
Google ColabのTPUでResNetのベンチマークを取ってみた


Google ColaboratoryでTPUが使えるようになりましたが、さっそくどのぐらい速いのかベンチマークを取ってみました。以前やったResNetのベンチマークを使います。
環境:Google Colab(TPU)、TensorFlow:1.11.0-rc2、Keras:2.1.6
コード:https://github.com/koshian2/ResNet-MultipleFramework
結果
GPUの結果は以前測定したものです。CIFAR-10の分類です。各1回のみ試しています。
| Framework | N | # Layers | MinTestError | s / epoch |
|---|---|---|---|---|
| TF-Keras(TPU) | 3 | 20 | 0.154 | 19.666 |
| TF-Keras(GPU) | 3 | 20 | 0.097 | 51.817 |
| PyTorch(GPU) | 3 | 20 | 0.099 | 26.602 |
| TF-Keras(TPU) | 5 | 32 | 0.153 | 19.818 |
| TF-Keras(GPU) | 5 | 32 | 0.086 | 75.746 |
| PyTorch(GPU) | 5 | 32 | 0.089 | 40.670 |
| TF-Keras(TPU) | 7 | 44 | 0.167 | 19.969 |
| TF-Keras(GPU) | 7 | 44 | 0.086 | 96.946 |
| PyTorch(GPU) | 7 | 44 | 0.089 | 55.465 |
| TF-Keras(TPU) | 9 | 56 | 0.133 | 19.932 |
| TF-Keras(GPU) | 9 | 56 | 0.082 | 119.361 |
| PyTorch(GPU) | 9 | 56 | 0.090 | 70.834 |
TPUを使った場合は精度がかなり落ちていますが、これは精度向上に寄与していたLearningRateScheduler(keras.callbacks)がTPUでは機能していないためです。Callback内で学習率変化させても効果がなかったので、TensorFlowの低レベルAPIでどうにかするか、バグ直されるまで待つしかなかと思います。TPU(上)とGPU(下)のエラーの推移です。どちらもKerasの例です。
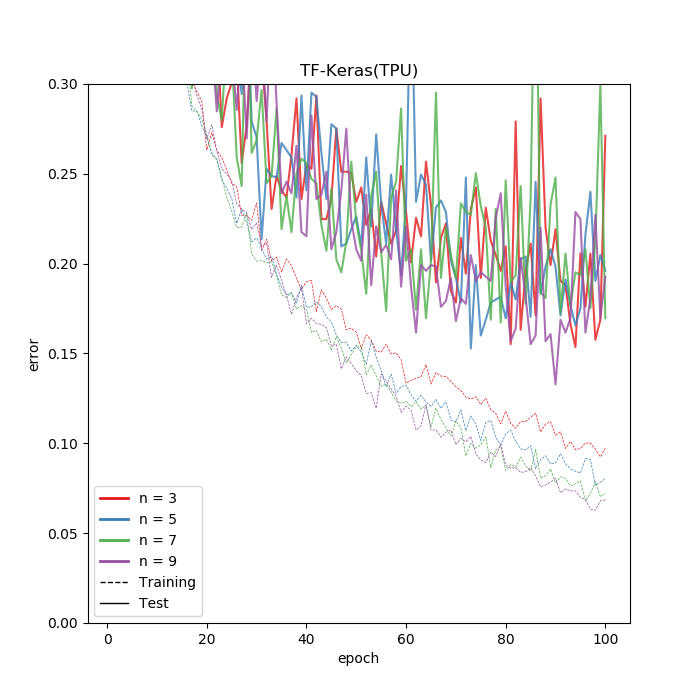
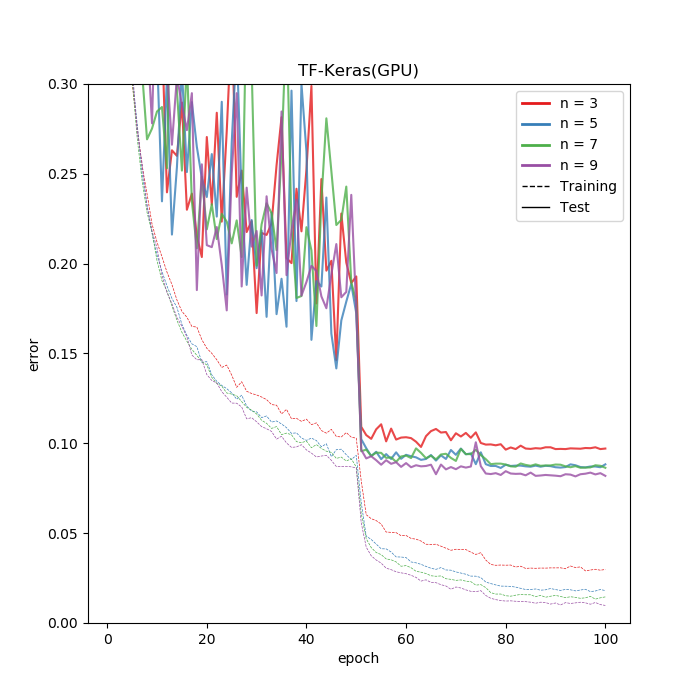
リアルなデータで学習率調整することはあまりないのですが、CIFARの場合は学習率調整が重要なのでここだけは注意が必要です。
ちなみに速度はむちゃくちゃ速いです。GPUでは層を深くすればするほど遅くなっている自然な結果となっているのに対し、TPUではほぼ定数時間で処理できています。おそらく層が浅い場合は、TPUでは何か別の要素がボトルネックとなっていて、本体の計算性能が出せていないともとらえることができます。どのNからTPUの計算時間が増えだすのか、Nをどんどん深くしてみましたが、N=40を越えるとコンパイルがハングアップしてしまったため確認はできませんでした。

この時間は2エポック目以降の1エポックあたりの時間の中央値を取ったものです。
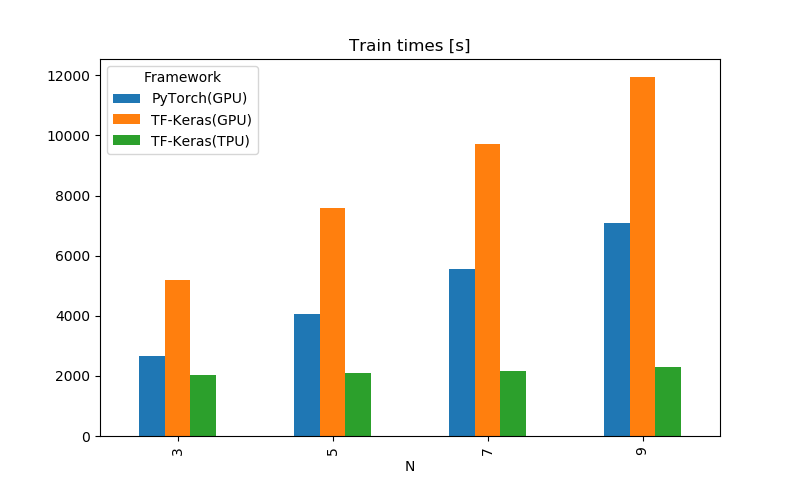
N=9の結果を見ると、少なくともTPU版のKerasは、GPU版のKerasの6倍、GPUの間では最速だったPyTorchの3.5倍速いということができます。LearningRateSchedulerのバグはあるもののなかなか有望ですね。
ちなみに全エポックの合計時間で見ると以下のようになります。だいたい変わらないですね。
ちなみにTPU版のKerasの使い方はこちらをご覧ください。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー