
論文メモ:Concurrent Spatial and Channel ‘Squeeze & Excitation’ in Fully Convolutional Networks


Squeeze and Excitationの派生形であるsc-SEを提唱している論文。Squeeze & Excitationの派生形と構成がわかりやすくまとまっており、効果が検証されています。
目次
元論文
Abhijit Guha Roy, Nassir Navab, Christian Wachinger.Concurrent Spatial and Channel Squeeze & Excitation in Fully Convolutional Networks. MICCAI 2018
https://arxiv.org/abs/1803.02579
Squeeze & Excitationの派生形
Squeeze & ExcitationはSelf-attentionの文脈として書かれることがあります。例えば、CVPR2019で発表された超解像のSoTAであるSANは、2次のモーメントについてのSqueeze & Excitationを行っているのが大きな特徴ですが、これをAttentionだと言っています。
SENetをAttentionだというかわりに、例えばSelf-attention GANのようなNLP出身のSelf-attentionは何というのかというと、今はNon-Localと言っています。
若干脱線してしまいましたが、この論文にかかれているSENetの派生形のまとめです。
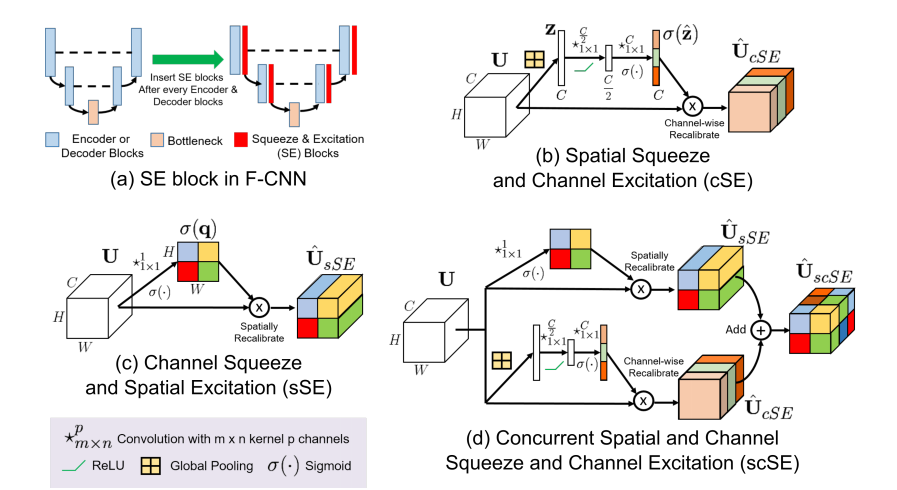
オリジナルのSqueeze & Excitation(SE)が(b)の形式です。Spatial Squeeze and Channel Excitationなので、空間方向に圧縮し、チャンネル方向を励起させるという形式を取っています。やりかたは、Global Average Pooling→Dense→ReLU→Dense→Sigmoid→Reshape→Multiplyです。
(c)のChannle Squeeze and Spatial Excitationは、チャンネル方向に圧縮して空間方向を励起させる、(b)とは圧縮と励起の方向が逆なのが特徴です。ここは1x1Convを使えばすぐできます。
(b)も(c)も効果があるんで、合わせりゃなんでもええやろで合体させたのが(d)です。
左上ではU-NetやDenseNetベースとする、Semantic Segmentationで使われるようなEncoder+DecoderのCNNにおいて、SE-Blockをどこに配置するかということが述べられています。意外とここについての言及は(あるいはバックボーンとDecoderをどう接続するかという話は)あまり見る機会が少ないので、なるほどと思いました。
ちなみにこのケースでは、DenseNetのようなEncoderしかないネットワーク(DenseNetはもともと画像分類)からどうDecoderを作るかという話は、
The encoding and decoding paths consist of repeating blocks separated by down-sampling and up-sampling, respectively
と書かれているので、同一の解像度単位を1つの塊とみて、塊単位で逆にたどるように配置すればいいのでしょうね。
効果
提唱しているscSEが最も良くないと論文として意義が薄れてしまうので、当然scSEが一番良いとなっています。
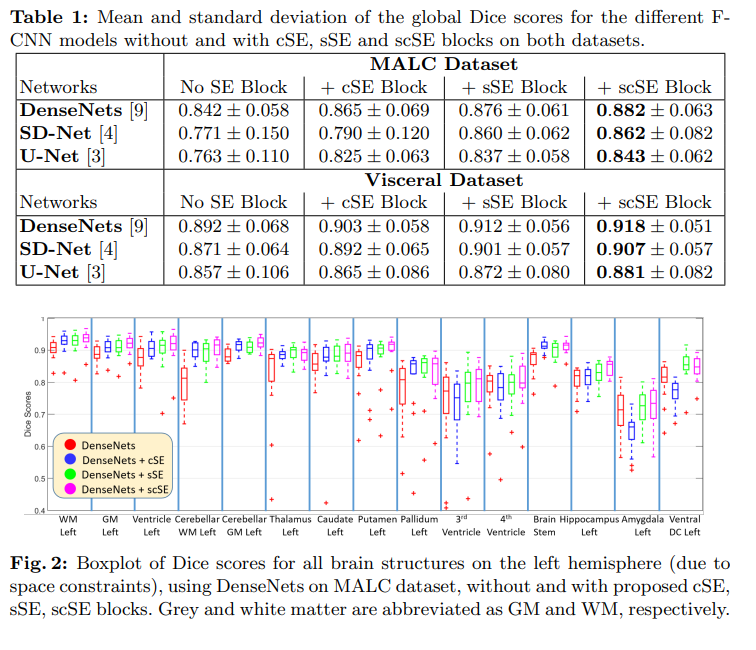
自分が面白いなと思ったのは、SEなしのU-Netは結構悪くて、SE1個でも入れると結構マシになるということです。SE自体はより広域の特徴を見る傾向があります。SEなしのU-Netレイヤーの数が少ないせいか、どうしても局所的に見てしまいがちなのでしょうか。したがってこれが結果的に精度を損ねているのでしょう。
SEなしからcSEやsSEを1個プラスしたときのゲインに比べれば、1個からscSEへのゲインは当然逓減してしまいますが、2つ入れればより効果が等しく出るというのはわかりやすいです。
実装
あの図からまとめるとこんな感じなのでしょうね。Kerasで書いてみました。
import tensorflow.keras.layers as layers
# Concurrent Spatial and Channel Squeeze and Channel Excitation https://arxiv.org/pdf/1803.02579.pdf
def sc_squeeze_excitation(inputs, ch):
# spatial squeeze and excitation (cSE)
c = layers.GlobalAveragePooling2D()(inputs)
c = layers.Dense(ch // 2, activation="relu")(c)
c = layers.Dense(ch, activation="sigmoid")(c)
c = layers.Reshape((1, 1, ch))(c)
c = layers.Multiply()([inputs, c])
# channle squueze and spatial excitation(sSE)
s = layers.Conv2D(1, 1, activation="sigmoid")(inputs)
s = layers.Multiply()([inputs, s])
return layers.Add()([c, s])
inputsは入力テンソルで、返り値もテンソルとしています。
cSEの圧縮率はこの論文では2としていますが、論文やケースによっていろいろ変わるので調整してみましょう。
雑感
SEの派生形や実装、精度を知りたいときに何度も参照する論文になりそうです。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー