
Diffusers版のControlNet+LoRAで遊ぶ:理論と実践


前回に引き続き、Stable DiffusionのControlNetで遊んでみます。ControlNetとは画像主に空間方向の強い条件付が可能です。LoRAと組み合わせて動画レンダリングのようなこともできつつあるので、使いこなすとかなり強力な武器になりそうです。
目次
はじめに
前回はLoRAで遊んでみましたが、今回はこちらもよく話題にのぼるControlNetで遊んでみました。ControlNetもDiffusersで対応しており、簡単に使うことができます。
ControlNetとは
解説が結構多いので今更感はありますが、2023年2月に発表された論文です。
従来のStable Diffusionは「この人をこういうポーズで配置してほしい」や「ここにこれをおいてほしい」や「輪郭線はこうしてほしい」のような、なにか制約条件をおいた上で生成するということが難しいという課題がありました。実践的には、キャラクターのポーズの指定や、配置の指定などができると嬉しく、またそれをプロンプトだけでやるのもチューニングが大変です(プロンプトは意味的な表現はできますが、空間方向への作用は限定的です)。
従来の画像処理やディープラーニングは、輪郭線やポーズ情報、セマンティックマップなどは広く使われていました。これをInputの条件として取り込むことで、より簡単に構図を指定できるようになったというのがControlNetの大きな特徴です。

これはControlNetの論文からの引用です。左上が参照画像(フリー素材などを想定してください)。左下のように画像から輪郭線(Canny Edge)を抽出します。これはOpenCVのような従来の画像処理でOKです。
このCanny EdgeをInputとして、プロンプトを追加して、生成した結果が右の4枚です。やっていることはImage2Imageの応用です。
ControlNetのネットワーク構造
ControlNetは、訓練済みStable Diffusionモデルに対して、追加のモデル(ControlNet)を導入し、追加モデル分だけ訓練します。「ポーズを条件とした生成」「エッジを条件とした生成」というのは、膨大な事前訓練を経てできたStable Diffusionから見たら下流タスクにあたるわけですから、LoRAのようなAdapterに近い発想をしています(この解釈は私の解釈なので、論文にかかれているものではありません)。論文ではAdapterとは言っていませんが、私はこれをAdapterと言ってもいいと思います。
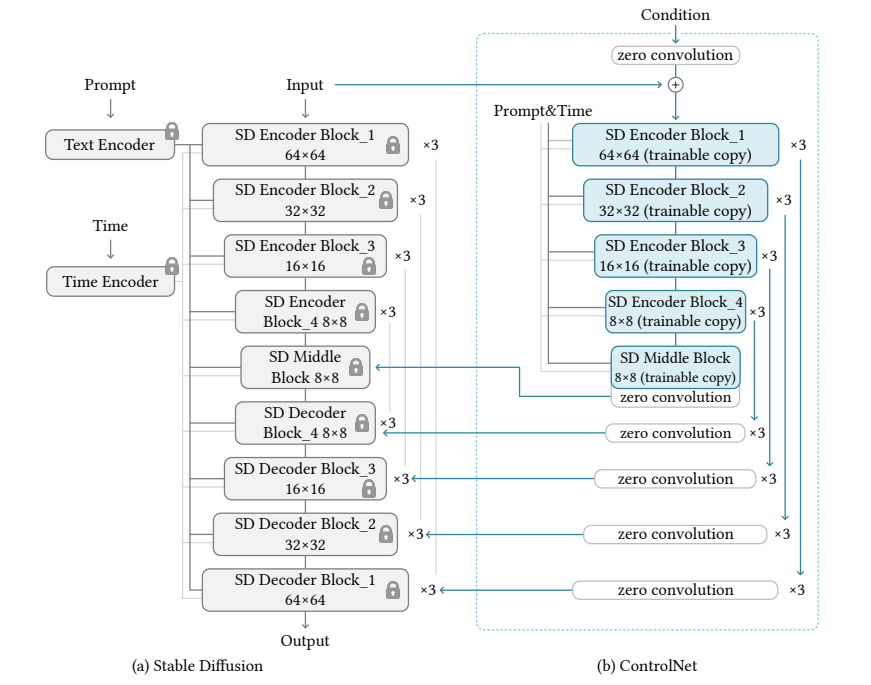
LoRAとの違いは、LoRAはあくまでInput-Outputは変わらず、データの分布のみ適用させます(LoRAでいきなりポーズを条件にした生成ができることはありません)。ControlNetはタスク設定そのものを変えます。
Zero Convolution
ControlNetの大きな特徴として、追加のレイヤー(ここでは勝手にAdapterと呼んでしまいます)を0で初期化するということです。Zero Convolutionと論文で呼んでいます。実はこのZero Convolutionが、今までのディープラーニングからしたらかなり掟破りです。
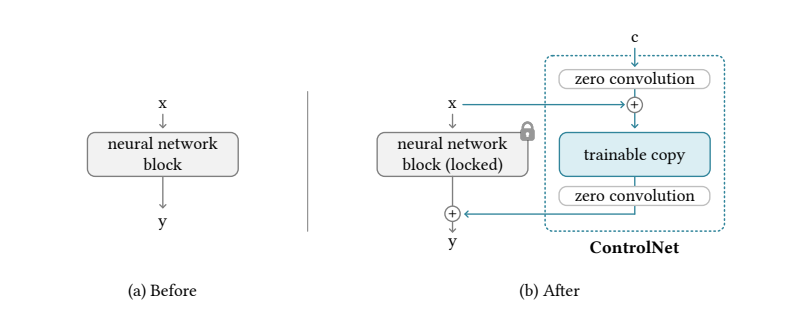
従来のディープラーニングでは、レイヤーの初期値は必ず乱数(Heの初期化、xavierの初期化など)を使っています。この理由は、逆に0のような定数で初期化してしまうと、勾配消失や学習が止まってしまうなどの問題が発生します(ここを疑う人はあまりいないと思います笑)。
ただ、ControlNetの場合は、レイヤー構造がResNetのようなSkip Connection構造で、メインのパス(Stable Diffusion)はロックして、Skip Connection(Zero Convolution)は訓練するという特殊な状況です。したがって、訓練の開始時は、レイヤーを追加しようがControlNetの影響を無視した出力になると嬉しいという事情があります。Zero Convolution側の係数を0で初期化してしまえば、計算結果はすべて0であるため、最初のForward passはControlNetがあろうがなかろうが同じになります。ControlNetはAdapter的な構造なため、この性質が嬉しいというわけです。
「で、これで勾配伝わるの?」という疑問もありますが、これは論文で解説されており
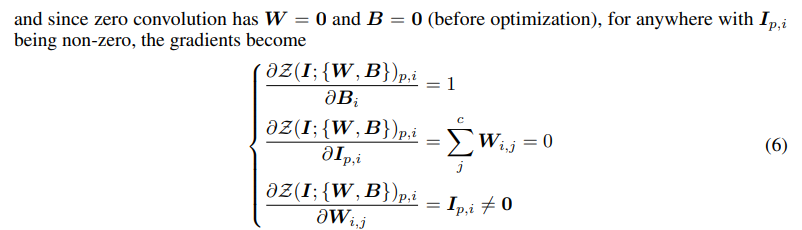
「画像が0出ない限り、画像Iに対する偏微分は0になっても、係数に対する偏微分は0にはならない→よって学習は進む」という主張です。これはAdapterで汎用的に使えそうな考え方ではないかと思います。
訓練リソースの少なさ
ControlNetは、オリジナルのStable Diffusionと比べると訓練リソースが少ないことでも知られます。例をあげると
- Segmentation(COCO):COCOのデータセットをBLIPでキャプションし、164Kのデータセットに対し、3090Tiで400時間
- CannyEdge:インターネットからクロールした3Mの画像に対し、80GのA100が600時間
- Human Pose(OpenPose):200kのキャプション済みのPose画像に対し、80GのA100が300時間
ご家庭にあるGPUで簡単にできるかと言われたら「うーん」という感は否めないものの、Stable DiffusionのFinetuningよりは計算リソースは少なくてすみます。
LoRAと併用可能、他のDiffusionでも対応可能
これがControlNetの大きな強みですが、LoRAと併用可能です。LoRAもControlNetもAdapterの一種で、元のStable Diffusionは一緒なので、パッチを重ねがけする要領でできます。したがって、特定キャラクターのLoRAを用意しておけば、ControlNetのポーズと組み合わせることで3Dレンダリングのようなことはできます。
また、ControlNetはStable Diffusion1.5で訓練されたものですが、他のDiffusionのモデル(Anything V4など)に転用してもある程度ロバストです。現にそのようなHuggingFaceのSpaceがあります(参考)。ドメインギャップはあると思うので、コントロール性能は訓練された元モデルよりかは落ちるのは仕方ないでしょう。
ControlNet(ポーズ)を使う
ControlNetはDiffusersから使えます。
公式Blog:https://huggingface.co/blog/controlnet
この公式ブログのヨガ画像をそのまま使って、Anything V4で画像生成します。
以下のファイルを「images」以下に保存しておきます。
- https://huggingface.co/datasets/YiYiXu/controlnet-testing/resolve/main/yoga1.jpeg
- https://huggingface.co/datasets/YiYiXu/controlnet-testing/resolve/main/yoga2.jpeg
- https://huggingface.co/datasets/YiYiXu/controlnet-testing/resolve/main/yoga3.jpeg
- https://huggingface.co/datasets/YiYiXu/controlnet-testing/resolve/main/yoga4.jpeg
適当にテンプレプロンプトで錬成します。
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
from controlnet_aux import OpenposeDetector
import torch
from PIL import Image
import numpy as np
def main():
device = "cuda:1"
# Detect poses
pose_detector = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
poses = []
for i in range(1, 5):
p = pose_detector(Image.open(f"images/yoga{i}.jpeg"))
poses.append(p)
# Load control net
controlnet = ControlNetModel.from_pretrained(
"lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"andite/anything-v4.0", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# Disabling safety checker
if pipe.safety_checker is not None:
pipe.safety_checker = lambda images, **kwargs: (images, False)
pipe.to(device)
# run stable diffusion
images = []
generator = torch.Generator(device)
prompt = "1girl, masterpiece, best quality, extremely detailed, 4K, illustration"
negative_prompt = "low quality, worst quality, bad fingers, bad face, extra arms, extra legs"
for i in range(3):
generator.manual_seed(i+1024)
image = pipe([prompt]*4, poses, negative_prompt=[negative_prompt]*4, generator=generator,
num_inference_steps=50, output_type="numpy").images
images.append(image)
images = (np.concatenate(images, axis=0) * 255.0).astype(np.uint8)
# Concatenate images
h, w, c = images.shape[1:]
images = images.reshape(3, 4, h, w, c).swapaxes(1, 2).reshape(3*h, 4*w, c)
with Image.fromarray(images) as img:
img.save("result.jpg", quality=90)

元のポーズは以下の通り(HuggingFaceの動画ブログより)

ややずれている感は否めないですが、それっぽくできています。
ControlNet(ポーズ)+LoRA
次は前の記事で作ったユニティちゃんLoRAを併用してみます。
LoRAの追加は簡単で、PipeにLoRAのモデルパスを追加するだけでOKです
controlnet = ControlNetModel.from_pretrained(
"lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"andite/anything-v4.0", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# ここを追加
pipe.unet.load_attn_procs("weights/unitychan_weights.bin")
# Disabling safety checker
if pipe.safety_checker is not None:
pipe.safety_checker = lambda images, **kwargs: (images, False)
pipe.to(device)
LoRAを使うとVRAM使用量が増えてOOMになったので、バッチ単位で推論しています。
# run stable diffusion
images = []
generator = torch.Generator(device)
prompt = "an illustration of a sks girl, best quality, extremely detailed"
negative_prompt = "low quality, worst quality, bad fingers, bad face, extra arms, extra legs"
# prompt = "an illustration of a sks girl"
# negative_prompt = "low quality"
for i in range(3):
for j in range(4):
generator.manual_seed(i+1024)
image = pipe(prompt, poses[j], negative_prompt=negative_prompt, generator=generator,
num_inference_steps=50, output_type="numpy", width=512, height=704).images[0]
images.append(image)
images = (np.stack(images, axis=0) * 255.0).astype(np.uint8)
# Concatenate images
h, w, c = images.shape[1:]
images = images.reshape(3, 4, h, w, c).swapaxes(1, 2).reshape(3*h, 4*w, c)
with Image.fromarray(images) as img:
img.save("result.jpg", quality=90)

与えていない構図はしょぼいですがこんなものでしょう。ちなみにプロンプトを簡単にすると、
prompt = "an illustration of a sks girl"
negative_prompt = "low quality"

いろいろおかしくなりましたが、塗りは若干薄くなりました。例のプロンプトは厚塗りにする傾向があるんですかね? ただ、例のプロンプトを使うと、後ろ向きで立っている2列目のように、明らかに与えていない構図に対して補間してくれるのはすごい。
動画のControlNet(LoRAなし)
ダンスしているような動画に対して、ControlNet(Pose)を与えるのはどうでしょうか?
この動画を「videos/sample_video1.mp4」として保存しておきます。
40秒程度とはいえ、全フレームにStable Diffusionをかけるのはしんどいので、25FPS→1FPSにダウンサンプリングします。ffmpegを使うので適当にバイナリをカレントディレクトリに入れておきます(Windowsの場合。この記事参照)
import ffmpeg
import numpy as np
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
from controlnet_aux import OpenposeDetector
import torch
def main():
probe = ffmpeg.probe("videos/sample_video1.mp4")
video_streams = [stream for stream in probe["streams"] if stream["codec_type"] == "video"]
width = video_streams[0]["width"]
height = video_streams[0]["height"]
fps = int(eval(video_streams[0]["r_frame_rate"]))
out_width, out_height = 960, 512
cap = (
ffmpeg
.input("videos/sample_video1.mp4")
.output('pipe:', format='rawvideo', pix_fmt='rgb24')
.run_async(pipe_stdout=True)
)
writer = (
ffmpeg
.input('pipe:', format='rawvideo', pix_fmt='rgb24', s='{}x{}'.format(out_width, out_height), r=fps//25)
.output("output.mp4", pix_fmt='yuv420p')
.overwrite_output()
.run_async(pipe_stdin=True)
)
device = "cuda:1"
# Pose detector
pose_detector = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
# Diffusion
controlnet = ControlNetModel.from_pretrained(
"lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"andite/anything-v4.0", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.to(device)
generator = torch.Generator(device)
prompt = "1girl, solo, masterpiece, best quality, extremely detailed, 4K, illustration"
negative_prompt = "low quality, worst quality, bad fingers, bad face, extra arms, extra legs"
# Disabling safety checker
if pipe.safety_checker is not None:
pipe.safety_checker = lambda images, **kwargs: (images, False)
pipe.to(device)
# Count
cnt = 0
while True:
in_bytes = cap.stdout.read(width * height * 3)
if not in_bytes:
break
in_frame = (
np
.frombuffer(in_bytes, np.uint8)
.reshape([height, width, 3])
)
if cnt % 25 != 0:
cnt += 1
continue
p = pose_detector(in_frame)
generator.manual_seed(1024)
image = pipe(prompt, p, negative_prompt=negative_prompt, generator=generator,
num_inference_steps=50, output_type="numpy").images[0]
image = image * 255.0
writer.stdin.write(
image
.astype(np.uint8)
.tobytes()
)
cnt += 1
writer.stdin.close()
cap.wait()
writer.wait()
ちなみに「1girl, solo」のような人数指定プロンプトを入れないと、隙間から別人が勝手に生えてきます。人数のコントロールが難しそうですね。
シードは固定していますが、背景やキャラがフレームによってバラバラで統一性はありません。動画生成ではないので、フレーム間の演算はしていません。あくまでスライドショー生成です。
動画のControlNet(LoRAあり)
LoRAを入れてみます。プロンプトは以下のようにします。
prompt = "an illustration of a sks girl, 1girl, solo, best quality, extremely detailed"
negative_prompt = "low quality, worst quality, bad fingers, bad face, extra arms, extra legs"
まあこんなものかーという感じですね。これだったらUnity使ったほうが便利そうですよね。突然カットインっぽい顔が入ってるのはアニメのOPかなにかを学習したのでしょうか。下に変なロゴらしきものが出てるのなんなんでしょうね。
ControlNet(SD15+LoRA)
ちょっと不満足だったので、ControlNetをPoseのまま、元のモデルをControlNetが学習されたSD1.5に変えます。LoRAもSD1.5で学習させなおします。
prompt = "sks girl, 1girl, solo, best quality, extremely detailed"
negative_prompt = "low quality, worst quality, bad fingers, bad face, extra arms, extra legs"
ちょっとキャラがうふふな感じになってしまって、アップロードは厳しいのですが、キャラ数やポーズの設定はある程度まししになったものの、目に見えてよくなったという感じではないです。
ControlNet(Segmentation)
ControlNetにはSegmentationのモデルがあるのに気づきました。これは条件付の部分にセグメンテーションマップを与えて生成するものです。このセグメンテーションマップはADE20Kのカテゴリならなんでも行けるので、表現力はかなり高いです。
WikipediaのAbbey Roadのページからです

これをベースにセグメンテーションのControlNetで生成してみます。
from transformers import AutoImageProcessor, UperNetForSemanticSegmentation
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
import torch
from PIL import Image
import numpy as np
def ade_palette():
"""ADE20K palette that maps each class to RGB values."""
return [[120, 120, 120], [180, 120, 120], [6, 230, 230], [80, 50, 50],
[4, 200, 3], [120, 120, 80], [140, 140, 140], [204, 5, 255],
[230, 230, 230], [4, 250, 7], [224, 5, 255], [235, 255, 7],
[150, 5, 61], [120, 120, 70], [8, 255, 51], [255, 6, 82],
[143, 255, 140], [204, 255, 4], [255, 51, 7], [204, 70, 3],
[0, 102, 200], [61, 230, 250], [255, 6, 51], [11, 102, 255],
[255, 7, 71], [255, 9, 224], [9, 7, 230], [220, 220, 220],
[255, 9, 92], [112, 9, 255], [8, 255, 214], [7, 255, 224],
[255, 184, 6], [10, 255, 71], [255, 41, 10], [7, 255, 255],
[224, 255, 8], [102, 8, 255], [255, 61, 6], [255, 194, 7],
[255, 122, 8], [0, 255, 20], [255, 8, 41], [255, 5, 153],
[6, 51, 255], [235, 12, 255], [160, 150, 20], [0, 163, 255],
[140, 140, 140], [250, 10, 15], [20, 255, 0], [31, 255, 0],
[255, 31, 0], [255, 224, 0], [153, 255, 0], [0, 0, 255],
[255, 71, 0], [0, 235, 255], [0, 173, 255], [31, 0, 255],
[11, 200, 200], [255, 82, 0], [0, 255, 245], [0, 61, 255],
[0, 255, 112], [0, 255, 133], [255, 0, 0], [255, 163, 0],
[255, 102, 0], [194, 255, 0], [0, 143, 255], [51, 255, 0],
[0, 82, 255], [0, 255, 41], [0, 255, 173], [10, 0, 255],
[173, 255, 0], [0, 255, 153], [255, 92, 0], [255, 0, 255],
[255, 0, 245], [255, 0, 102], [255, 173, 0], [255, 0, 20],
[255, 184, 184], [0, 31, 255], [0, 255, 61], [0, 71, 255],
[255, 0, 204], [0, 255, 194], [0, 255, 82], [0, 10, 255],
[0, 112, 255], [51, 0, 255], [0, 194, 255], [0, 122, 255],
[0, 255, 163], [255, 153, 0], [0, 255, 10], [255, 112, 0],
[143, 255, 0], [82, 0, 255], [163, 255, 0], [255, 235, 0],
[8, 184, 170], [133, 0, 255], [0, 255, 92], [184, 0, 255],
[255, 0, 31], [0, 184, 255], [0, 214, 255], [255, 0, 112],
[92, 255, 0], [0, 224, 255], [112, 224, 255], [70, 184, 160],
[163, 0, 255], [153, 0, 255], [71, 255, 0], [255, 0, 163],
[255, 204, 0], [255, 0, 143], [0, 255, 235], [133, 255, 0],
[255, 0, 235], [245, 0, 255], [255, 0, 122], [255, 245, 0],
[10, 190, 212], [214, 255, 0], [0, 204, 255], [20, 0, 255],
[255, 255, 0], [0, 153, 255], [0, 41, 255], [0, 255, 204],
[41, 0, 255], [41, 255, 0], [173, 0, 255], [0, 245, 255],
[71, 0, 255], [122, 0, 255], [0, 255, 184], [0, 92, 255],
[184, 255, 0], [0, 133, 255], [255, 214, 0], [25, 194, 194],
[102, 255, 0], [92, 0, 255]]
def main():
device = "cuda:1"
# Initialize semantic segmentator
image_processor = AutoImageProcessor.from_pretrained("openmmlab/upernet-convnext-small")
image_segmentor = UperNetForSemanticSegmentation.from_pretrained("openmmlab/upernet-convnext-small")
image = Image.open("Abbey_Road_(albom).jpg").resize((512, 512), Image.Resampling.BICUBIC)
pixel_values = image_processor(image, return_tensors="pt").pixel_values
with torch.no_grad():
outputs = image_segmentor(pixel_values)
seg = image_processor.post_process_semantic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
color_seg = np.zeros((seg.shape[0], seg.shape[1], 3), dtype=np.uint8) # height, width, 3
palette = np.array(ade_palette())
for label, color in enumerate(palette):
color_seg[seg == label, :] = color
color_seg = color_seg.astype(np.uint8)
color_seg = Image.fromarray(color_seg)
# Load control net
controlnet = ControlNetModel.from_pretrained(
"lllyasviel/sd-controlnet-seg", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"andite/anything-v4.0", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# Disabling safety checker
if pipe.safety_checker is not None:
pipe.safety_checker = lambda images, **kwargs: (images, False)
pipe.to(device)
# run stable diffusion
images = []
generator = torch.Generator(device)
prompt = "an illustration of kawaii girl, best quality, extremely detailed"
negative_prompt = "low quality, worst quality, bad fingers, bad face, extra arms, extra legs"
for i in range(6):
generator.manual_seed(i+1024)
image = pipe(prompt, color_seg, negative_prompt=negative_prompt, generator=generator,
num_inference_steps=50, output_type="numpy").images
images.append(image)
images = (np.concatenate(images, axis=0) * 255.0).astype(np.uint8)
# Concatenate images
h, w, c = images.shape[1:]
images = images.reshape(2, 3, h, w, c).swapaxes(1, 2).reshape(2*h, 3*w, c)
with Image.fromarray(images) as img:
img.save("result.jpg", quality=90)
解像度512

顔の描画はうまくいっていませんが、なかなか「おおっ」という結果になりました。やはり、Segmentationのほうが持っている情報が多いのですね。この例は出力画像の解像度を512にした例です。
解像度1024
解像度を1024まで上げると、色味が抜けたような感じになります。解像度が上がった関係で、全体のコンテクストの補間が追いついていていないのでしょう。

LoRAあり
LoRAを入れるとこのようになります。

「街路樹と髪の色が区別ついていないなど」など、LoRA特有の難しさが出ます。LoRAで正則化画像をいくつか与えて訓練する必要がありそうです。
ControlNet(Seg)+LoRA→Image2Image
ControlNet(Seg)+LoRAの結果はラフっぽく見えなくもないので、生成を2段階に分けて、後段でラフ画像をちょっとよくするようなImage2Imageをかけます。
こういう局所的な修正はStable Diffusion得意かどうかわからないのですが、以下のような処理を追加します。
# 2nd-phase Image2Image
pipe = None
torch.cuda.empty_cache()
pipe = StableDiffusionImg2ImgPipeline.from_pretrained("andite/anything-v4.0", torch_dtype=torch.float16)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# Disabling safety checker
if pipe.safety_checker is not None:
pipe.safety_checker = lambda images, **kwargs: (images, False)
pipe.to(device)
prompt = "girls, best quality, extremely detailed, illustration"
images = []
for i in range(3):
for j in range(2):
generator.manual_seed(j+1000)
image = pipe(prompt, inter_images[i], negative_prompt=negative_prompt, generator=generator,
num_inference_steps=30, strength=0.4, guidance_scale=20, output_type="numpy").images
images.append(image)
images = (np.concatenate(images, axis=0) * 255.0).astype(np.uint8)
# Concatenate images
h, w, c = images.shape[1:]
images = images.reshape(2, 3, h, w, c).swapaxes(1, 2).reshape(2*h, 3*w, c)
with Image.fromarray(images) as img:
img.save("result.jpg", quality=90)
ここが局所的な描画をよくするようなモデルだともっとうまくいくのですが、若干良くなったでしょうか。ハイパラにちょっと鋭敏なのが改良の余地がありそうです。

パラメーターの調整は以下の指針でやっています
- num_inference_stepsとstrength:多くしすぎると構図が崩れるので、特にstrengthを小さめにする
- guidance_scale:これはプロンプトの効き具合をコントロールするパラメータ。プロンプトを画質をよくするような設定にし、Guidance scaleを強めにかければ、詳細な描画になるかもしれないという気持ち。
「画質をよくするだけのプロンプト」というのはなかなか探しづらいです。CLIPのEmbeddingをごにょごにょすればおそらく見つかるかもしれませんが、言語ベースだけだとなかなか難しいところはあります。
もし本格的に使うなら、ここは画質をよくするだけのGANとか入れたほうがいいかもしれません。
MultiDiffusionのようなアプローチを使うのもありだと思います。
複数のControlNetを適用させる
公式ブログの最後の方に複数のControlNetが対応できるという記述がありますが、Diffusers0.14.0では正式に対応されていません。
ここはDockerイメージを使って試します。(正式に対応されればこの処理は不要になります。)
FROM nvidia/cuda:11.7.1-cudnn8-runtime-ubuntu20.04
RUN apt-get update
ENV TZ=Asia/Tokyo
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
RUN apt-get install -yq --no-install-recommends python3-pip \
python3-dev \
wget \
git \
libopencv-dev \
ffmpeg \
tzdata && apt-get upgrade -y && apt-get clean
RUN ln -s /usr/bin/python3 /usr/bin/python
COPY requirements.txt .
RUN pip install -U pip &&\
pip install --no-cache-dir -r requirements.txt
requirements.txt
--extra-index-url https://download.pytorch.org/whl/cu117
torch==2.0.0+cu117
torchvision==0.15.1+cu117
accelerate==0.18.0
transformers==4.27.3
ftfy==6.1.1
scipy==1.10.1
safetensors==0.3.0
git+https://github.com/huggingface/diffusers.git
controlnet_aux==0.0.1
opencv-python==4.7.0.72
ffmpeg-python==0.2.0
ControlNet (Segmentation+Pose)
from transformers import AutoImageProcessor, UperNetForSemanticSegmentation
from controlnet_aux import OpenposeDetector
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
import torch
from PIL import Image
import numpy as np
def ade_palette():
"""ADE20K palette that maps each class to RGB values."""
### 省略
def main():
device = "cuda:1"
# Initialize semantic segmentator
image_processor = AutoImageProcessor.from_pretrained("openmmlab/upernet-convnext-small")
image_segmentor = UperNetForSemanticSegmentation.from_pretrained("openmmlab/upernet-convnext-small")
img_path = "images/yoga2.jpeg"
image = Image.open(img_path).resize((512, 512), Image.Resampling.BICUBIC)
pixel_values = image_processor(image, return_tensors="pt").pixel_values
with torch.no_grad():
outputs = image_segmentor(pixel_values)
seg = image_processor.post_process_semantic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
color_seg = np.zeros((seg.shape[0], seg.shape[1], 3), dtype=np.uint8) # height, width, 3
palette = np.array(ade_palette())
for label, color in enumerate(palette):
color_seg[seg == label, :] = color
color_seg = color_seg.astype(np.uint8)
color_seg = Image.fromarray(color_seg)
# Pose Estimation
pose_detector = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
pose_img = pose_detector(Image.open(img_path).resize((512, 512), Image.Resampling.BICUBIC))
# Load multiple control net
controlnet = [
ControlNetModel.from_pretrained(
"lllyasviel/sd-controlnet-seg", torch_dtype=torch.float16),
ControlNetModel.from_pretrained(
"lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16),
]
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"andite/anything-v4.0", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# Disabling safety checker
if pipe.safety_checker is not None:
pipe.safety_checker = lambda images, **kwargs: (images, False)
pipe.to(device)
# run stable diffusion
images = []
generator = torch.Generator(device)
prompt = "a kawaii girl, gym suit, 1girl, masterpiece, best quality, extremely detailed"
negative_prompt = "low quality, worst quality, bad fingers, bad face, extra arms, extra legs"
for i in range(6):
generator.manual_seed(i+1024)
image = pipe(prompt, [color_seg, pose_img], negative_prompt=negative_prompt, generator=generator,
num_inference_steps=50, output_type="numpy").images
images.append(image)
images = (np.concatenate(images, axis=0) * 255.0).astype(np.uint8)
# Concatenate images
h, w, c = images.shape[1:]
images = images.reshape(2, 3, h, w, c).swapaxes(1, 2).reshape(2*h, 3*w, c)
with Image.fromarray(images) as img:
img.save("result.jpg", quality=90)
if __name__ == "__main__":
main()
先程のyoga2.jpegで試してみます(こういう変なポーズを生成するのは一般に難しいです)

Poseのみ
奥行き情報が落ちてしまっているので、まあこうなりますねという出力です。ポーズ推定ってよく使うんですけど、情報としてはあんまり強くないんですね…
Segmentationのみ

セグメンテーション入れるとだいぶマシになりました。セグメンテーションにポーズの情報が内包されているのかもしれない
Pose+Segmentation

目線が参照画像のように上を向くようになりました。Segmentationだけでも結構できますが、Poseは顔の向きの情報も持っているので、こういう効果が期待できます。
全盛りにすればいいというわけではない
ならControlNetを全盛りにすればいいのではないか?と思うかもしませんが、うまくいかない例もありました。以下うまくいかない例です
- Depth Estimationをさらに追加する:出力画像が全部モノクロになります。Depthの出力がモノクロなので、それが引きづられてしまうようです
- NormalMapをさらに追加する:「法線マップ(Normal Map)ならカラー出力されるので良いのかな?」とおもったら、今度は人間のバリエーションが同じような感じになります。ただ立体感は出ます
ControlNetも、AttentionかなにかでDepth情報加味しながら生成してほしい感はありますよね笑 もう少ししたら、ここらへん改良されたモデルが出るのでしょうか。
全盛りがうまくいかないというのはちょっと意外でした。Seg+Poseはたまたまうまくいった例でした。
MultiControlNet+LoRAで動画生成
MultiCOntrolNet+LoRAで先程の動画をパースしてみます。プロンプトは以下のようにしました
prompt = "an illustration of a sks girl, 1girl, solo, best quality, extremely detailed"
negative_prompt = "low quality, worst quality, bad fingers, bad face, extra arms, extra legs"
結果はこちら
元動画はこれ
顔がまだだいぶおかしいですが、前のと比べるとだいぶ良くなったのではないでしょうか。セグメンテーションを入れることで、ポーズのアラインメントはかなり取れるようになりました。
まとめ
この記事ではControlNetの解説と、いろいろ試してみた結果を示しました。
ControlNetはよく聞きますが、結構奥深い内容で、ポーズ推定、セマンティックセグメンテーション、奥行き推定といった従来の画像ディープのがてんこ盛りです。そして組み合わせると強いです。ここらへんがわかる方だとかなり使いやすいと思います(逆にプロンプト叩いてるだけのエンジョイ勢はこのへんでついていくのがつらくなりそう)。
個人的には、顔のキーポイント(Facial Keypoint)や、手のキーポイント(Palm detection)のControlNetがほしくなりました。このへんのキーポイントコミコミで、Kinectと繋げばかなり未来になりそうな気がします。
あとは奥行き情報をもうちょっと総合的に使ってほしかったですね。depth2imgでMiDaS(単眼Depthモデル)使っているので、Attentionに入れたりもうちょっといろいろできるはずなんですよね。「単純にdepth2imgをパイプラインに組み込めばいいのかな?」なんて思ったりしています。MiDaSをdepth2imgだけで使ってるのはちょっともったいないような気がします
ライセンス表記:
© Unity Technologies Japan/UCL
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー