
論文まとめ:Zero-1-to-3: Zero-shot One Image to 3D Object
Posted On 2023-03-30


- タイトル:Zero-1-to-3: Zero-shot One Image to 3D Object
- 著者:Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, Carl Vondrick(コロンビア大学、Toyota Research Institute)
- プロジェクトページ:https://zero123.cs.columbia.edu/
- コード:https://github.com/cvlab-columbia/zero123
- HuggingFace:https://huggingface.co/spaces/cvlab/zero123-live
目次
ざっくりいうと
- 訓練済みStable Diffusionを使い、単一画像から新たな視点画像を合成し、3次元復元を行う研究
- 大規模拡散モデルにカメラビューを取り込み、強いゼロショット性能を活用することで未知の視点を外挿する
- 3次元復元として明示的に訓練されていないにもかかわらず、従来の手法よりを凌駕する結果。動画生成やグラフィックスに応用可能
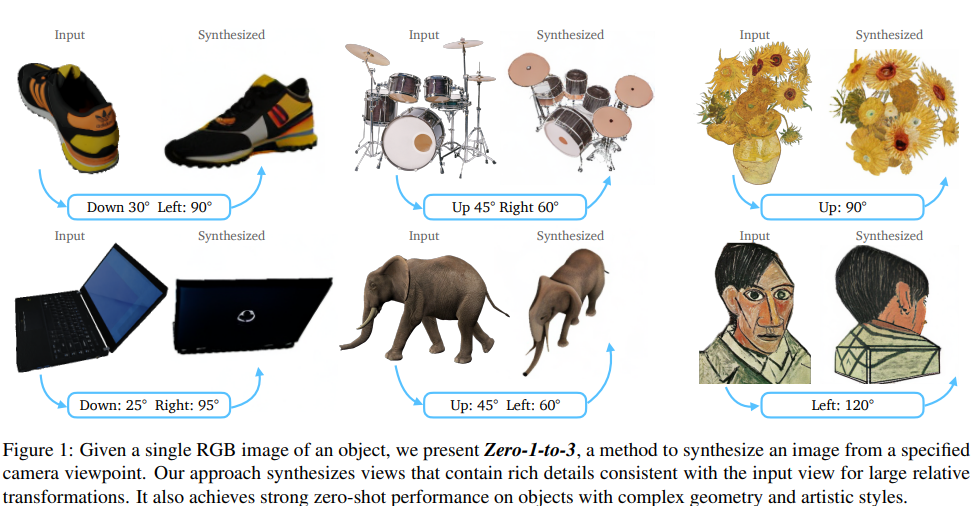
概要
- 3D画像再構成のための既存のアプローチのほとんどは、高価な3Dアノテーション(CADモデルなど)やカテゴリ固有の事前知識に依存し閉じた世界の問題設定
- 3次元復元をオープンワールド設定にした手法もいくつかあるが、学習にジオメトリ情報(ステレオビューやカメラのポーズ)が依然として必要とされる
- 拡散モデルに比べてデータの規模や多様性は少ない
- Stable Diffusionのような大規模拡散モデルにおいて、カメラの視点を操作する制御機構を学習することで、ゼロショットの新規視点合成と3D形状再構成を行うことができることを示す
- 拡散モデルは、カメラ対応関係のない2次元単眼画像で学習
- 生成過程で相対的なカメラの回転や移動の制御を学習するようにモデルを微調整
- この研究のお気持ち:訓練済みStable Diffusionから豊富な幾何学的情報を直接抽出できることを実証したい
- 追加の深度情報の必要性を軽減
手法

- Inputは画像、Outputは画像
- $x$は入力の視点の画像(Input Vidw)、$\hat{x}$は希望する視点の画像(Output View)
- Rはカメラの回転行列、Tは並進行列(例:45度上げて、60度左に)
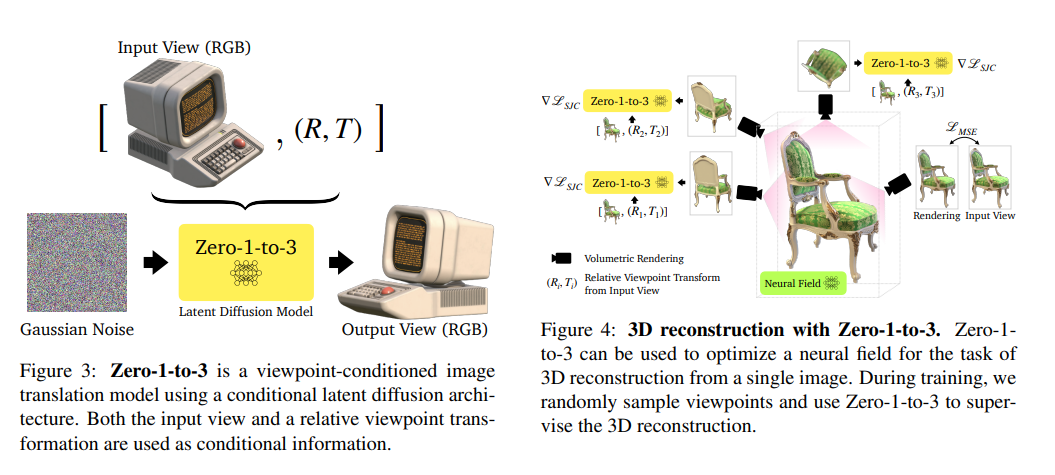
- 単眼のRGB画像から新しい画像を合成することは非常に制約が多い→Stable Diffusionを使う
- Stable Diffusionは、テキストから多様な画像を生成する際に、並外れたゼロショット能力がある
視点条件つきのDiffusion
- 1枚の画像から三次元復元するためには、低レベルの知覚(奥行き、陰影、質感など)、高レベルの理解(種類、機能、構造など)の両方が必要
- 入力では、入力画像のCLIP埋め込みと(R, T)と連結され、「ポーズCLIP」埋め込み c(x, R, T) を形成
- 普通のStableDiffusionだとCLIP埋め込みだけ
- 単にカメラ情報のR, Tをベクトル結合する
- 入力画像の高レベルの意味情報を提供するノイズ除去U-Netを条件付けるために、クロスアテンションを適用
3次元復元
- 訓練中はランダムに視点をサンプリングし、ボリュームレンダリングを行う
- ニューラル場上での損失計算を行い、3次元構成を加味した学習を行う
- 「見ていない部分」の外挿はStable Diffusionのゼロショット性能で対応する
- 「Score Jacobian Chaining (SJC) 」というOSSで3次元表現を学習
データセット
- Objaverse:100K以上のアーティストによって作成された800K以上の3Dモデルを含む大規模なオープンソースデータセット
- 3Dモデルから機械的に作成
結果
このモデルでできること
- 新たな視点の画像生成
- 3次元表現の獲得
新たな視点画像の生成

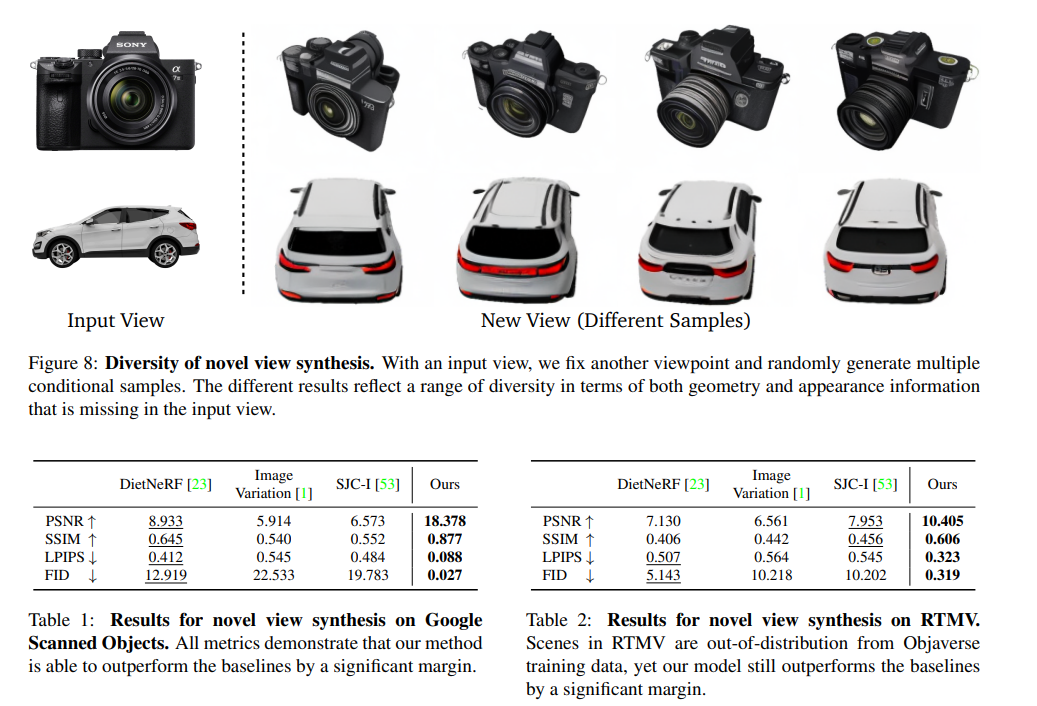
- 既存モデルに比べて明らかに性能が良い
- Table2はOODなデータセットだったが、ロバストだった
- Stable Diffusionによる外挿が効いてる
3次元復元

- Table4(RMTV)はOOD
- RTMVは多くのオブジェクトを含む乱雑なシーンで構成されているため、先行研究のどのアプローチもあまりうまく機能しない
- 提案手法は、3D再構成タスクのために明示的に訓練されていないにもかかわらず、最も優れた結果
今後の研究
- オブジェクトからシーンへ
- この手法は、無地の背景上の単一オブジェクトで訓練したが、複数オブジェクトのシーンへの汎化は実証できた
- 複雑な背景を持つシーンへの汎化は、今後の課題
- シーンから動画へ
- ジオメトリを推論できるようになったので、単一のシーンから動画生成が可能
- グラフィックスパイプラインとStable Diffusionの組み合わせ
- Stable Diffusionには、照明、シェーディング、テクスチャなどの暗黙な知識が含まれる
- 将来的には、シーンの再照明など、従来のグラフィックスタスクを実行するための同様のメカニズムを探求可能
所感
- 最初は三次元復元の論文として読んでいたが、実はStable Diffusionの応用で、動画生成やグラフィックスへの応用が見えているのがいい
- (最近のぼちぼちそういう研究はあるが)大規模拡散モデルの画像生成自体がかなり優秀な事前訓練であり、基盤モデルとしての要素が出てきたのが面白い
- 推論にVRAMが22GBもいるのが弱点
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー