
ML Study Jams中級編終わらせてきた


ML Study JamsというGoogle Cloudが提供している無料の学習プログラムの第二弾がオープンしています。今度は中級編が追加されており、全部終わらせてきたのでその報告と感想を書いていきたいと思います。
目次
前回の記事
QWIKLABSの使い方とかはこっち。
ML Study Jamsを全部終わらせてきたのでその感想を書いてみる
コース一覧
6個のコースラボのうちから4つ。
Auto ML
Classify Images of Clouds in the Cloud with AutoML Vision(英語)
応用
Detect Labels, Faces, and Landmarks in Images with the Cloud Vision API (英語)
Real Time Machine Learning with Google Cloud ML(英語)
Integrating Machine Learning APIs(英語)
Natural Language API を使用してテキストをカテゴリに分類する(日本語)
Awwvision: Cloud Vision API from a Kubernetes Cluster (英語)
自分は全部終わらせてきました。中級編は、機械学習単体というよりも他のCloud APIと組み合わせて、背景に機械学習があるリアルよりなアプリケーションという位置づけのものが多かったです。
必要な時間ですが、早くて3~4時間程度、ゆっくりやって6時間ぐらいだと思います。4個クリアするだけだったら1日でも十分できます。ただ、あくまでこれはQWIKLABSの使い方を知っている前提なので、そこが躓くともうちょっと時間かかると思います。初級編やればだいたいここはわかります。
個人的にはAuto ML Visionが一番おもしろかったので、応用編→Auto MLの順に書いていきます。
応用編
Detect Labels, Faces, and Landmarks in Images with the Cloud Vision API
- ラベル検出 : 訓練済みImageNetに画像食わせて出てきたクラスを確率でソートみたいなことができます(もっと性能いいだろうけど)
- ウェブ検出 : 画像を入力に入れて、関連するキーワードを受け取るというパターンです。Google画像検索に似ています。
- 顔・ランドマーク検出 : ランドマーク検出というと、自分は顔の目や鼻・口のある座標を検出するものと理解していましたが、こちらは顔の検出APIに含まれるようです。ここでのランドマーク検出とは、写真の撮られた場所を検出するという、本来の意味の「ランドマーク」です(例えば、ペトラであるとか)。画像の1/4ぐらいしか映ってなくてもペトラであるというのがわかるそうです。
他のAPIとしてラボには乗っていませんでしたが、「ロゴ検出」「セーフサーチ検出」「テキスト検出(OCR)」などがありました(リクエストを少し書き換えればできます)。自分はセーフサーチ検出を試してみました。要するに画像がエロいかどうかです。
さて窓わせやすい例を用意しました。これはインターネット上のポルノを啓発した広告ですが、輪郭だけ見ればエロい画像と誤解釈することもあります。ガバガバで有名なTumblrのポルノ判定だと縦向きだとアウトで、横向きだとセーフとのことです(きっと形状が似ているからでしょう)。

https://www.pinterest.jp/pin/393853929885789469/ より
この結果は以下のようになりました。
{
"responses": [
{
"safeSearchAnnotation": {
"adult": "UNLIKELY",
"spoof": "VERY_UNLIKELY",
"medical": "POSSIBLE",
"violence": "UNLIKELY",
"racy": "VERY_LIKELY"
}
}
]
}
どれも陰性となりました。一番可能性のあるのが医療関係(medical)というのですが、おそらく肌色の部分が多かったのでそう取れたんかもしれません。Tumblrのガバガバ判定は騙せても、さすがにGoogleのモデルは騙せませんでした。
ではより直球な例を出しましょう。

http://photozou.jp/photo/show/2802595/159485062?lang=en より
ただの大根で18禁要素はありませんが、形がエロいですね。こういう場合、どういう判定を返すのでしょうか。かなり気になります。
{
"responses": [
{
"safeSearchAnnotation": {
"adult": "UNLIKELY",
"spoof": "UNLIKELY",
"medical": "LIKELY",
"violence": "VERY_UNLIKELY",
"racy": "LIKELY"
}
}
]
}
この結果は面白いです。racy(いやらしい)のみLIKELY(該当する)ということでした。アダルト判定は陰性ですね。「GoogleのAIは、アダルトではないけどいやらしい微妙な画像を検出できるんだ」って判定みたときにゲラゲラ笑っていました。面白かったです。
Real Time Machine Learning with Google Cloud ML
これが一番めんどいです。SSHはGoogle Cloud Shellと違います。Cloud Shellでも実行できてしまいますが、SSHで実行しないと得点が反映されません。ここだけ気をつけてください。これで3回ぐらいやり直しました。
これがSSHコンソールです。別窓で表示されます。
SSHコンソールの起動は以下のようにします。2つ目以降だと起動場所が違うかもしれません。
感想としては、リアルタイムでBig Queryにフローさせていくという発想が面白かったですね。そのほかにもフローさせているものあると思いますが、パイプライン状でEnd to Endで構築できるのがCloudの独壇場ではないかなと思います。
Integrating Machine Learning APIs
機械学習のAPIをPythonのコードを使って統合的に使いましょうというもの。
特に難しいことはありませんし、Pythonのコードは用意されているので、一から書くということはありません。一部コードを書き換える必要があるというだけです(中級編はこういうケースが多いです)。Linuxのエディターを全く使ったことないと戸惑うかもしれません。
Natural Language API を使用してテキストをカテゴリに分類する
自然言語処理のAPIとBigQueryの合わせ技です。APIの結果をBig Queryに格納させて集計ということを行います。やっぱりBig Query強いなという印象を受けました。
Awwvision: Cloud Vision API from a Kubernetes Cluster
まずKubernetesってなんだ?ってレベルだったんですが、実行環境をクラスタ化できるDockerみたいなものらしいですね。
こんな感じでRedditから画像をクロールしてきて、APIでタグ付けして即可視化してくれるというプログラムです。GitHubはこちらにあります。
https://github.com/GoogleCloudPlatform/cloud-vision/tree/master/python/awwvision
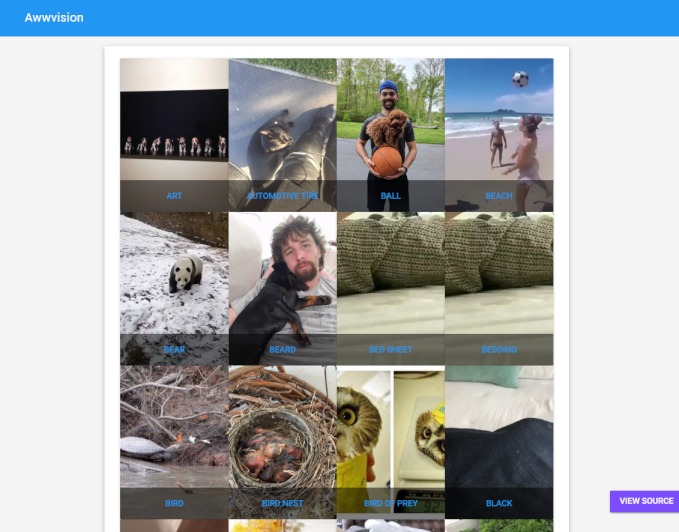
へーっという感じでした。結果がすぐ出てくるので、そこの高速化をKubernetesでやっているのではないでしょうか。
Auto ML
Classify Images of Clouds in the Cloud with AutoML Vision
自分はこれが一番面白かったです。訓練からエラー分析からスレッショルド調整まで至れり尽くせりで、まさに富豪の画像分類という感じでした。
この例としては、雲の画像分類、巻雲(cirrus)、積乱雲(cumulonimbus)、積雲(cumulus)を分類します。クラウドと雲(Cloud)を掛けたものでしょう。
まず画像データの入力のUIが結構イケてます。こんな感じでエクスプローラー状に表示されます。


タグ別に開くと、サムネイルで表示されます。感覚的にはGoogle Drive開いているのと変わりません。
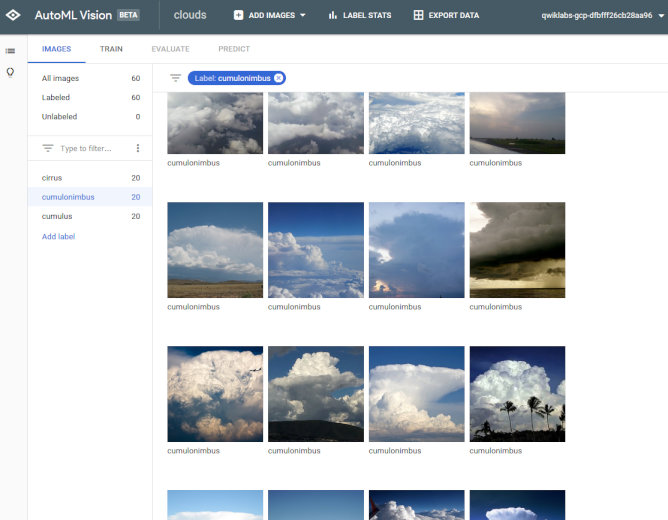
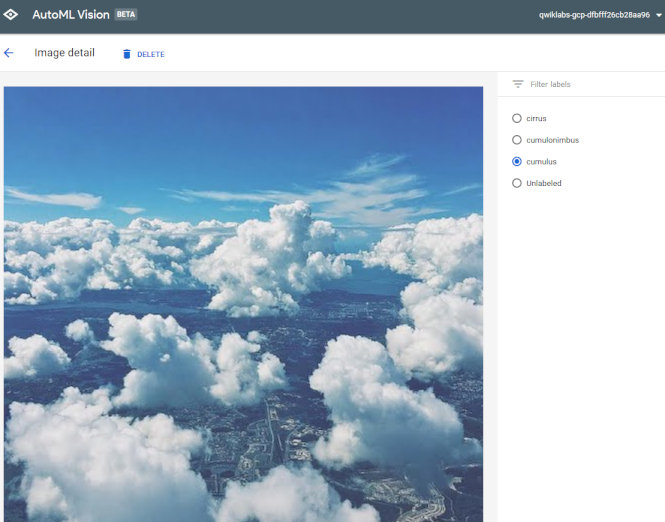
これが結構嬉しいんですが、サムネイル表示からタグをいじれるんですよね。ミスラベルした画像があればこれで調整できます。
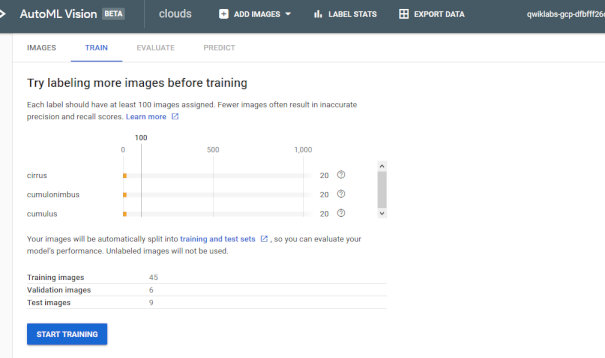
このようにクラス別の画像数表示や、どれだけをValidationやTestに使うかも調整できます。普段コード書いてコンソールでやっている画像分類は一体なんなんだという感じになってきます。
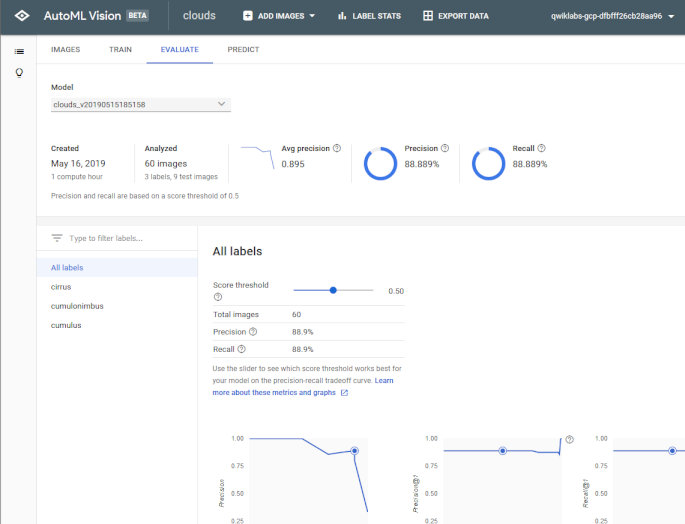
Validationの結果もこのように一目瞭然。精度だけじゃなくてPrecision-Recallや、スレッショルドによるカーブ(ROC曲線に近いもの)も表示してくれるのが嬉しいです。
一番感動したのはこれなんですけど、クラス別にエラー分析してくれるんですよね。「間違った画像はどれか」を一切コード書くことなくやってくれます。間違いはかなり重要な情報なので、ここで間違った情報をもとに、例えばWebのAPIを使って似たような画像をクロールして、訓練画像に追加すればほぼ脳死で精度が上がります。
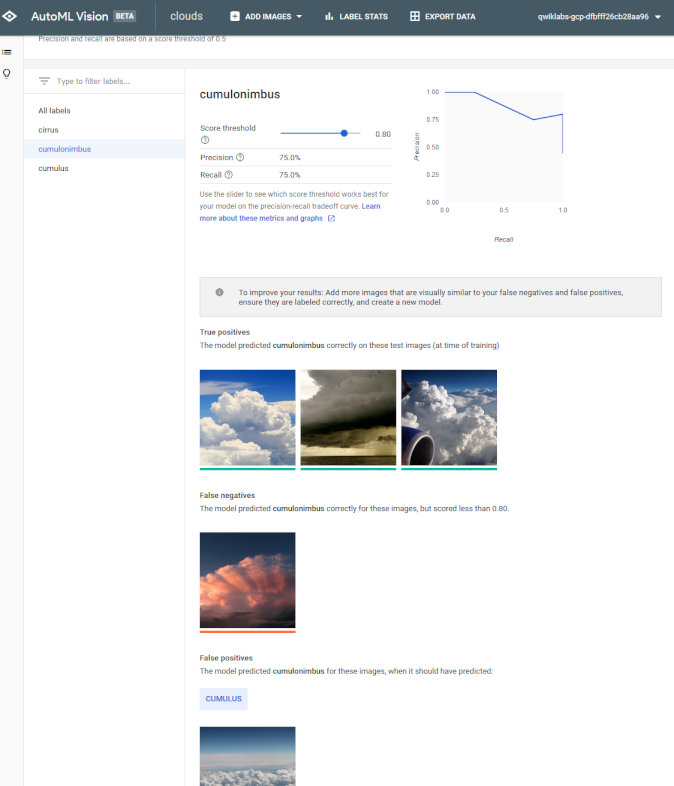
テストも簡単ですね。全部Web上でやってくれる「富豪の画像分類」です。
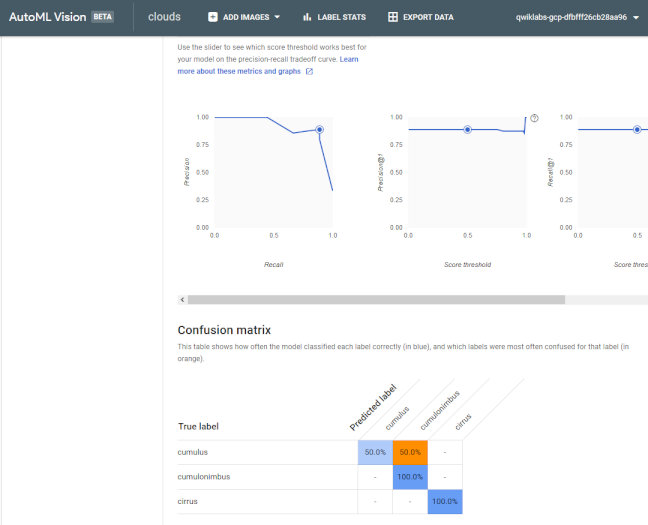
ROC曲線のほかに、混同行列も出してくれます。画像やクラスが多くなったらここを見るといいと思います。
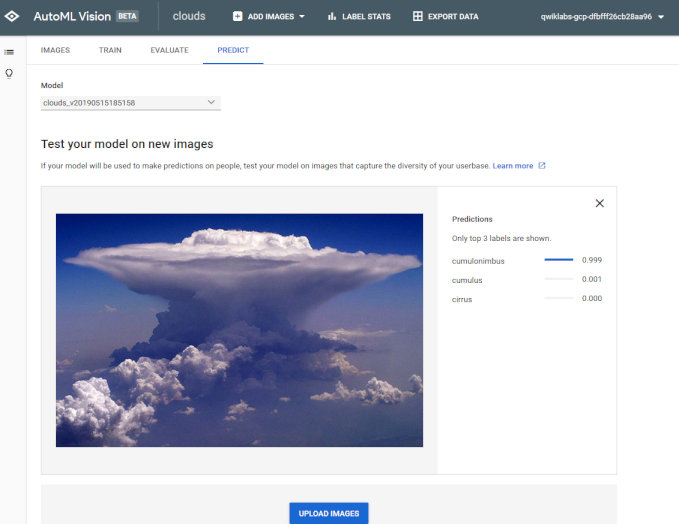
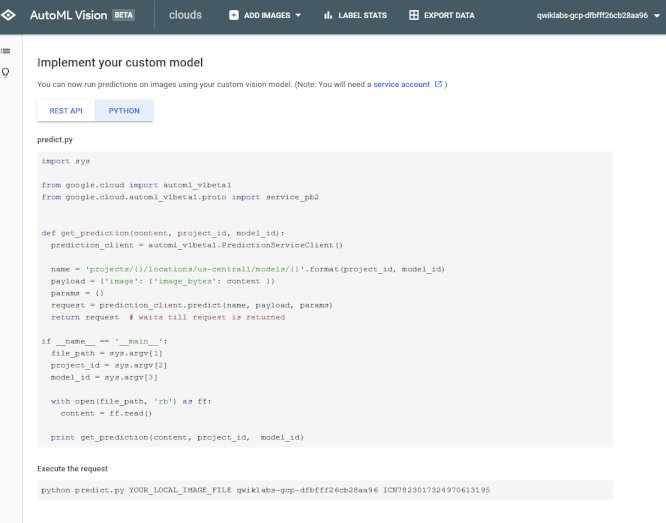
また訓練したモデルをこのようにAPIのように利用することも可能です。
ということでした。Auto ML VisionのUIはかなり衝撃的だった(コードいらないながら、痒いところにめっちゃ手が届く)ので、オフラインのGPUやColab環境からも使えたら嬉しいなと思いました。ただ、クロールとかも考えるとクラウド環境が一番使いやすいのかな。
おわりに
ということで、中級編6個全部クリアしてきました。TensorFlowのTシャツがもらえるはずです。
残り少ない時間での記事となってしまいましたが、まだ終わっていない方はぜひ頑張ってみてください。
ちなみに前回のTensorFlowのパーカーは届きました。今度使いたいと思います。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー