
ML Study Jamsを全部終わらせてきたのでその感想を書いてみる


ML Study JamsというGoogle Cloudが提供している無料の学習プログラムが期間限定でオープンしています。それを全部終わらせてきたのでその報告と感想を書いていきたいと思います。
目次
ML Study Jamsとは
Googleが提供している、Google Cloudを使った機械学習やデータ分析の初心者向け学習プログラム。すべてオンライン上で行え、参加費は無料。
ML Study Jams : Machine Learning 初心者向けトレーニングプログラム
https://events.withgoogle.com/ml-study-jams-japan-2019-01/
7つプログラムがあり、4つ以上完了させると、TensorFlowのロゴ入りTシャツかパーカーがもらえるらしい。「俺がTensorFlowerだ!!」ってどんどんイキろう。
補足しておくとこのプログラム、ほとんどTensorFlowのコードを書く要素はありません(TPUのとこで1回書くだけ)。テンソルのテの字もわからなくても全然できます。
学習時間目安
自分がやった限りです。自分でやる部分はなくて、ほとんどサンプルプログラムコピペでいけます。最後のほうは若干Linuxの基本的な操作知っている前提になっているので、ファイル操作を忘れてしまうと躓くかもしれません(でも基本的に全部1から説明しています)。
次の7つのプログラムからなります。
- BQML で分類モデルを使用して訪問者の購入を予測する(日本語)
- BigQuery ML 予測モデルによるタクシー運賃の予測(日本語)
- Cloud TPU: Qwik Start(日本語)
- Google Cloud Speech API: Qwik Start(英語)
- Cloud Natural Language API: Qwik Start(英語)
- Speech to Text Transcription with the Cloud Speech API(英語)
- Entity and Sentiment Analysis with the Natural Language API(英語)
もともと、QWIKLABSにあるプログラムの中から7個抜き出したものですね。
本来このQWIKLABSを実行するのにクレジット(ゲーセンのコインみたいなものと思ってください)が必要で、基本的に課金して手に入れるものです。プログラムごとに必要なクレジット数が異なり、例え7つのプログラムの中で最も少ない「Cloud Speech API」は1クレジットで実行できますが、最も多い「Cloud TPU」は12クレジットも必要です。
ただし、このML Study Jamsのプログラムを使うと、10個クーポンコードが送られてきて、それを入力することでクレジット数に関係なく無料で使うことができます。ただし、クーポンは一度使ったり、ラボを終了してしまうと使えなくなってしまうので注意が必要です(間違って終了して一度ハマったことあり)。
また、各ラボは制限時間があります。だいたいはゆっくりやっても間に合いますが、Speech APIだけ15分とちょっと忙しいので注意してください。
各プログラムとも、急いでやれば書いてあるとおり10分~30分ぐらいで終わります。だいたいコードコピペすればいいので。もちろん他に自分でいろいろ変えて試してみたい場合は、時間いっぱいまでやってみるのも良いでしょう。
自分はゆっくりやって4,5時間ぐらいで全プログラムできました。早い人ならもっと早くできると思います。
ハマった点
Google Cloudコンソールのログインアカウントに注意してください。ML Study Jamsのようにクーポンを使ってプレイする場合は、クーポンに応じた「google{数字_}student@qwilabs.net」というような一時的なメールアドレスを使います。この一時的なメールアドレスは使い捨てなので、Chromeのプライベートブラウジング機能を使うといいと思います。Cookieに記録しても意味ないですし。
セッションの関係で、自分のメールアドレスがCloudコンソールが対象になっていることがある(特に旧UIに切り替えた場合)、なんかエラー出たらログインしているメールアドレスに注意してみてください。
また、QWIKLABSを使うために、自分のメールアドレスでクラウドの体験版(300ドル相当のクレジット)を申し込まないように注意してください。これらのプログラムは体験版なしでも利用できます。
以下、各プログラムの簡単な説明です。一部、プログラムだけでなく自分で試したことも含みます。
(1)BQML で分類モデルを使用して訪問者の購入を予測する
BigQueryを使った分類問題です。やるのはロジスティック回帰と特徴量エンジニアリングです。
個人的には一番これが難しかった気がします。やっている機械学習はそこまで難しくないのですが、カラムの抜き出し、特徴量エンジニアリング、モデル構成まですべてBigQuery(SQL文)でEnd-to-endに構築するのが初見でした。よくあるPandasを使ったデータ分析とはやっていることは同じですが、書き方がかなり違います。
例えばこれはプログラムからですが、特徴量エンジニアリング+ロジスティック回帰を行うSQL文です(BigQuery)
#standardSQL
CREATE OR REPLACE MODEL `ecommerce.classification_model_2`
OPTIONS
(model_type='logistic_reg', labels = ['will_buy_on_return_visit']) AS
WITH all_visitor_stats AS (
SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM `data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid
)
# add in new features
SELECT * EXCEPT(unique_session_id) FROM (
SELECT
CONCAT(fullvisitorid, CAST(visitId AS STRING)) AS unique_session_id,
# labels
will_buy_on_return_visit,
MAX(CAST(h.eCommerceAction.action_type AS INT64)) AS latest_ecommerce_progress,
# behavior on the site
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site,
totals.pageviews,
# where the visitor came from
trafficSource.source,
trafficSource.medium,
channelGrouping,
# mobile or desktop
device.deviceCategory,
# geographic
IFNULL(geoNetwork.country, "") AS country
FROM `data-to-insights.ecommerce.web_analytics`,
UNNEST(hits) AS h
JOIN all_visitor_stats USING(fullvisitorid)
WHERE 1=1
# only predict for new visits
AND totals.newVisits = 1
AND date BETWEEN '20160801' AND '20170430' # train 9 months
GROUP BY
unique_session_id,
will_buy_on_return_visit,
bounces,
time_on_site,
totals.pageviews,
trafficSource.source,
trafficSource.medium,
channelGrouping,
device.deviceCategory,
country
);
この方法、確かに見通しが効きやすくて便利だなと思いました。ただ、SQL文でどうやって書くかはかなり慣れが必要な感じがします。
ちなみにここで使っているデータはGoogle Analyticsのデータらしくて、6.29 GB、970,532行のデータでした。これを特徴量設計+ロジスティック回帰走らせても3~5分ぐらいでモデルの生成が完了します。もちろん精度やAUCといった評価もSQL(BigQuery)上でできます。
また、最近BigQueryのsandboxプランというのができて、課金しなくても10GBまでのストレージが使えるようになっているらしいです。
例えばここで使っている同じデータがこちらにありますが、ここから「Compose Query」をクリックして、
#standardSQL
SELECT *
FROM `data-to-insights.ecommerce.web_analytics`
LIMIT 5;
こんな感じで簡単なSQLを入力すると課金一切なしでクエリが実行できてしまいます(BigQueryでSELECT * とやるのはあまりよろしくないようですが)。このSandboxプランを使えば多分もうちょっとBigQueryに慣れられるのかなと思います。
もし、BigQueryが一般的なPandasのデータ処理での前処理相当で使えるのなら、仮に機械学習をGoogle Cloudでやらなくてもかなり便利そうな感じはします。テーブルデータの前処理ってめちゃくちゃメモリ使って正直しんどいんですよね。これはまたあとでやってみます。
(2)BigQuery ML 予測モデルによるタクシー運賃の予測(日本語)
今度は回帰問題です。NyTaxiデータセットで、18.07GB、146112989行ありました。BigQueryの本領発揮みたいな問題ですね。
基本的には先程のと同じなのですが、RMSE(MSEのルート)という評価尺度までSQLで書いていこう(つまりなんでもSQLで書こう)というのがBigQueryのやり方です。こんなSQLになるそうです(プログラムから)。
#standardSQL
SELECT
SQRT(mean_squared_error) AS rmse
FROM
ML.EVALUATE(MODEL taxi.taxifare_model,
(
WITH params AS (
SELECT
1 AS TRAIN,
2 AS EVAL
),
daynames AS
(SELECT ['Sun', 'Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat'] AS daysofweek),
taxitrips AS (
SELECT
(tolls_amount + fare_amount) AS total_fare,
daysofweek[ORDINAL(EXTRACT(DAYOFWEEK FROM pickup_datetime))] AS dayofweek,
EXTRACT(HOUR FROM pickup_datetime) AS hourofday,
pickup_longitude AS pickuplon,
pickup_latitude AS pickuplat,
dropoff_longitude AS dropofflon,
dropoff_latitude AS dropofflat,
passenger_count AS passengers
FROM
`nyc-tlc.yellow.trips`, daynames, params
WHERE
trip_distance > 0 AND fare_amount > 0
AND MOD(ABS(FARM_FINGERPRINT(CAST(pickup_datetime AS STRING))),1000) = params.EVAL
)
SELECT *
FROM taxitrips
))
これを自分で書けというのはなかなか大変ですが、モデルの評価までSQLで書くのは「へーそうなんだー」って感じでした。
(3)Cloud TPU: Qwik Start(日本語)
個人的にこれが一番期待していたやつでした。ただここで使っているTPUはどうもv2でColabのTPUと同じっぽいです。
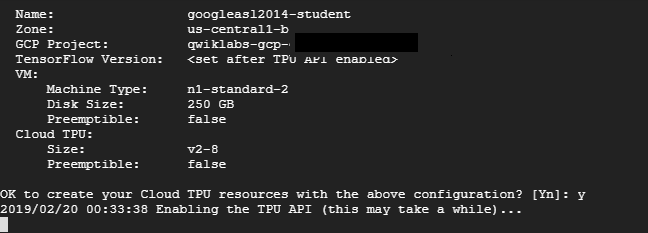
ストレージは250GBになってColabよりもかなり良いです。このプログラムはただの行列計算して終わりで、正直TPUの良さはあまり伝わってこなかったので、以前やったCIFARを走らせてみました。過去の記事。
それをやったところ、
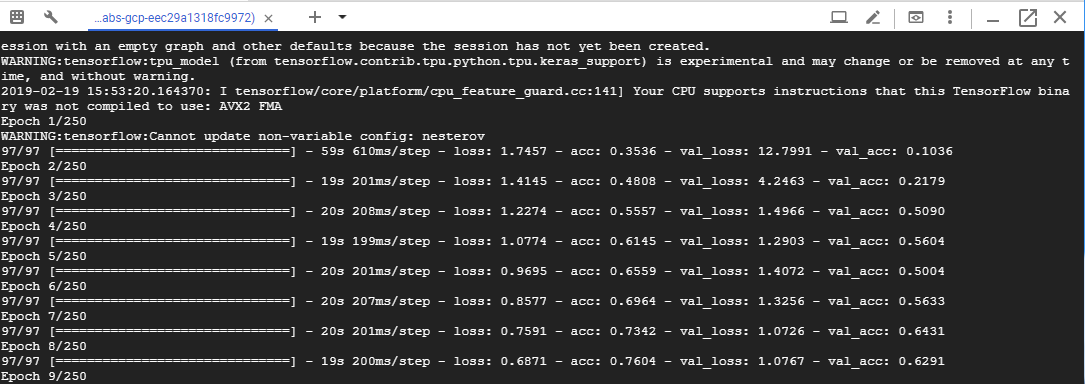
速度的にはColabとほとんど変わらない感じががが。v2-8コアだと多分こんなもんでしょう。
ちなみにこれを動かすに当たり、pipでSciPyを入れました。後のプログラムでsudo apt installしましたが、どうもsudo権限(ルート権限)は取れるっぽいです。
個人的にはTPUv3が使えるのかなと勝手に期待してただけにちょっとがっかりでした。
ちなみにColabでのTPUへのモデル変換は、
tpu_grpc_url = "grpc://"+os.environ["COLAB_TPU_ADDR"]
tpu_cluster_resolver = tf.contrib.cluster_resolver.TPUClusterResolver(tpu_grpc_url)
strategy = keras_support.TPUDistributionStrategy(tpu_cluster_resolver)
model = tf.contrib.tpu.keras_to_tpu_model(model, strategy=strategy)
としますが、Cloud TPUでは、
tpu_grpc_url = tf.contrib.cluster_resolver.TPUClusterResolver(tpu=[os.environ['TPU_NAME']]).get_master()
tpu_cluster_resolver = tf.contrib.cluster_resolver.TPUClusterResolver(tpu_grpc_url)
strategy = keras_support.TPUDistributionStrategy(tpu_cluster_resolver)
model = tf.contrib.tpu.keras_to_tpu_model(model, strategy=strategy)
とTPUClusterResolverの部分だけが変わります。
(4)Google Cloud Speech API: Qwik Start
制限時間15分と一番短いやつです。ただただ単に音声ファイルを文字起こしするものです。
認証してAPIキー発行して、Cloud Speech API発行してこんなレスポンスもらうだけ。
{
"results": [
{
"alternatives": [
{
"transcript": "how old is the Brooklyn Bridge",
"confidence": 0.98267895
}
]
}
]
}
本当は別のデータをやってみたかったのですが、音声ファイルの指定がうまくいかなかったので、Cloud Speech APIのデモページから試してみました。例のアレを1分切り出してやってみたところ次のようなレスポンスになりました。
Googleの音声認識、変態糞土方をこんだけの精度で書き起こせるのすごすぎないですか?? pic.twitter.com/DpKGU1zD5c
— ドシコリこしあん (@koshian2) 2019年2月20日
文が長かったんで表示が切れちゃいましたが。結構いい感じで書き起こせててすごいですね。元音声はバックに音楽入っていますが、音楽を取り除いて声の部分だけ書き起こせるんですね。
(5)Cloud Natural Language API: Qwik Start
自然言語処理のエンティティ分析API。プログラムに示されているコードはこんなのでした。
gcloud ml language analyze-entities --content="Michelangelo Caravaggio, Italian painter, is known for 'The Calling of Saint Matthew'."
「イタリアの画家ミケランジェロ・カラヴァッジョは、「聖マタイの呼びかけ」で知られています。」という意味の文章。これの文章を分析して、関連するWikipediaやどういうタイプの単語かを表示するというもの。
普通の文章を分析しても面白くないので、こちらで例のアレを勝手に分析してみました。
google2488382_student@cloudshell:~ (qwiklabs-gcp-fac300fc8c54824e)$ gcloud ml language analyze-enti
ties --content="試合を終えて家路へ向かうサッカー部員達。疲れからか、不幸にも黒塗りの高級車に追突し
てしまう。後輩をかばいすべての責任を負った三浦に対し、車の主、暴力団員谷岡が言い渡した示談の条件と
は…。" | ascii2uni -a U -q
{
"entities": [
{
"mentions": [
{
"text": {
"beginOffset": 18,
"content": "家路"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "家路",
"salience": 0.16189645,
"type": "OTHER"
},
{
"mentions": [
{
"text": {
"beginOffset": 0,
"content": "試合"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "試合",
"salience": 0.14451128,
"type": "EVENT"
},
{
"mentions": [
{
"text": {
"beginOffset": 36,
"content": "サッカー部員"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "サッカー部員",
"salience": 0.14451128,
"type": "PERSON"
},
{
"mentions": [
{
"text": {
"beginOffset": 60,
"content": "疲れ"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "疲れ",
"salience": 0.068055816,
"type": "OTHER"
},
{
"mentions": [
{
"text": {
"beginOffset": 102,
"content": "高級車"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "高級車",
"salience": 0.053350974,
"type": "OTHER"
},
{
"mentions": [
{
"text": {
"beginOffset": 78,
"content": "不幸"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "不幸",
"salience": 0.049625974,
"type": "OTHER"
},
{
"mentions": [
{
"text": {
"beginOffset": 90,
"content": "黒塗り"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "黒塗り",
"salience": 0.049625974,
"type": "OTHER"
},
{
"mentions": [
{
"text": {
"beginOffset": 228,
"content": "谷岡"
},
"type": "PROPER"
}
],
"metadata": {
"mid": "/m/010g_00x",
"wikipedia_url": "https://en.wikipedia.org/wiki/Shinichi_Tanioka"
},
"name": "谷岡",
"salience": 0.046632804,
"type": "PERSON"
},
{
"mentions": [
{
"text": {
"beginOffset": 186,
"content": "三浦"
},
"type": "PROPER"
}
],
"metadata": {},
"name": "三浦",
"salience": 0.044720754,
"type": "PERSON"
},
{
"mentions": [
{
"text": {
"beginOffset": 216,
"content": "暴力団員"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "暴力団員",
"salience": 0.0406281,
"type": "PERSON"
},
{
"mentions": [
{
"text": {
"beginOffset": 204,
"content": "車"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "車",
"salience": 0.038942162,
"type": "CONSUMER_GOOD"
},
{
"mentions": [
{
"text": {
"beginOffset": 252,
"content": "示談"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "示談",
"salience": 0.03772018,
"type": "OTHER"
},
{
"mentions": [
{
"text": {
"beginOffset": 261,
"content": "条件"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "条件",
"salience": 0.03772018,
"type": "OTHER"
},
{
"mentions": [
{
"text": {
"beginOffset": 138,
"content": "後輩"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "後輩",
"salience": 0.03144064,
"type": "PERSON"
},
{
"mentions": [
{
"text": {
"beginOffset": 156,
"content": "すべて"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "すべて",
"salience": 0.025308711,
"type": "OTHER"
},
{
"mentions": [
{
"text": {
"beginOffset": 168,
"content": "責任"
},
"type": "COMMON"
}
],
"metadata": {},
"name": "責任",
"salience": 0.025308711,
"type": "OTHER"
}
],
"language": "ja"
}
パラメーターの意味は次の通りです。Qwiklabのプログラムから自動翻訳。
- 実体nameとtype、人、場所、イベントなど
- metadata関連するウィキペディアのURLがあれば
- salience、そしてこの実体がテキストのどこに現れたかのインデックス。顕著性とは、テキスト全体に対するエンティティの中心性を指す[0,1]の範囲の数値です。
- mentionsこれは、さまざまな方法で言及されているものと同じものです
なんか別人のWikipediaが参照されているという風評被害。車は「CONSUMER_GOOD」なのに高級車は「OTHER」なの面白いですね。やっていることは形態素解析+名詞・形容詞あたりを抜き出す+それがどういうタイプなのか関連するWikipediaがあるのかを抜き出しているぐらいでしょうか。
(6)Speech to Text Transcription with the Cloud Speech API
基本的には(4)とほとんど同じ。Qwiklabのプログラムそのままです。このようなrequest.jsonに対して、
{
"config": {
"encoding":"FLAC",
"languageCode": "fr"
},
"audio": {
"uri":"gs://speech-language-samples/fr-sample.flac"
}
}
このようなリザルトが返ってくるだけ。やっているのは音声→文字の書き起こしです。
{
"results": [
{
"alternatives": [
{
"transcript": "maître corbeau sur un arbre perché tenait en son bec un fromage",
"confidence": 0.9710122
}
]
}
]
}
(7)Entity and Sentiment Analysis with the Natural Language API
文章単位のセンチメント分析、単語単位の実態感情分析、文章の修飾関係を見る構文解析を行います。かなり突っ込んだことができるみたいですね。
単語単位の実態感情分析は日本語はまだサポートされていなかったので、普通のセンチメント分析を他にやってみました。これは自分が勝手に入力したものです。
{
"documentSentiment": {
"magnitude": 1.1,
"score": 0
},
"language": "ja",
"sentences": [
{
"text": {
"content": "試合を終えて家路へ向かうサッカー部員達。",
"beginOffset": -1
},
"sentiment": {
"magnitude": 0.5,
"score": 0.5
}
},
{
"text": {
"content": "疲れからか、不幸にも黒塗りの高級車に追突してしまう。",
"beginOffset": -1
},
"sentiment": {
"magnitude": 0.3,
"score": -0.3
}
},
{
"text": {
"content": "後輩をかばいすべての責任を負った三浦に対し、車の主、暴力団員谷岡が言い渡した示談の条件とは…。",
"beginOffset": -1
},
"sentiment": {
"magnitude": 0.2,
"score": -0.2
}
}
]
}
この「score」というのに注目しましょう。これは文章の内容がポジティブなら1、ネガティブなら-1を返します。0はどちらでもないということですね。
試合を終えて~あでは若干ポジティブ(0.5)であったのに対して、黒塗りの高級車に衝突すると若干マイナス(-0.3)より、示談の条件とは…はも若干マイナスより(-0.2)となっているのがわかります。3つ目はかなり含みをもたせた言い方ですが、これから起こるであろう内容を一切教えていないのにその間を察し、ネガティブよりの判定をしているのではないかと思われます。ここは上手いですね。
別の文章も試してみます。最近話題のくら寿司の謝罪文です。お詫び文章なので、もっとネガティブな評価が出てくるでしょう。
"documentSentiment": {
"magnitude": 4.3,
"score": -0.6
},
"language": "ja",
"sentences": [
{
"text": {
"content": "当社が運営する無添くら寿司守口店の店内において、アルバイト従業員が不適切な行為を行った事が、インターネットへの動画掲
載により判明いたしました。",
"beginOffset": -1
},
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
},
{
"text": {
"content": "この動画により、お客様には大変不快で不安な思いをさせてしまいました事を深くお詫び申し上げます。",
"beginOffset": -1
},
"sentiment": {
"magnitude": 0.8,
"score": -0.8
}
},
{
"text": {
"content": "本当に申し訳ございません。",
"beginOffset": -1
},
"sentiment": {
"magnitude": 0.2,
"score": -0.2
}
},
{
"text": {
"content": "本件に関与した従業員に詳しい状況の確認を行った結果、撮影されていた食材は、その場で廃棄処分し提供されていない事を確認致しました。",
"beginOffset": -1
},
"sentiment": {
"magnitude": 0.5,
"score": -0.5
}
},
{
"text": {
"content": "当社では、この度の事態を重く受け止め、当事者への対応含め、法的に厳粛な対応を進めて参ります。",
"beginOffset": -1
},
"sentiment": {
"magnitude": 0.3,
"score": -0.3
}
},
{
"text": {
"content": "また改めて、従業員教育の徹底、再発防止に全力で取り組んで参ります。",
"beginOffset": -1
},
"sentiment": {
"magnitude": 0.7,
"score": -0.7
}
}
]
}
このセンチメントの推移が面白いですね。1文目は事実列挙しているだけなのに、そのネガティブさを読み取って「-0.9」という強いネガティブな評価を出しています。ここが一番ネガティブさが強いです。
次に2文目、「深くお詫び申し上げます。」は文章の単語を読み取って不快や不安やお詫びといったネガティブな単語が並んでいため、「-0.8」と強めのネガティブな評価を出しています。ただ1文目よりかは若干弱まっているのが面白いです。
次に「本当に申し訳ございません」は、一見人間的には非を認める強烈なネガティブな単語に見えますが、センチメント分析では「-0.2」とかなり弱めのネガティブな評価となっています。それよりも1文目のネガティブな事実のほうに、マイナスの評価を大きくおいているということです。
4文目の「廃棄されていることを確認した」ということも、ここは事実列挙なのですが、そこまで強くないものの「-0.5」という若干高めのマイナス評価を出しています。なんかマイナス言葉よりもマイナスと思われる事実のほうに評価をおいているような印象を受けます。
5文目の法的処置や厳粛な対応といった表現も、人間的にはネガティブなんじゃないの?と思うかも知れませんが、「-0.3」とそれほど強いネガティブさを出していません。
最後の文章、再発防止に向けた努力は、人間的にはポジティブよりになってもいい文章かと思いますが、これは「-0.7」とかなり高めのネガティブスコアを出しています。再発防止は人間はよくとっても、機械はあまり良くは取らないよということなのでしょうか。ここは不思議ですね。
感想
全部終わってみて、結構楽しかったです。コードは全部載っていてコピペでできるし、普段はただでは使わせてくれないGoogle Cloudを部分的に無料で使えるので、この機にぜひ使ってみてはいかがでしょうか。2/20時点でまだ申し込みは受け付けています。TensorFlowのパーカーほしいんだけど、はやくこないかな。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー