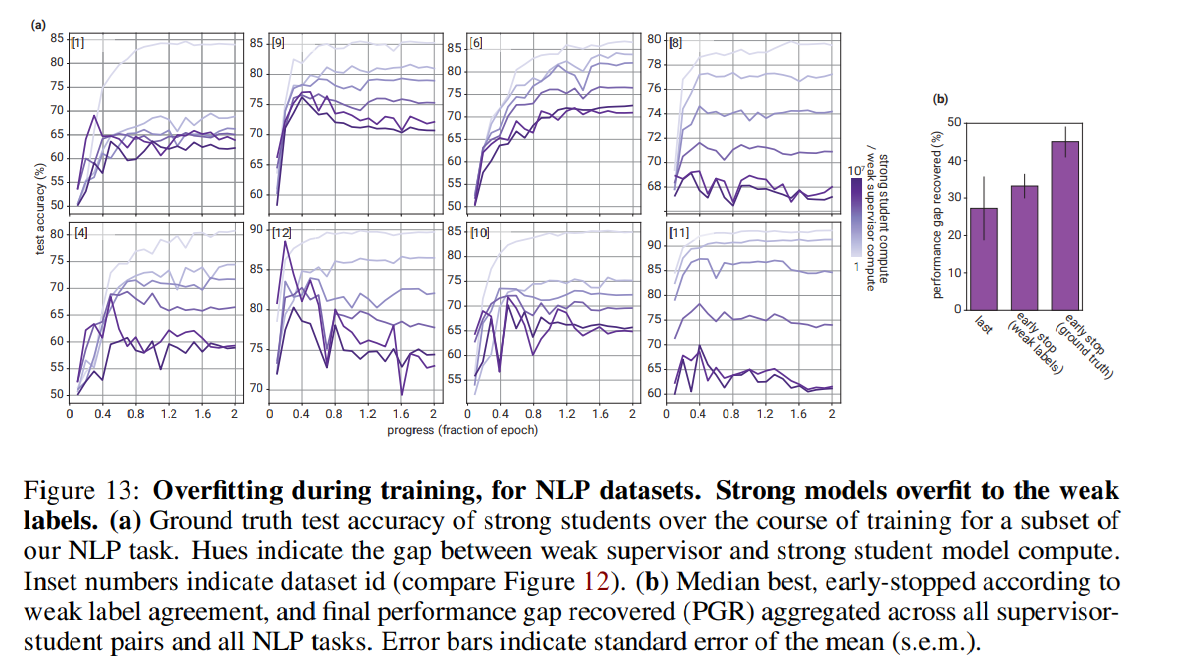
- 特に弱:強の計算量ギャップが大きい場合、訓練の早い段階で弱いモデルの教師にオーバーフィットすることがわかった
- Early Stoppingを使うと精度は上がるが不正なやり方なので、有効な手法ではない
大きいモデルほど教師モデルの出力の一致率は下がる
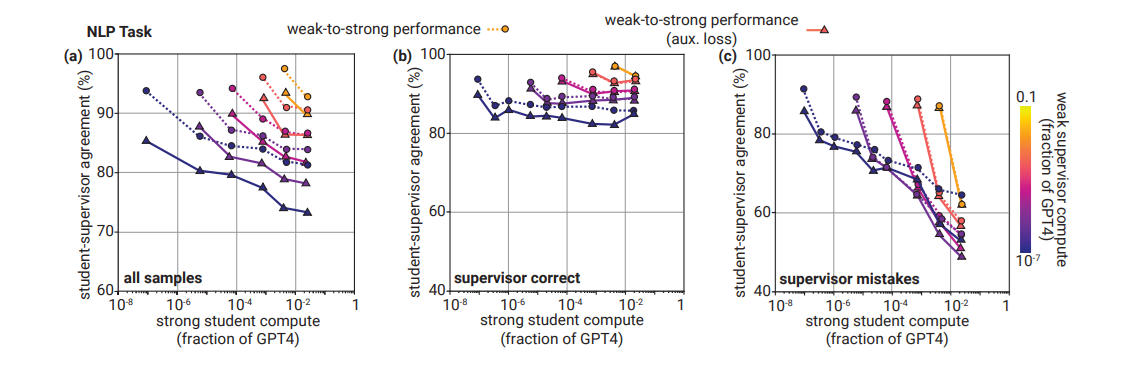
- 論文では「意外なことに」と言っているが、生徒の(強い)モデルが大きくなるほど、教師(強い)のモデルは生徒の(弱い)モデルの出力との一致率が下がる。これは教師のエラーに同意しなくなること
プロンプトエンジニアリングとの関係
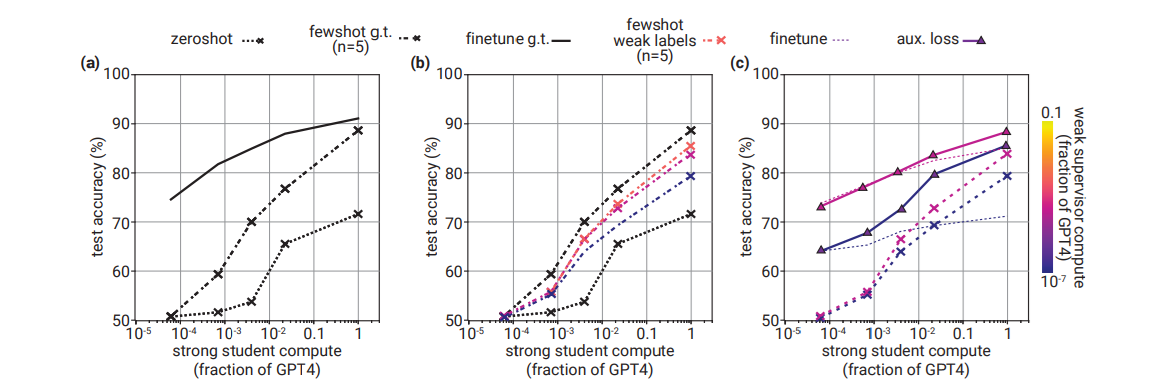
- モデルサイズが大きくなるほどプロンプトエンジニアリングが効く
- 5ショットのFew-shotプロンプトは劇的に増加する(逆にいうとGPT-4の場合はZeroshotとの差がほとんどない)
- モデルが大きくなるほど関連知識を引き出せるため
- モデルが多くなると、5ショットのプロンプトエンジニアリングは、ファインチューニングよりも精度を向上させる
教師なしデータによる訓練を追加することでRMが改善
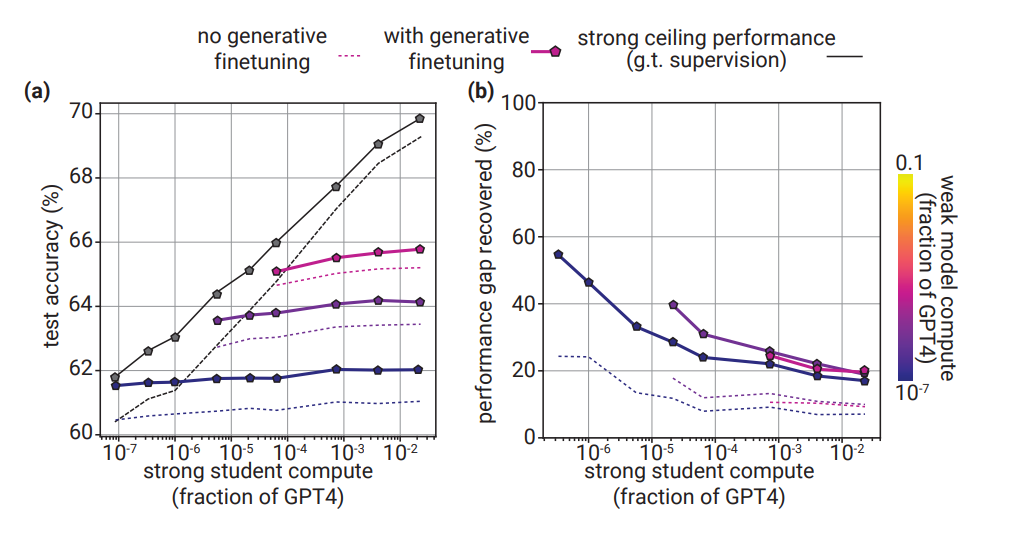
- 教師なし学習による追加訓練(生成的なファインチューニング)を追加することで最も難しかったRMでの性能が改善
- これまで頑張ってもPGRは30%程度
- 私の所感:NLPのタスクはいけても、人間の感性の模倣は難しいということではないか
議論
是非の検討
- 超人的なモデルは弱いモデルの誤りを簡単に模倣できる
- 人間のデータで学習させると人間の発言予測には効果的であるが、人間レベルの能力を出力するだけかもしれない(超人的な能力とはならないのではないか)
- 究極的なスーパーアラインメント問題には、この設定は部分的にしか捉えられず、別な問題設定が必要かもしれない。ここを徹底的に調査したいとのこと
- 事前学習のリーク:GPT-4シリーズの評価には各種データセットからのリークがあるだろう
- 超人的なモデルだと、潜在的なリークを誘発しにくいかもしれない
Appendix
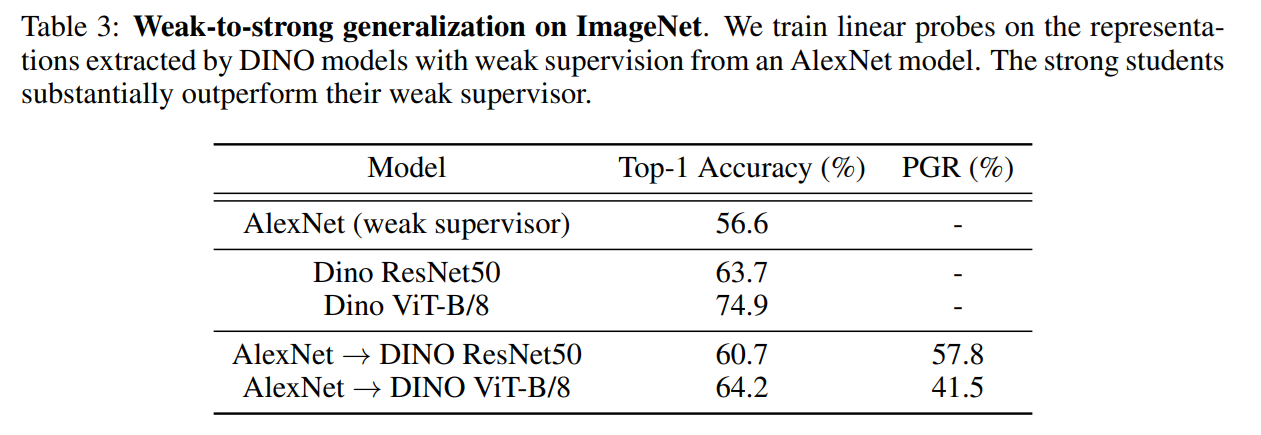
Weak-to-Strong の一般例。ImageNetでもおこった
所感
- モデルが劣化しているだけと何が違うんだろうという感じ。GTを超えてこないと研究として注目されないだろう
- 印象としては「やってみましたがよくわかりませんでした」レベルだが、OpenAIの考えてることがわかってよかった(OpenAI以外が出してもあんまり見向きされない研究かもしれない)
- 連合学習との組み合わせは結構有望そう
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー