
論文まとめ:ConTextual: Evaluating Context-Sensitive Text-Rich Visual Reasoning in Large Multimodal Models
Posted On 2024-02-22


- 論文タイトル:ConTextual: Evaluating Context-Sensitive Text-Rich Visual Reasoning in Large Multimodal Models
- 著者:Rohan Wadhawan, Hritik Bansal, Kai-Wei Chang, Nanyun Peng(UCLA)
- 論文URL:https://arxiv.org/abs/2401.13311
- プロジェクト:https://con-textual.github.io/
- データセット:https://huggingface.co/datasets/ucla-contextual/contextual_all
目次
ざっくりいうと
- マルチモーダルLLMに対して、テキストと視覚的要素の相互作用を評価するためのデータセット「ConTextual」を構築した論文
- 従来のVQAのデータセットはOCRタスクに寄っていたが、Webサイトや時計の読解といった実応用よりのタスクのデータ
- データセット構築までの流れが詳細に示されており、GPT-4V/Gemini/OSSモデルのほか人間のベンチマークも提示されている。LLMによる自動評価も検証
はじめに
- 先行研究では、画像内のテキスト理解に焦点を当てたデータセットが多く提案されている(TextVQA、STVQA、ESTVQA)
- これらのデータセットで評価すると、OCRの性能=モデルの性能になってしまう
- 画像内のテキストと視覚的なコンテキストを共同で推論するタスクについて、LLMの性能を評価したい
- この課題を解決するために、ConTextualデータセットを作った

- 8個のマルチモーダルコンテクストからなるもの
- 13の基盤モデルの性能を評価する実験
- GPT-4Vが現状最も良かったが、人間のベースラインより大きく下回る
- 人間の評価はスケールできないので、自動評価も行った。ミームの理解のような、視覚的な文脈を含むタスクではGPT-4Vのほうが人間より強い
ConTextualデータセット
収集ガイドライン
- ガイドライン
- 「画像、指示、返答」のTripletからなる。OCRを読めばそのまま答えられるようなインストラクションは避けたい
- 質問や命令型タスクなど、多様な指示をカバー
- 複雑さの指示を作成することを目的
- バナナ風味の飲み物を挙げなさい
- 青色の単語の数を数えて
- 8個のコンテクスト:実世界でのヒューマンインタラクションに基づく視覚的なシナリオ。具体的なシナリオはAppendixに記載
- ナビゲーション(交通手段や案内標識)
- 「方向ごとにゲートをまとめて」
- ショッピング(食料品、衣服、ガジェットを買う)
- 「白いドレス、ヒールのあるサンダル、サングラスを組み合わせたときの合計金額は?」
- その他自然シーン(その他ヒューマンインタラクション)
- 「外野手によって読むのが困難になった文字を教えて」
- 抽象(ミームの理解)
- 「画像にある一般的なことわざを特定して」
- 時間(時計やカレンダーを使って日時を出力)
- アナログ時計とデジタル時計が正確に対応しているか教えて」
- Web(異なるドメインのWebサイト)
- どの商品が値下がりしましたか?」
- インフォグラフィック(様々なトピックに関する視覚情報)
- 「ロックダウン指数が非0で、85-100の範囲にある国はどこ?」
- アプリケーション(取扱説明書、教育・ゲーム・娯楽などのスマホアプリ)
- 「イラスト内で示されている各運動をリストアップして」
- ナビゲーション(交通手段や案内標識)
- 私の注釈:ニーズベースでコンテクストを定義しているのが面白い

データソース
- 6個の異なるデータソースから。
(1) LAION-5B
- CLIP-retrieval UIを使ったキーワード検索でフィルタリング。カテゴリに特化した単語で検索。カテゴリー別の単語例
- 買い物(例:食料品、家具、ガジェット、化粧品、サービス、衣類)
- ナビゲーション(例:道路標識、自動車、バス、電車、地下鉄、空港、駅、高速道路、道路)
- 時間(例:時計、複数の時計、デジタル時計、タイムゾーン、カレンダー、スケジュール、時計)
- 抽象(例:ミーム、相場、コミックストリップ、科学ジョーク、数学ジョーク、インフォグラフィックミーム)
(2) Rico Dataset
- アプリケーションのカテゴリで使用
- 27カテゴリに渡る9300のAndroidアプリに由来する、6600の異なるUI画面が含まれる
(3) Open WebText Initiative
- Webのカテゴリで使用
- OpenAIのWebTextデータセットを再現するためのOSSデータセット
- ウェブサイトのリンクが提供されるので、スクレイピング
(4-6) 既存のVQAデータセット
- InfographicVQA+STVQA+ESTVQA
アノテーション
3段階からなる
- ステージ1:フィルタリング
- 時計、買い物、ナビゲーション、抽象
- 手動でフィルタリング。アノテーションに適したものを保証したい
- アプリケーション、Web、インフォグラフィック、その他自然シーン
- ヒューリスティックによるフィルタリング。PaddleOCRにより、テキストを検出。単語数の多い上位500枚を選択し、アノテーション
- 時計、買い物、ナビゲーション、抽象
- ステージ2:指示・返答の作成
- 著者をグループ1とグループ2の集団にわけ、それぞれ4つのカテゴリでフィルタリング
- 私の注釈:著者が自らアノテーションしてるの結構珍しい
- アノテーションガイドラインを厳守する
- 著者をグループ1とグループ2の集団にわけ、それぞれ4つのカテゴリでフィルタリング
- ステージ3:データサンプルの検証
- もう一方のグループにアノテーションを確認させ、ガイドラインを厳守しているか確認
データの公開
- 506のサンプルからなる
- HuggingFaceで公開中(MITライセンス)
- https://huggingface.co/datasets/ucla-contextual/contextual_all
実験
- 本データセットの目的は単純なOCRでは解けない問題であるので、まずはGPT-4のようなユニモーダルLLM+OCRを試す。OCRの設定は、
- vanilka OCR
- Layout-aware OCR
- Layout-aware OCR + 画像キャプション
- OPRはPaddleOCRライブラリのPP-OCRv4を利用
- OCRのレイアウト認識を維持するために、LATINプロンプトに触発されたOCR配置実装
- キャプション生成はShareGPT-4V-7Bを活用
- 人間のベンチマークでは、Amazon Mechanical Turkを使用した。人間のベンチマークを収集するために180ドル必要だった。
- GPT-4+OCRのケース。1枚目がレイアウト配置意識なし(デリミタ「/」で区切る)、2枚目がLayout-aware+画像キャプション。4枚の写真に対応するようにタブ区切りのようにしている。


- 人間のベンチマークする際のUI(Amazon Mechanical Turk)

評価
- モデルの出力をまず人間が評価する
- 対象モデルは、GPT-4+OCR、GPT-4V、Gemini-Pro-Vision、LLaVA-1.5-13B、ShareGPT-4V-7B、人間のキャプション
- 推論対象だけ評価対象があり、全部で1680個となる
- 3人のアノテーターに独立して提示して、受容度(0-100)を評価させ、アンサンブル
- Amazon Mechanical Turkを使用し、1000ドル必要だった
- 人間の評価は黄金であるが、コストがかかるので自動評価したい。参照誘導型自動評価のテストをする
- GPT-4に指示+参照応答+予測応答を示す
- GPT-4Vに画像+指示+参照応答+予測応答を示す
- 参照-予測応答の従来のNLP指標:BLEURT、Rouge-L、BERTScore
- 自動評価と人間の評価の相関分析を行った。GPT-4による評価が最も人間とのROC-AUCと相関が高かった
- 入力画像にアクセスできるGPT-4Vはバイアスが生じる可能性があると分析。これにより参照応答を見逃して、入力画像を見てしまう

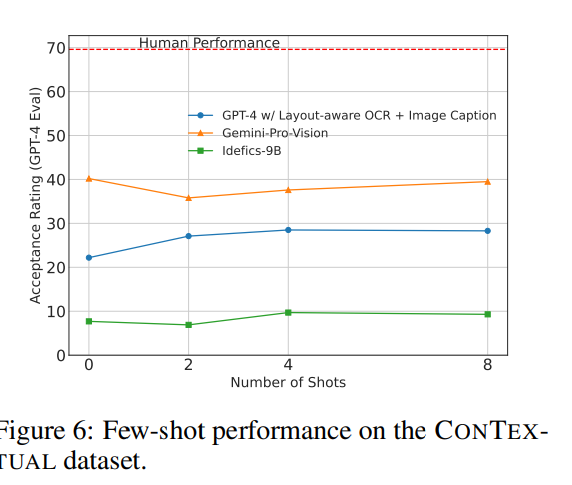
Few-shotはそこまで効かない
- Incontext-LearningでFew-shotしたら精度下がる場合がある。上がるものの劇的ではない
- 最近の研究では、Few-shotにおけるLMMの不安定性が述べられている
- 例:InstructBLIPでは4ショットすると、特に常識推論が必要なタスクで大幅な精度低下が起こる
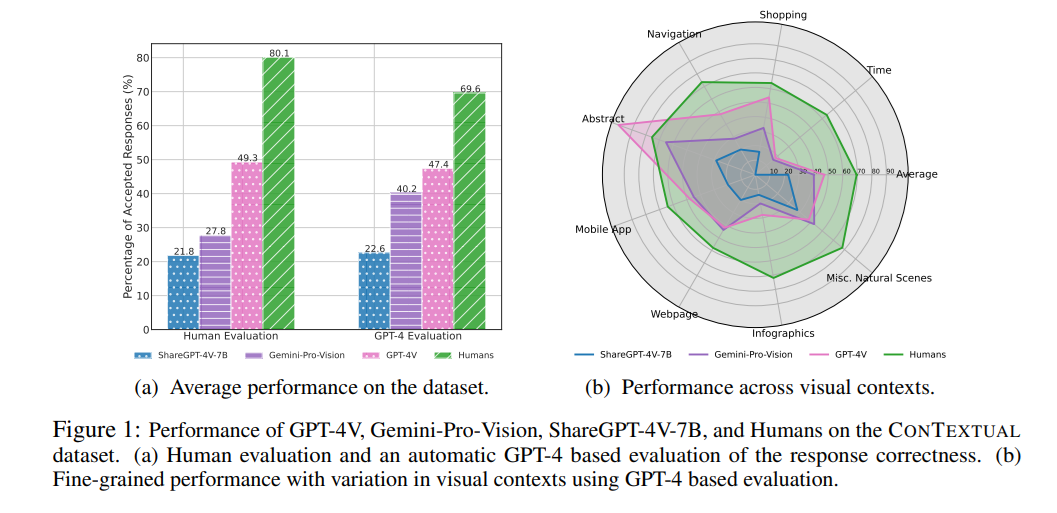
GPT-4による自動評価の結果
- LLMで最も良かったのはGPT-4V
- ABS(抽象。例:ミームの理解)タスクでは、GPT-4Vが人間のパフォーマンスを超えている
- それ以外のタスクでは人間のほうが良く、時計やインフォグラフィック、ナビゲーションやアプリケーションが苦労
- COCOデータセットは自然なシーンで構成されているので、これで訓練されたモデル(LLaVAやBLIVA)はConTextualデータセットでは失敗
失敗例
緑字が正しいもの、赤字が誤り

- 左の例:GPT-4Vは論理的な推論だが、間違った回答をする
- 右の例:GPT-4Vは正しく回答しているが、OSSモデルやGPT-4+Layout-aware OCR+キャプションは失敗。テキストと画像に対しる共同推論がないため、Groundingされていない
所感
- 非常に良い論文。データセットの構築方法が詳細に説明されているのはとても良い
- 「VQAってOCRで説明できてしまいますよね」はとても感じていたことなので、この切り口はとても良い
- データセットのコンテクストがユースケースに焦点あてているのが良い
- データセットをスケールするのが難しいが、例えばこのデータをベースにLoRAを訓練したときにどのぐらいこのタスクが向上するのかが気になる
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー