
Embedding APIの決定性について

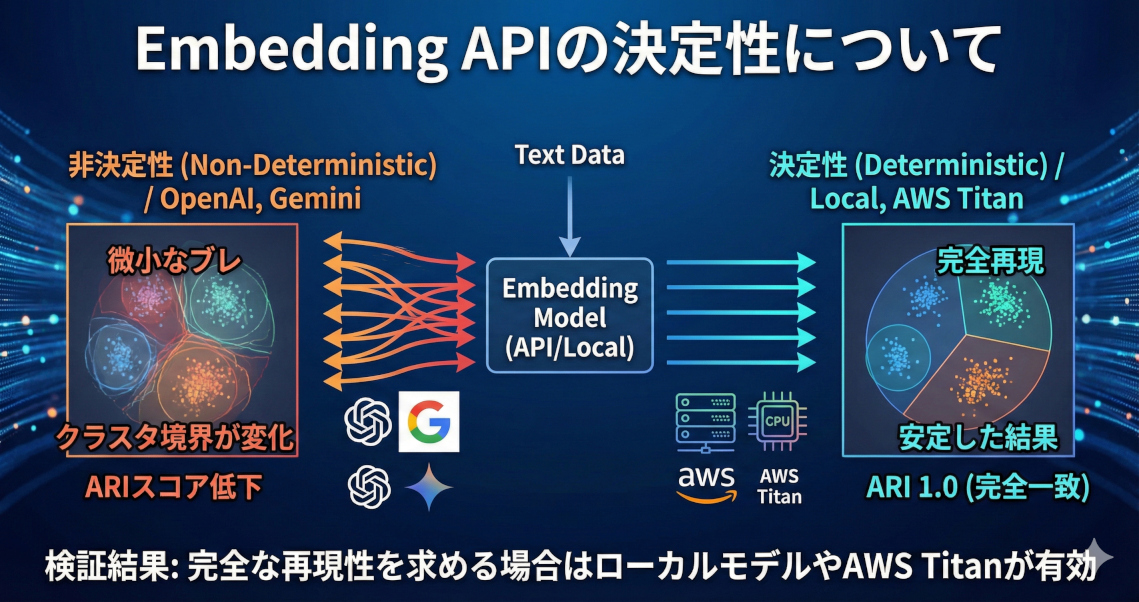
OpenAI等のEmbedding APIに潜む非決定性が、クラスタリング結果に及ぼす影響を各社モデルで比較検証しました。結果として一部のAPIは微小なベクトルのブレがクラスタ境界を大きく変えるため、完全な再現性を求める場合はローカルモデルやAWS Titanが有効であることが分かりました。
目次
はじめに
OpenAIのEmbedding APIを使用していたら、「実行するたびにクラスタリング結果が異なる」というバグに直面して、精度検証の議論が進まなかったのでどのEmbeddingモデルがどのぐらい不安定なのかを調べてみました。
そのとき行っていたのは、「Embedding取得→クラスタリング」ですが、クラスタリングアルゴリズムが決定的なのにEmbeddingの実行のたぶに変わってクラスタ境界がぶれる、その結果評価指標がぶれて2割ぐらい結果が変わるということに直面しました。そのためEmbeddingモデルの不安定さについて検証しました。
実験設定
今回はEmbeddingモデルの決定性(不安定さ)を比較するためシンプルな設定にします。
同一テキスト(SetFit/20_newsgroups, 11,014件)に対してEmbeddingを2回取得し、結果の再現性を検証します。
実験条件
- クラスタリング: AgglomerativeClustering (n_clusters=10)
- コサイン類似度: 各サンプルごとに
emb1[i]vs `emb2[i]“ を比較 - ARI (Adjusted Rand Index): クラスタリング結果の一致度 (1.0 = 完全一致)
ARIとは
Adjusted Rand Index (ARI): ランダムなラベル割り当てに対して補正済みの指標で、[-1, 1] の範囲で、1が完全一致、0が偶然レベル。最も広く使われるもの、らしい。
from sklearn.metrics import adjusted_rand_score
labels_a = [0, 0, 1, 1, 2, 2]
labels_b = [1, 1, 0, 0, 2, 2]
ari = adjusted_rand_score(labels_a, labels_b)
この結果は「1.0000(完全一致)」となります。ラベルだけの一致判定だと、「同一クラスタだが、クラスタIDが異なる」というケースを判定しきれません。ARIだとクラスタIDの変化に対して不変にになります。
AgglomerativeClusteringの決定性
AgglomerativeClusteringとは、階層クラスタリングのアルゴリズムで、Scikit-learnでは決定的な振る舞いをします。
クラスタリングの文脈で紹介されるKMeansは、初期値設定に乱数要素があり、実行するたびに結果が変わる不安定さがあります。AgglomerativeClustering自体はEmbeddingが同一なら、クラスタリング結果は決定的です。
以下のように、2つの乱数に対して2回AgglomerativeClusteringを実行すると完全一致します。
import numpy as np
from sklearn.cluster import AgglomerativeClustering
from sklearn.metrics import adjusted_rand_score
# シード固定で1000サンプル×512次元の乱数を生成
rng = np.random.default_rng(seed=42)
X = rng.standard_normal((1000, 512))
# AgglomerativeClusteringで10クラスタに割り当て(2回)
model1 = AgglomerativeClustering(n_clusters=10)
model2 = AgglomerativeClustering(n_clusters=10)
labels1 = model1.fit_predict(X)
labels2 = model2.fit_predict(X)
# ARI で一致度を確認
ari = adjusted_rand_score(labels1, labels2)
print(f"ARI: {ari:.4f}")
print(f"完全一致: {np.array_equal(labels1, labels2)}")
# ARI: 1.0000
# 完全一致: True
Embeddingモデル/APIでの比較
以下のコードのように比較します。これはローカルモデルのBAAI/bge-small-en-v1.5を使用する例で、SetFit/20_newsgroupsという英語のニュースデータを10クラスタに分類するものです。
from datasets import load_dataset
from sentence_transformers import SentenceTransformer
from sklearn.cluster import AgglomerativeClustering
from sklearn.metrics import adjusted_rand_score
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 1. データ取得
print("データ取得中...")
ds = load_dataset("SetFit/20_newsgroups", split="train")
texts = [row["text"] for row in ds if row["text"] and row["text"].strip()]
print(f"テキスト数: {len(texts)}")
# 2. Embedding推論(2回)
model = SentenceTransformer("BAAI/bge-small-en-v1.5", device="cpu")
print("Embedding 1回目...")
emb1 = model.encode(texts, show_progress_bar=True)
print("Embedding 2回目...")
emb2 = model.encode(texts, show_progress_bar=True)
# 3a. コサイン類似度(各サンプルごと)
cos_sim = np.array([
cosine_similarity(emb1[i:i+1], emb2[i:i+1])[0, 0]
for i in range(len(texts))
])
print(f"\nコサイン類似度 (emb1 vs emb2): min={cos_sim.min():.6f}, max={cos_sim.max():.6f}")
# 3b. クラスタリング比較
print("\nクラスタリング中...")
labels1 = AgglomerativeClustering(n_clusters=10).fit_predict(emb1)
labels2 = AgglomerativeClustering(n_clusters=10).fit_predict(emb2)
ari = adjusted_rand_score(labels1, labels2)
print(f"ARI: {ari:.4f}")
print(f"完全一致: {np.array_equal(labels1, labels2)}")
結果
| プロバイダ | モデル | 次元 | トークン上限 | コサイン類似度 (min) | ARI | 完全一致 |
|---|---|---|---|---|---|---|
| ローカル (CPU) | bge-small-en-v1.5 | 384 | 512 | 1.000000 | 1.0000 | Yes |
| ローカル (GPU) | bge-small-en-v1.5 | 384 | 512 | 1.000000 | 1.0000 | Yes |
| OpenAI | text-embedding-3-small | 1536 | 8,192 | 0.996406 | 0.7968 | No |
| OpenAI | text-embedding-3-large | 3072 | 8,192 | 0.994344 | 0.7846 | No |
| Google (Vertex AI) | text-embedding-005 | 768 | 2,048 | 1.000000 | 1.0000 | Yes |
| Google (Vertex AI) | text-multilingual-embedding-002 | 768 | 2,048 | 1.000000 | 1.0000 | Yes |
| Google (Vertex AI) | gemini-embedding-001 | 3072 | 2,048 | 0.999878 | 0.9862 | No |
| AWS (Bedrock) | Titan Text Embeddings V2 | 1024 | 8,192 | 1.000000 | 1.0000 | Yes |
| AWS (Bedrock) | Titan Multimodal Embeddings G1 | 1024 | 256 | 1.000000 | 1.0000 | Yes |
非決定的なモデルはOpenAI の2モデルと Google の gemini-embedding-001 の計3つでした。
OpenAIが最も不安定で、ペアワイズのコサイン類似度の最低値が 0.994〜0.996 と微少でも、クラスタリングにしたときはARI が 0.78〜0.80 と大きく崩れます。これは小さなズレが積み重なってクラスタの境界が微妙に変わってしまうため。
Vertex AIは、gemini-embedding-001がコサイン類似度 0.9999 とわずかなブレだが、クラスタリング結果には ARI 0.9862 の影響が出る。旧来のtext-embedding-005は安定。
それ以外は全て決定的で、ローカル推論(CPU/GPU)、Google 旧モデル、AWS Titan はすべて完全一致。
APIモデルはモデルの廃止がクラウドベンダーの一存で決まってしまうため、絶対に安定させたいというときはローカルのEmbeddingモデルを使用するというのは結構あるかと思います。AWSのTitanモデルは安定性では強いですね。
ただ、AWSの場合はOpenAIやGoogle CloudであったようなEmbeddingのバッチ処理を同期的に実行できないため、並列処理で工夫するか、非同期使うかちょっと取り回しが難しくなるかもしれません。また、Google Cloudでは、同期的には実行できますが、Embedding APIにつき250件/リクエストしか送れません。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー