
論文まとめ:Efficient Track anything


- 論文名:Efficient Track anything
- URL:https://arxiv.org/abs/2411.18933
- GitHub:https://github.com/yformer/EfficientTAM
- カンファ:ICCV 2025
目次
論文要約 By Gemini 2.5
はい、承知いたしました。与えられた論文の内容について、以下の通り60秒で読めるように一問一答形式でまとめます。
- この論文において解決したい課題は何?
- SAM 2の計算コストが高く、モバイルデバイスなどでのリアルタイムな動画オブジェクトセグメンテーションが難しい。
- 先行研究だとどういう点が課題だった?
- SAM 2は、大規模な画像エンコーダとメモリモジュールを使用しており、特にモバイル環境での効率が悪い。
- 先行研究と比較したとき、提案手法の独自性や貢献は何?
- 軽量なViTを画像エンコーダとして再評価し、効率的なメモリモジュールを導入することで、高速かつ軽量なEfficientTAMを提案。
- 提案手法の手法を初心者でもわかるように詳細に説明して
- 軽量なViTで動画の各フレームの特徴を抽出し、効率的なメモリモジュールで過去のフレーム情報を活用。これにより、計算量を減らしつつ、高精度なセグメンテーションを実現。
- 提案手法の有効性をどのように定量・定性評価した?
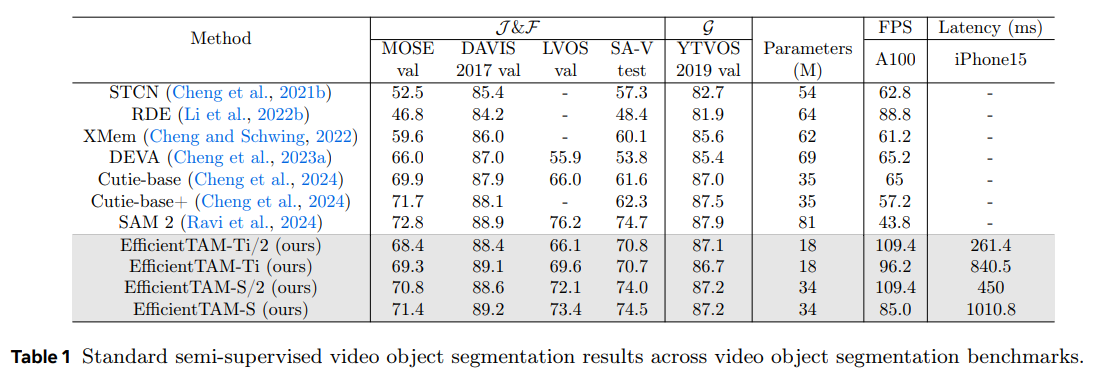
- 複数の動画セグメンテーションベンチマーク(MOSE, DAVIS, LVOS, SA-V)で評価。また、iPhone 15 Pro Maxでの実行速度も測定。
- この論文における限界は?
- EfficientTAMはSAM 2に匹敵する性能を持つものの、一部のタスクではわずかに性能が劣る場合がある。
- 次に読むべき論文は?
- 論文中で引用されている、SAM (Kirillov et al., 2023)、EfficientSAM (Xiong et al., 2024b)、SAM 2 (Ravi et al., 2024)を読むと、より理解が深まる。
- コード
- プロジェクトのウェブサイト: https://yformer.github.io/efficient-track-anything/
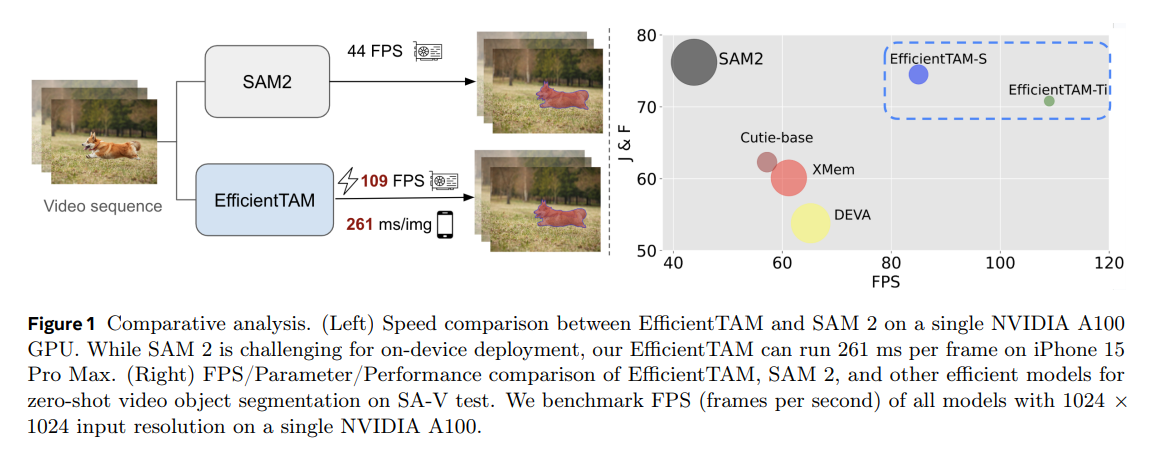
ポイント
EfficientTAMsは、SAM 2が採用する階層型画像エンコーダーではなく、より軽量な非階層型Vision Transformer (ViT)を画像エンコーダーとして使用し、さらに効率的なメモリモジュールを導入することで、低遅延と小さいモデルサイズで高品質な結果を達成しています。
階層型画像エンコーダーと非階層型ViT(Vision Transformer)画像エンコーダーの主な違いは、特徴抽出のアプローチとアーキテクチャの複雑さにあります。これがモデルの速度に大きく影響します。
階層型と非階層型の違いとその理由
階層型画像エンコーダー (SAM 2で使用)
- 特徴抽出: SAM 2は、ビデオオブジェクトセグメンテーションのために、大規模な多段階画像エンコーダーを使用して階層的なフレーム特徴を抽出します。これにより、異なるスケールの特徴(例えば、HieraB+ではストライド16と32の特徴をメモリモジュールに、ストライド4と8の特徴をマスクデコーダーのアップサンプリング層に供給)を利用できます。
- アーキテクチャの例: SAM 2のデフォルトの画像エンコーダーはHieraB+です。Hieraは、階層的なステージ構造を持つ階層型Vision Transformerの一種です。
- 複雑性: この多段階設計と階層的特徴の使用は、計算の複雑性が高く、特にモバイルデバイスでのリアルタイムアプリケーションに課題をもたらします。HieraB+はパラメーター効率が悪く、例えば約80Mのパラメーターを持っています。SAM 2の「タイニー」バージョンでさえ、階層型画像エンコーダーのため、デフォルトモデルとほぼ同じ実行時間を示します(43.8 FPS vs 47.2 FPS)。
非階層型ViT画像エンコーダー (EfficientTAMで使用)
- 特徴抽出: EfficientTAMは、ビデオオブジェクトセグメンテーションのために、プレーンで非階層的なVision Transformer(ViT)を画像エンコーダーとして再検討しています。具体的には、軽量なバニラViT(例:ViT-TinyやViT-Small)を使用します。このエンコーダーは、単一スケールの特徴マップを出力し、SAM 2のように複数の階層的特徴をデコーダーのアップサンプリング層に追加しません。
- アーキテクチャの例: オリジナルのViTファミリーは、ViT-TinyからViT-Hugeまで、プレーンな非階層型アーキテクチャで構成されています。EfficientTAMは、16×16のパッチサイズを持つViT-SmallとViT-Tinyを採用し、効率的な特徴抽出のために14×14の非重複ウィンドウアテンションと4つの等間隔グローバルアテンションブロックを使用します。
- 単純性: この設計はSAM 2の複雑さを軽減し、EfficientTAMを非常に効率的にし、モバイルデバイスへの展開を可能にします。
なぜこれが速度に影響するのか?
このアーキテクチャの違いが速度に影響する理由は以下の通りです。
- 計算の複雑さの軽減:
- SAM 2の大規模な多段階画像エンコーダーとメモリモジュールは、計算コストが高いため、リアルタイムのタスク、特にモバイルデバイスでの実行が困難でした。
- 階層型モデルは、一般的にプレーンなViTモデルよりも展開時に遅い傾向があります。
- EfficientTAMは、軽量なバニラViTと、メモリモジュールにおける効率的なクロスアテンションの導入により、フレーム特徴抽出とメモリ計算の両方の複雑さを低減します。
- パラメーター数の削減:
- EfficientTAMは、SAM 2(HieraB+SAM 2)と比較して、約2.4倍のパラメーター削減を達成しています。パラメーターが少ないモデルは、一般的に推論速度が速くなります。
- 推論速度の向上:
- これらの最適化の結果、EfficientTAMはSAM 2と比較して顕著な速度向上が見られます。
- NVIDIA A100 GPUでは、SAM 2に対して約2倍の速度向上を実現しています。
- 画像セグメンテーションタスクでは、オリジナルのSAMに対して約20倍の速度向上を示しています。
- iPhone 15 Pro Maxのようなモバイルデバイスでは、EfficientTAMは合理的な品質でビデオオブジェクトセグメンテーションを約10 FPSで実行できます。これは、SAM 2がオンデバイス展開には課題があるという課題を解決します。
- 例えば、EfficientTAM-S/2 (効率的なメモリ注意機能付き) は、iPhone 15で1フレームあたり450ミリ秒の実行時間を達成し、効率的なクロスアテンションを使用しないEfficientTAMと比較して2倍以上の遅延短縮を実現しています。
- これらの最適化の結果、EfficientTAMはSAM 2と比較して顕著な速度向上が見られます。
このように、非階層的で軽量なViTエンコーダーを採用することで、EfficientTAMはSAM 2の主要な速度ボトルネック(大規模でパラメーター効率の悪い階層型エンコーダーとメモリモジュール)に対処し、大幅な速度向上とモバイルデバイスでの展開可能性を実現しています。
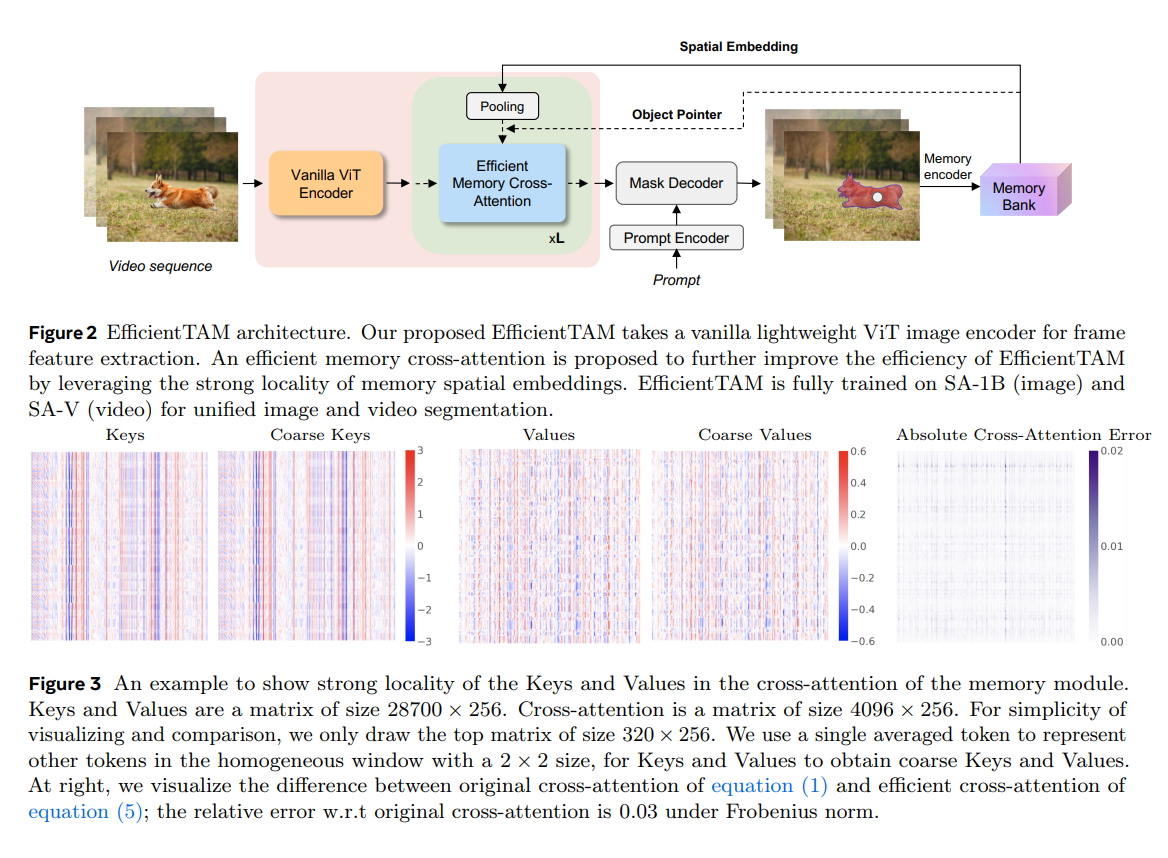
性能低下対策
バニラなViT(Vision Transformer)を画像エンコーダーとして使用した場合、性能が低下するのではないかというご懸念について、ソースに基づいてご説明します。
性能への影響と工夫の概要
EfficientTAMは、SAM 2の「大規模で多段階な画像エンコーダーとメモリモジュール」による高い計算複雑性という課題に対処するため、あえてプレーンで非階層型のViTを画像エンコーダーとして採用しています。
このアプローチは、一般的に階層型モデルが「実用的な展開においてプレーンなViTモデルよりも遅い傾向がある」という観察に基づいています。しかし、EfficientTAMは単に「バニラViT」を採用するだけでなく、大幅な速度向上を実現しながらも、SAM 2に匹敵する、あるいはそれに近い性能を維持するための複数の「工夫」を施しています。
実際、EfficientTAMはSA-Vテストデータセットにおいて、SAM 2(HieraB+SAM 2)と同等の性能を示しています(EfficientTAM-Sが74.5 J&F、SAM 2が74.7 J&F)。これは、SAM 2と比較してA100 GPUで約2倍の速度向上と約2.4倍のパラメーター削減を実現しつつ、わずか2 J&F未満の性能差に抑えられています。
性能低下を抑えるための主な工夫
EfficientTAMがバニラViTを採用しつつも、高い性能を維持できる主な工夫は以下の通りです。
- 効率的な画像エンコーダーの採用
- 軽量なバニラViTの使用: EfficientTAMは、SAM 2のデフォルトエンコーダーであるHieraB+(約80Mパラメーターでパラメーター効率が悪い)の代わりに、軽量なViT-TinyやViT-Smallを画像エンコーダーとして再検討・採用しています。
- 単一スケールの特徴マップ出力: SAM 2が複数の階層的特徴(ストライド4, 8, 16, 32)をメモリやデコーダーに供給するのに対し、EfficientTAMの画像エンコーダーは単一スケールの特徴マップを出力し、デコーディング時にアップサンプリング層に他の特徴を追加しません。
- 効率的なアテンションメカニズム: 16×16パッチサイズを持つViT-SmallおよびViT-Tinyを使用し、効率的な特徴抽出のために14×14の非重複ウィンドウアテンションと4つの等間隔グローバルアテンションブロックを導入しています。
- 効率的なメモリモジュールの導入
- クロスアテンションのボトルネック解消: SAM 2のメモリモジュールにおけるクロスアテンションは、非常に長いメモリートークンシーケンス(例:約30K)が原因で、高い計算コストとメモリコストを伴う効率のボトルネックとなっていました。
- 空間メモリートークンの局所性活用: EfficientTAMは、このボトルネックを解消するため、メモリー空間トークンが持つ「強い局所性」(local smoothness)という内在的な構造を積極的に活用しています。
- 粗い表現への平均プーリング: この局所性を利用し、空間メモリートークンを平均プーリングによって粗い表現(coarser representation)に変換します。これにより、キー(K)とバリュー(V)の計算を効率化し、元のクロスアテンションの良い代替となることを示しています。これは、性能の大きな低下なしに計算量を削減することに成功しています。
- オブジェクトポインターの保持: メモリモジュールでは、オブジェクトポインターが性能向上に大きく貢献するため、EfficientTAMでも引き続きオブジェクトポインターを空間トークンと連結して使用しています。
- 大規模データセットでの学習
- EfficientTAMは、SAM 2と同様に、SA-1B(画像)とSA-V(ビデオ)という大規模で多様なデータセットでモデル全体を学習しています。これにより、基盤モデルとしての強力な汎化性能と品質を維持しています。
これらの工夫により、EfficientTAMは「軽量なバニラViT画像エンコーダーと、メモリ計算の複雑さを軽減する効率的なメモリモジュール」を組み合わせることで、SAM 2の主要な速度ボトルネックに対処し、モバイルデバイスへの展開を可能にするほどの効率化を実現しつつ、同等の高品質なセグメンテーション結果を生成できています。特にiPhone 15 Pro Maxのようなモバイルデバイスでは、合理的な品質でビデオオブジェクトセグメンテーションを約10 FPSで実行できることが強調されています。
訓練方法
EfficientTAMはSAM 2から蒸留されたものではなく、新たに訓練されたモデルです。
ソースによると、EfficientTAMの訓練プロセスは以下のようになっています。
- 画像エンコーダーの初期化: EfficientTAMのViT画像エンコーダーは、事前に訓練されたViT(EfficientSAMs)から初期化されています。EfficientSAMsは、SAMの計算コストを削減するための先行研究です。
- 事前学習: メモリコンポーネントを含まないEfficientTAMは、SAM 2と同様に、SA-1Bデータセットで90,000ステップの事前学習が行われています。SA-1Bは、11億の高品質セグメンテーションマスクを持つ1100万の多様な高解像度画像で構成されています。
- 完全な訓練: 事前学習後、EfficientTAMはメモリコンポーネントを含めて、SA-VデータセットとSA-1Bの10%サブセットで300,000ステップ訓練されています。SA-Vは、51,000本のビデオと60万のマスク注釈を含む大規模で多様なビデオセグメンテーションデータセットです。SAM 2とは異なり、EfficientTAMは公正な比較のために他のオープンソースデータセットや内部データセットを使用していません。
- 目的: EfficientTAMのアイデアは、ビデオオブジェクトセグメンテーションのためのプレーンで非階層的なVision Transformer (ViT) を画像エンコーダーとして再検討することと、効率的なメモリモジュールを導入することに基づいています。これにより、SAM 2の「大規模な多段階画像エンコーダーとメモリモジュール」による高い計算複雑性という課題に対処し、大幅な速度向上とモバイルデバイスへの展開可能性を実現しています。
要するに、EfficientTAMはSAM 2とは異なるアーキテクチャ(軽量なバニラViTエンコーダーと効率的なメモリモジュール)を採用し、SA-1BおよびSA-Vという大規模データセットを使ってゼロから訓練されています。これにより、SAM 2に匹敵する性能を維持しつつ、A100 GPUで約2倍の速度向上と約2.4倍のパラメーター削減を達成しています。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー