
論文まとめ:COLE: A Hierarchical Generation Framework for Graphic Design
Posted On 2024-02-15


* タイトル:COLE: A Hierarchical Generation Framework for Graphic Design
* 著者:Peidong Jia, Chenxuan Li, Zeyu Liu, Yichao Shen, Xingru Chen, Yuhui Yuan, Yinglin Zheng, Dong Chen, Ji Li, Xiaodong Xie, Shanghang Zhang, Baining Guo(Microsoft Research Asia、北京大学)
* 論文URL:https://arxiv.org/abs/2311.16974
* プロジェクトページ:https://graphic-design-generation.github.io/
* カンファ:CVPR 2024?
目次
ざっくりいうと
- ユーザーの指示から、編集可能で階層的なグラフィックデザイン画像を生成する新システム「COLE」の研究
- ユーザの意図を理解し、設計に関連する重要なデータをJSON形式で保持、これを基に視覚要素の生成とタイポグラフィ属性を作成
- 生成したデザインに対する自己評価によるフィードバックを経て最終的なデザイン品質を向上させる
はじめに
- 本システム(COLE)は、設計を考慮したテキストや画像生成のために特別に訓練された各種のモデルからなる
- 複数の微調整されたLLM
- マルチモーダルLMM
- 拡散モデル(DM)
- DALLE-3の欠点
- テキストの誤認識。これをセグメンテーション→インペインティングであるが、生成物が本質的に編集不可能であること
- スケーラブルで高品質なグラフィック生成システムに求められること
- 正確で高品質なタイポグラフィ情報を生成
- 柔軟な編集空間を提供
- これにより、ユーザーは必要に応じて人間の専門知識を統合しさらに出力を洗練させられる
- 本研究の目的:ユーザの意図するプロンプトから高品質のグラフィックデザイン画像を生成。Instruction→これらの要件を満たすグラフィックデザイン画像の生成
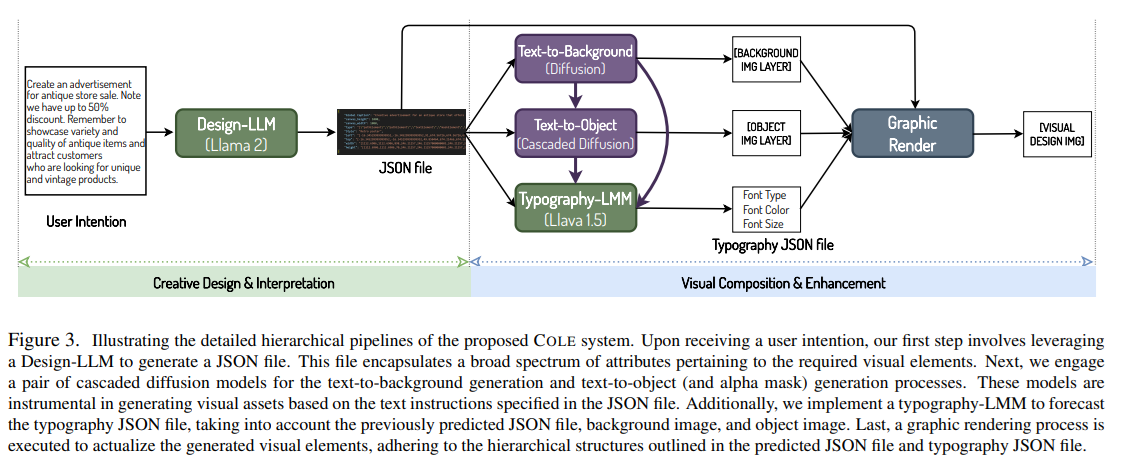
- グラフィックデザイン画像生成の複雑なプロセスを、階層的な生成プロセスに分解
- 1個目のコンポーネント:Instruction→JSON
- 創造的なデザインと解釈に焦点を当て、基本的に意図を理解
- Llama2-13Bを10万データのintention-JSONペアでファインチューニング(LLM)
- JSONには、背景キャプション、オブジェクトキャプション、テキストの詳細など設計に関連する重要なデータが含まれる
- オブジェクトの位置決めのオプションもある
- 2個目のコンポーネント:画像生成+レンダリング
- 視覚的要素の生成とタイポグラフィ属性の作成
- DeepFloyd/IFのようなカスケードの拡散モデルをファインチューニング(画像生成)
- 多様な視覚的要素を生成すると同時に、背景や物体画像レイヤーとの調和も図る
- LLaVA-1.5 13Bを用い、タイポグラフィのJSONファイルを予測(マルチモーダルLLM)
- 次に、グラフィックレンダラーは、予測されたJSONファイルのレイアウトに従って、これらの要素をレンダリング
- 3個目のコンポーネント:フィードバック
- 全体的な設計品質を向上するための評価者
- GPT-4Vを採用
- テキストボックスの位置やサイズを必要に応じて調整するなど、JSONファイルの必要な絞り込み
- 1個目のコンポーネント:Instruction→JSON
関連研究
- デザインイメージの生成
- FlexDM [16,43]は要素予測のために統一されたTransformerアーキテクチャを活用
- UI-Diffuser[35]ではモバイルUI生成
- 大半の研究は他の全ての情報があると仮定して、レイアウト生成が焦点
- 本研究:明確なユーザー意図の記述から、すべてのデザイン生成タスクを実行できる自律的かつ包括的なシステムを開発という主張。今までの研究とはやや毛色が違う?
提案手法
COLEフレームワークの概要
タスクの分解
- intention-to-JSON生成(Text→JSON)
- text-to-背景画像生成(Text→Image)
- text-to-物体画像・αマスク生成(Text→Image+Mask)
- タイポグラフィ属性生成(Text→Text/JSON)
intention-to-JSON
User IntentionをInputとして、JSONを予測

text-to-背景画像
- SVG生成したい
- 現在はテキスト→強力なSVGの生成モデルがない
- 高品質なテキストとSVGのペアデータセットが少ない
- Text→背景の拡散モデルを学習し、すべてSVGファイルと装飾要素からなる首尾一貫した背景画像の生成
- SVG生成部分がかなり大事なのにここはどうやったか記述なかった
- DeepFloyd IF(Imagenベース)をファインチューニング
- 10万以下のキャプション、背景画像のペア
text-to-物体画像+αマスクの生成
- Instruct Pix2Pixベースで、αマスクの生成を行う
- 「ベース画像+0のマスク」→アルファマスクを予測しブレンド
- 背景の3チャンネル+物体の3チャンネル+αマスクの7チャンネルの予測
- オブジェクトの合理的な配置のためには極めて重要
- 5.5万のキャプションとオブジェクトの画像ペアから、DeepFloyd IFベースのInstruct Pix2Pixを訓練
- 正確なアルファマスクを予測を保証することは複雑な課題
タイポグラフィLLM
- タイポグラフィ:タイポグラフィとは、テキストのスタイルと外観のこと
- フォントのスタイル、外観、構造の設計を包含し、特定の感情を引き出して特定のメッセージを伝えることを目的
- 既存の研究Tanveerら[32]、Iluzら[14]、Heら[10]などは、拡散モデルを用いて新しい文字レベル・単語レベルの芸術的タイポグラフィを生成
- この研究はLLMの活用
- タイポグラフィをJSONで予測
- フォントの種類の選択
- 階層の配置
- リーディングの調整(線の間隔)
- トラッキング(文字の間隔)
- カーネル(特定の文字間のスペース)
- LLaVA1.5-13Bを10万Tripletでファインチューニング
- 背景や物体の画像、タイポグラフィ情報からなる複数の情報
- 16の属性を予測

レンダリング
- OSSの2DグラフィックライブラリであるSkiaをベース
- https://skia.org/about/
- Skia-python: Pythonのための2Dグラフィックスライブラリ
- CanvasVAEの公式実装に従ったレンダリング品質が大きな改善の可能性
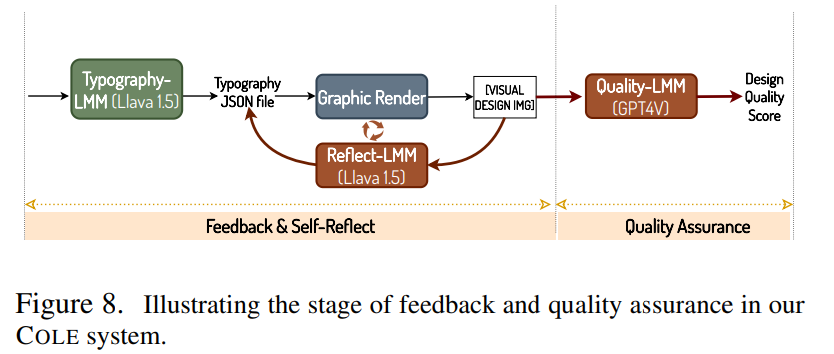
フィードバックと自己反映
- 最終的なクォリティ評価はGPT-4V
- タイポグラフィJSONに自己評価でフィードバックを繰り返すために、LLaVA1.5ベースを加える
- LLaVAの訓練、ノイズの多いJSONでファインチューニング
- Ground TruthのタイポグラフィJSONに対して、ランダムな位置にシフトノイズを追加することでノイジーな訓練データを作成
- 私の注釈:VLMの訓練だが、発想は拡散モデル
評価
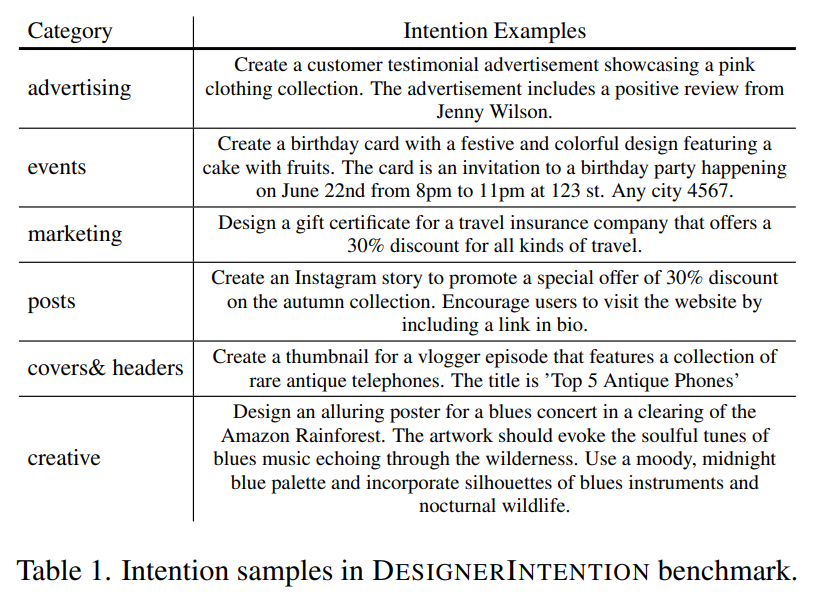
intention。6個のカテゴリ別のプロンプトで、GPT-4Vが評価
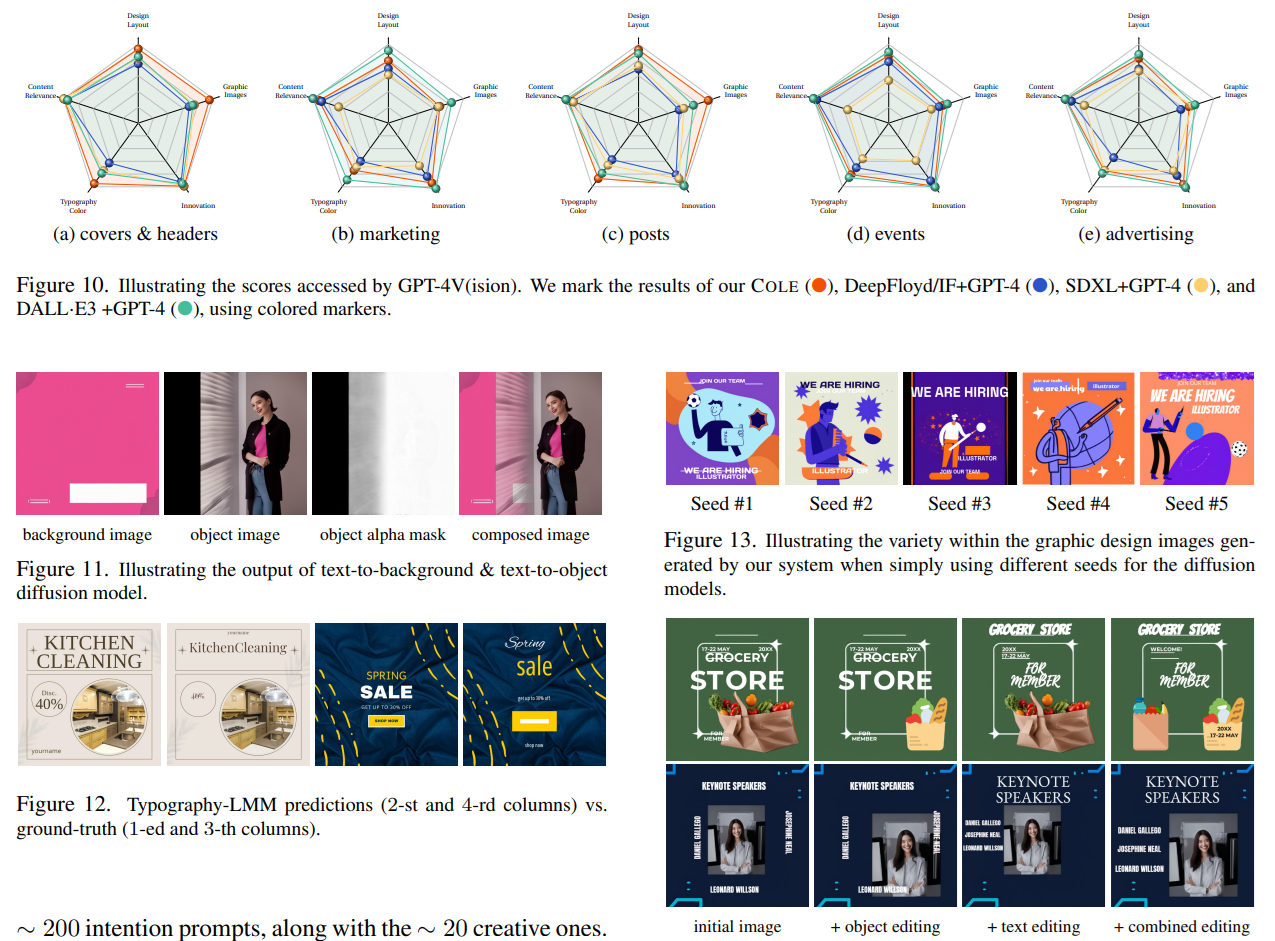
私の注釈:DALLE-3+GPT-4がCOLEに肉薄しているが、DALLE-3の訓練にGPT-4Vを使っているのでややリークに注意は必要。
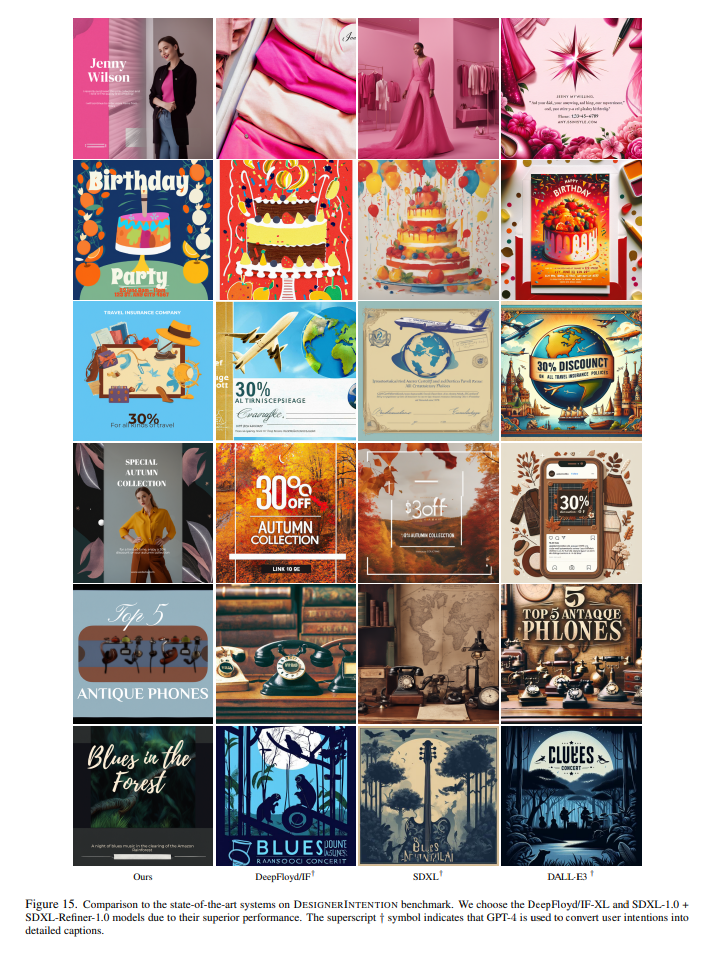
- Design LLMの部分の評価
- Sentence-BERTによるGround Truthとの意味的な類似度を計算
- Text-to-背景/物体の生成
- ???
- タイポグラフィLLM/フィードバックLLM(VLM)
- Ground Truth画像を用いた予測結果を条件として計算
- GPT-4Vによるタイポグラフィスコアリング
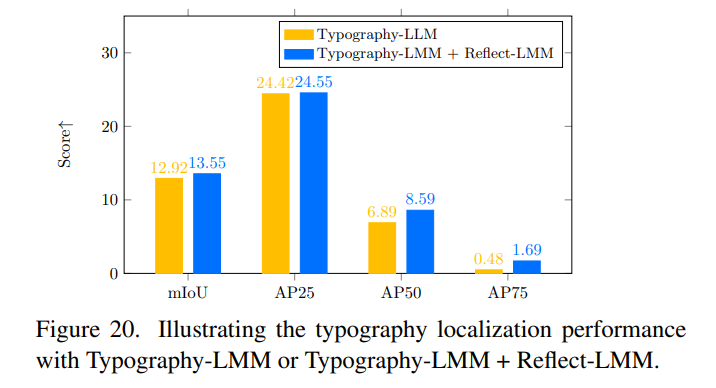
- mIoU、AP25、AP50といった定位精度
Suppply
Intention Generation Prompt(GPT-3.5)

Ground Truthに対するmIoUやAPの評価
GPT-4Vに対するプロンプト

プロのグラフィックデザイナーによる主観評価。この研究、グラフィックデザイナーによる監修がかなりはいっているらしい。

所感
- グラフィックデザインの生成研究ってレイアウト生成がかなり多かった記憶があるので、これは斬新。考え方がかなり参考になる
- Instruct Pix2pixをブレンドに使うのはなるほど感
- VLMやLLM、拡散モデルを湯水のように使っているのはMS感ある
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー