
Amazon Aurora Activity Streamを試す
Posted On 2025-01-23


AuroraのActivity StreamをKinesisとFirehose経由でS3に保存する仕組みをTerraformで構築しました。Aurora Serverless非対応やKMSキーの設定などの制約があるため、Provisionedインスタンスを活用して実装しています。
目次
はじめに
- SAPを勉強して出てきた「Aurora Activity Stream」を試してみました
- Aurora Activity Streamはデータベースに対して書き込みなどが走ると、それをベースにイベントを飛ばせるというもの
- 今回は、Activity StreamsをKinesis Data Streams→Kinesis Data Firehorseと経由し、S3にイベントをロギングするというものを作る
アーキテクチャー図
作るもののアーキテクチャー図は以下の通り
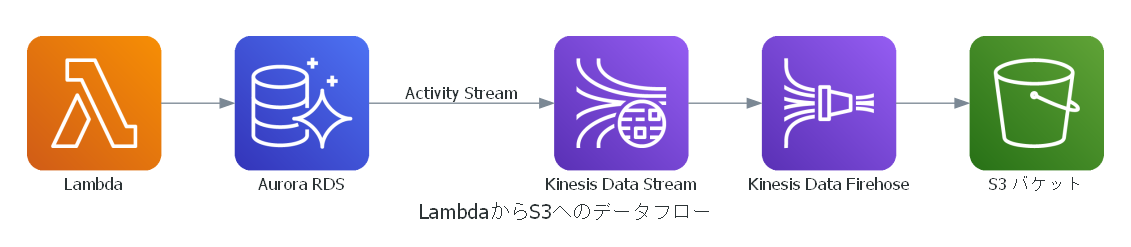
注意点
やってみてわかった点。アクティビティーストリームは以下の制約がある
- Aurora Searverlessは使えない。
db.r7g.largeなどの普通のプロビジョンドインスタンスを使う必要がある - プロビジョンしていてもインスタンスタイプに制約があり、最も安いdb.t4g.mediumは非対応。一番安いと思われるのが
db.r7g.largeで、東京リージョンで0.333USD / hrで、まあまあ値段が張る - KMSのカスタマーマネージドキーで暗号化する必要がある。これはアクティビティーストリーム、RDSの両方に対してそう
実際に動かしてみる
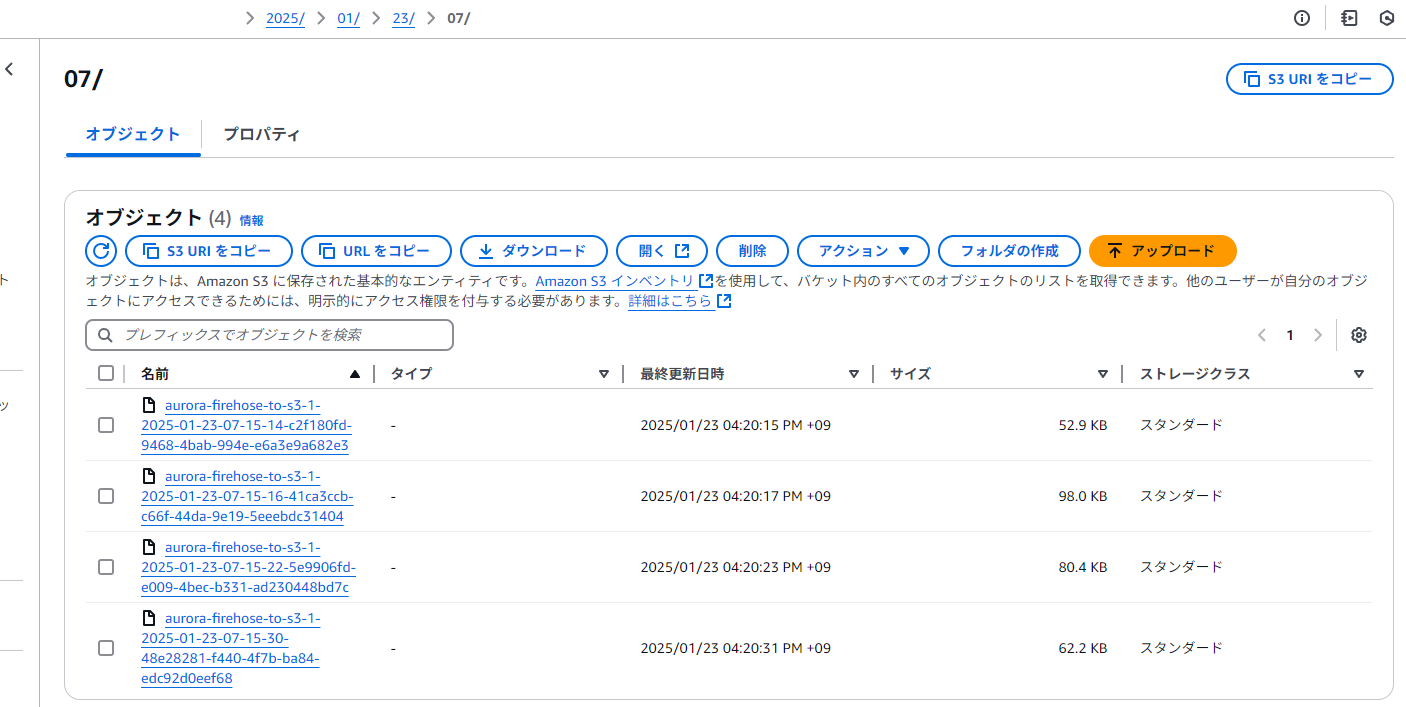
LambdaからDBに対してレコードを追加してみると、数分すると以下のようなオブジェクトがS3に生成されている
中身は以下のようになっている。KMSで暗号化されていてすぐには読める形ではない。
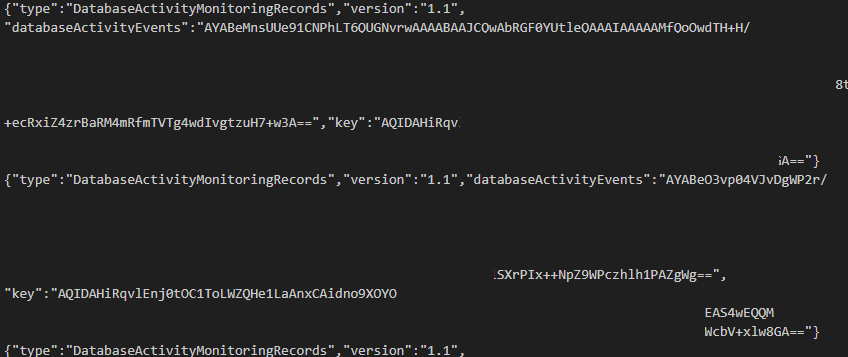
スキーマーは以下の形
{
"type": "DatabaseActivityMonitoringRecords",
"version": "1.1",
"databaseActivityEvents": "AYABeCtLR8eVgfLZq/5q...",
"key": "MASKED"
}
ディレクトリ構造
./
├── aurora.tf
├── lambda.tf
├── main.tf
├── aurora_lambda_src/
│ ├── initialize_database.py
│ └── insert_row.py
└── lambda_layers/
└── postgres.zip
aurora_lambda_srcとlambda_layersはAurora Searverlessのゼロキャパシティを試すの使いまわし
aurora.tf
Activity Streamのコードが含まれる
# 与えられているサブネット ID を使って DB Subnet Group を作成
resource "aws_db_subnet_group" "aurora_subnet_group" {
name = "aurora-subnet-group"
subnet_ids = var.private_subnet_ids
description = "Subnet group for Aurora Serverless"
}
data "aws_subnet" "private_subnets" {
for_each = toset(var.private_subnet_ids)
id = each.value # ここに対象のサブネットIDを指定
}
# Aurora のマスターパスワードを Secrets Manager に格納するための準備(ランダム生成 → Secret → Secret Version)
resource "random_password" "aurora_password" {
length = 16
special = true
override_special = "!#$%&*()-_=+[]{}<>:?" # 利用したい特殊文字の制限があれば適宜修正
}
resource "aws_secretsmanager_secret" "aurora_password" {
name = "aurora-master-password"
description = "Master password for Aurora PostgreSQL stored in Secrets Manager"
# Terraform destroy 時に即削除されるようにする設定
recovery_window_in_days = 0
}
resource "aws_secretsmanager_secret_version" "aurora_password_version" {
secret_id = aws_secretsmanager_secret.aurora_password.id
secret_string = random_password.aurora_password.result
}
# セキュリティグループ (例: ポート 5432 を開放)
resource "aws_security_group" "aurora_sg" {
name = "aurora-postgres-sg"
description = "Allow inbound PostgreSQL traffic"
vpc_id = var.vpc_id
ingress {
description = "PostgreSQL port"
from_port = 5432
to_port = 5432
protocol = "tcp"
cidr_blocks = [for key, value in data.aws_subnet.private_subnets : value.cidr_block]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
# Aurora (プロビジョンド) クラスターの作成
resource "aws_rds_cluster" "aurora_pgvector" {
cluster_identifier = "my-aurora-pgvector-cluster"
engine = "aurora-postgresql"
engine_version = "16.6" # 利用可能な最新バージョンに合わせる
master_username = "postgres"
master_password = aws_secretsmanager_secret_version.aurora_password_version.secret_string
db_subnet_group_name = aws_db_subnet_group.aurora_subnet_group.name
vpc_security_group_ids = [
aws_security_group.aurora_sg.id
]
# デフォルトキーではなく、ユーザー管理の KMS キーを使う
kms_key_id = aws_kms_key.default.arn
storage_encrypted = true
deletion_protection = false
# テストや開発用で最終スナップショットを取らずに削除する場合
skip_final_snapshot = true
}
# Aurora (プロビジョンド) クラスターのインスタンスを作成(サーバーレスはActivity Streaming非対応)
resource "aws_rds_cluster_instance" "aurora_pgvector_instance" {
identifier = "my-aurora-pgvector-instance"
cluster_identifier = aws_rds_cluster.aurora_pgvector.id
engine = aws_rds_cluster.aurora_pgvector.engine
# プロビジョンド用インスタンスクラス(t4g系だと使えない)
instance_class = "db.r7g.large"
db_subnet_group_name = aws_db_subnet_group.aurora_subnet_group.name
}
resource "aws_kms_key" "default" {
description = "AWS KMS Key to encrypt Database Activity Stream"
deletion_window_in_days = 7
}
###
# Activity Streaming
###
# ------------------------------------------------------------------
# Activity Stream (Aurora が自動で作成する Kinesis Data Stream を利用)
# ------------------------------------------------------------------
resource "aws_rds_cluster_activity_stream" "default" {
resource_arn = aws_rds_cluster.aurora_pgvector.arn
mode = "sync"
kms_key_id = aws_kms_key.default.key_id
# Aurora クラスターインスタンス作成後に有効化するよう依存関係を追加
depends_on = [aws_rds_cluster_instance.aurora_pgvector_instance]
}
data "aws_region" "current" {}
data "aws_caller_identity" "current" { }
locals {
kinesis_arn = "arn:aws:kinesis:${data.aws_region.current.name}:${data.aws_caller_identity.current.account_id}:stream/${aws_rds_cluster_activity_stream.default.kinesis_stream_name}"
}
# S3バケットの作成
resource "aws_s3_bucket" "aurora_firehose_bucket" {
bucket = var.s3_bucket_name
force_destroy = true
}
# IAM ロール:FirehoseがKinesisとS3にアクセスするため
resource "aws_iam_role" "firehose_role" {
name = "firehose_delivery_role"
assume_role_policy = jsonencode({
Version = "2012-10-17",
Statement = [{
Action = "sts:AssumeRole",
Effect = "Allow",
Principal = {
Service = "firehose.amazonaws.com"
}
}]
})
}
# IAM ポリシー:FirehoseがKinesisとS3にアクセスする権限
resource "aws_iam_role_policy" "firehose_policy" {
name = "firehose_policy"
role = aws_iam_role.firehose_role.id
policy = jsonencode({
Version = "2012-10-17",
Statement = [
{
Effect = "Allow",
Action = [
"kinesis:DescribeStream",
"kinesis:GetShardIterator",
"kinesis:GetRecords",
"kinesis:ListStreams"
],
# Aurora Activity Stream が作る Kinesis Data Stream を利用
Resource = local.kinesis_arn
},
{
Effect = "Allow",
Action = [
"s3:PutObject",
"s3:PutObjectAcl"
],
Resource = "${aws_s3_bucket.aurora_firehose_bucket.arn}/*"
},
{
Effect = "Allow",
Action = [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
Resource = "*"
}
]
})
}
# Firehose の入力元として Aurora Activity Stream の Kinesis を指定
resource "aws_kinesis_firehose_delivery_stream" "firehose_to_s3" {
name = "aurora-firehose-to-s3"
destination = "extended_s3"
kinesis_source_configuration {
# Activity Stream リソースが生成する Kinesis ARN を利用
kinesis_stream_arn = local.kinesis_arn
role_arn = aws_iam_role.firehose_role.arn
}
extended_s3_configuration {
bucket_arn = aws_s3_bucket.aurora_firehose_bucket.arn
role_arn = aws_iam_role.firehose_role.arn
compression_format = "UNCOMPRESSED"
}
}
lambda.tf
# IAMロール作成
resource "aws_iam_role" "lambda_role" {
name = "aurora_lambda_role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "lambda.amazonaws.com"
}
}]
})
}
# IAMポリシー:LambdaがSecrets ManagerおよびAuroraにアクセスするための権限を付与
resource "aws_iam_role_policy" "lambda_policy" {
name = "aurora_lambda_policy"
role = aws_iam_role.lambda_role.id
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Effect = "Allow",
Action = [
"secretsmanager:GetSecretValue",
"secretsmanager:DescribeSecret"
],
Resource = aws_secretsmanager_secret.aurora_password.arn
}
]
})
}
# VPCアクセス用マネージドポリシーのアタッチ
resource "aws_iam_role_policy_attachment" "attach_vpc_policy" {
role = aws_iam_role.lambda_role.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaVPCAccessExecutionRole"
}
# Lambda Layer を作成
resource "aws_lambda_layer_version" "postgres" {
filename = "lambda_layers/postgres.zip"
layer_name = "postgres_layer"
compatible_runtimes = ["python3.12"]
source_code_hash = filebase64sha256("lambda_layers/postgres.zip")
}
data "archive_file" "lambda_zip" {
type = "zip"
source_dir = "${path.module}/aurora_lambda_src"
output_path = ".cache/aurora_lambda.zip"
}
locals {
lambda_functions = {
aurora_insert_function = {
handler = "insert_row.lambda_handler"
host = aws_rds_cluster.aurora_pgvector.endpoint
aurora_type = "hot"
}
aurora_initialize_function = {
handler = "initialize_database.lambda_handler"
host = aws_rds_cluster.aurora_pgvector.endpoint
aurora_type = "hot"
}
}
experiment_id = "initialize test"
}
# Lambda関数の作成
resource "aws_lambda_function" "aurora_lambda" {
for_each = local.lambda_functions
function_name = each.key
role = aws_iam_role.lambda_role.arn
handler = each.value.handler
runtime = "python3.12"
filename = data.archive_file.lambda_zip.output_path
source_code_hash = filebase64sha256(data.archive_file.lambda_zip.output_path)
layers = [aws_lambda_layer_version.postgres.arn]
environment {
variables = {
AURORA_HOST = each.value.host
AURORA_PORT = "5432"
AURORA_DB_NAME = "postgres"
AURORA_USER = "postgres"
AURORA_TYPE = each.value.aurora_type
SECRET_NAME = "aurora-master-password"
REGION = "ap-northeast-1"
EXPERIMENT_ID = local.experiment_id
}
}
vpc_config {
subnet_ids = var.private_subnet_ids
security_group_ids = [aws_security_group.aurora_sg.id]
}
# タイムアウトやメモリなどの設定は必要に応じて調整
timeout = 60
memory_size = 512
}
main.tf
# 外部から与えられるプライベートサブネットのID
variable "private_subnet_ids" {
type = list(string)
description = "Aurora Serverless を配置するサブネットのリスト"
# 2つ以上にまたがって定義する必要あり
}
variable "vpc_id" {
type = string
description = "Aurora を作成する VPC の ID"
}
variable "s3_bucket_name" {
type = string
}
所感
- インスタンスタイプや暗号化など結構ハマるところあった
- DynamoDB Streamsみたいな機能あるんだと知れたのがよかったかな
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー