
[論文メモ]Self-Attention Generative Adversarial Networks(SA-GAN)

SA-GAN(Self attention GAN)の論文を読んで実装したので、自分用メモとして書いておきます。
自分がやった実装の記事はこちら
Self-attention GAN(SAGAN)を実装して遊んでみた
https://blog.shikoan.com/sagan/
(普段こういう論文読みのテンプレート使わないけど、便利そうなんで使ってみます)
目次
論文
Self-Attention Generative Adversarial Networks
https://arxiv.org/pdf/1805.08318.pdf
画像はこちらから引用
どんなもの?
GANの安定化手法として有効であるなSpectral Normalizationを適用したSN-GANの後継。著者にGANの生みの親であるIan Goodfellow氏がいる。
SN-GANではSpectral NormをDiscriminator(D)にのみ適用していたのに対し、SN-GANではGenerator(G)にも適用。くわえてSelf attention機構とTTURを追加することで、ImageNetに対してより高画質な画像生成を可能にした。
先行研究と比べてどこがすごい?
ImageNetをクラスラベルの条件付きでノイズから生成して評価する。先行研究のSNGANのInception Scoreが36.8だったに対し、52.52まで上昇(高いほどよい)。またFIDでは27.62から18.65まで改善(低いほどよい)。また、SNGANで比較的難しかった、D:Gのアップデート回数を1:1で訓練することにも成功。これにより訓練を高速化することができた。
技術や手法のキモはどこ?
GにもSpectral Normを入れる
GにSpectral Normを入れた所、経験的にに明らかによくなった(ISで評価したときに2~5程度で振動していたのが直線的に上がるようになりISが30近くなった)。GにSpectral Normを入れることで、パラメーターの大きさをコントロールし、異常な勾配が伝わることを抑制する。
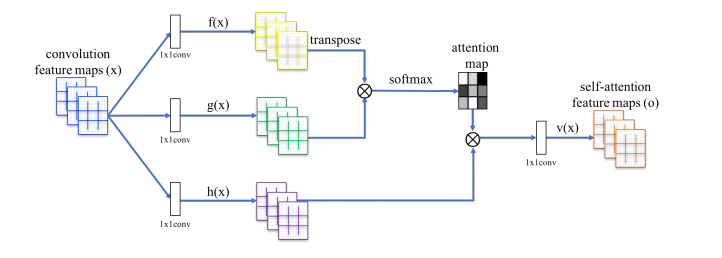
Self-attention機構
畳み込みニューラルネットワークは局所的な特徴に注目しがちなので、Self attention機構を使って全体の特徴量を加味させる。具体的にはグラム行列を取る。こんな構造
ただし、このままだとメモリ消費量が莫大になってしまうので、1×1畳み込みを使ってチャンネル数を減らしてからグラム行列を取っている。
なお、Self attentionにおける各点をクエリーとしたときの結果は次のようになっている。どれも点をクエリーとしているのに、より広範囲のエリアを見ている。局所的な形よりも、広範囲の形を見ながら生成することに重きをおいている。

その上で、Self attentionのレイヤーはD/Gともに、より高解像度のレイヤーに入れたほうが画質が向上することを指摘している(高解像度のレイヤーはごく狭いエリアしか畳み込んでいないから半ば当たり前)。

TTUR(two time-scale update rule)
DとGで異なる学習率を適用すること。SAGANではDを0.0004、Gを0.0001にしている。Dに高めの学習率を使う。TTURを使うとナッシュ均衡に収束しやすくなる。
どうやって有効だと検証した?
ImageNetをクラスの条件付きで生成し、Inception ScoreとFIDを計測。SNGANが36.8だったに対し、52.52まで上昇。またFIDでは27.62から18.65まで改善。論文が書かれた時点ではSoTAだった(後にBigGANに抜かれた)。
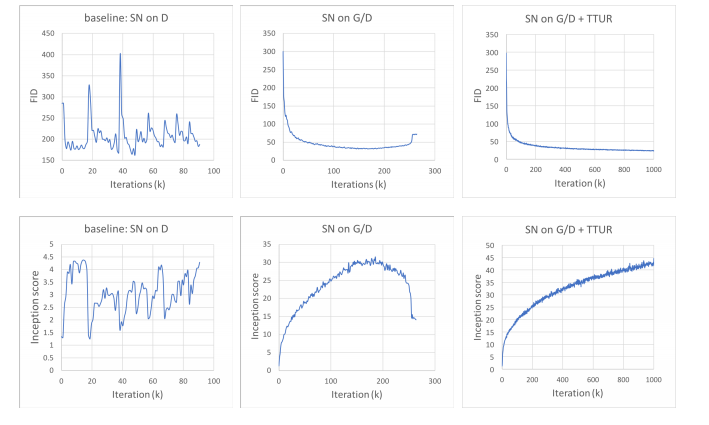
(このグラフはちょっとできすぎ感はする。SAGANでは真ん中の図のようにある所から直線的に崩壊するというケースがたびたびある)
また、全体のFIDだけではなくクラス間のFIDも調べており、Inception Score、クラス間のFID、全体のFIDすべてで先行研究よりも改善している。

議論はある?
特にInception Scoreのグラフはたまたまうまく行っただけのような感は否めない。あくまでImageNetでうまく行っただけで、自分が他のデータセットで試したらSNGANではなかったクラス内のモード崩壊が起こった。D:Gを1:1でやるには限界があるのかもしれない。
論文ではSAGANで示したテクニック(SNをG+Dにする+TTUR)をGANの安定化のためと位置づけている。SAGANの著者らは、SNGANにおいて1:1のアップデートをするのは非常に不安定であることを認識している。この不安定さは、アップデートを先行研究のようにD:G=5:1にすると解消され安定するが、余計な時間がかかってしまう。しかし、このD+Gの両方にSNを入れると、1:1のアップデートでも安定して訓練できたと主張している。
ただ、バッチサイズを際限なく大きくできれば別だが、現実問題として1回の場合は勾配の信頼性がかなり落ちてしまう。ImageNetではうまく行ったが一般的には限界はありそうな気はする。BigGANでは2:1で訓練しているので、何かしらの失敗ケースは増えてもおかしくはない。
次に読むべき論文は?
BigGANの論文。BigGANがこのSAGANの改良版。なお、これらの3つのテクニックは細部は変更されてはいるものの、BigGANにおいてすべて継承されている。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー