
Diffusersでモデルマージをする


Diffuserでのモデルマージを検証します。Stable Diffusionには、CLIP、U-Net、VAEの3つのモデルからなり、それぞれをマージの効果が違うので、面白い結果になります。また、CLIP(Text Encoder)のマージについても、OpenAIのものと比較検討してみます。
目次
はじめに
Stable DiffusionでどうもFine-tuningしたモデルをマージするのが流行っているらしいので試してみました。Diffusersでやる場合は、「ただPyTorchで係数マージするだけなので楽だろう」とおもったらかなり楽でした。
係数マージの研究的背景
モデルマージというのは実務的には結構よくやられていることですが、研究的にはまあまああります。私の知っている限りですが、
- Patching open-vocabulary models by interpolating weights
- Fine-tuingしたCLIP、Zero-shotのCLIPの係数を線形平均とると、Zero-shotの精度を少し犠牲にするだけで、下流タスクのFine-tuning精度が得られる。タイポグラフィ攻撃にも有効
- 自分のブログ
- Robust Fine-Tuning of Zero-Shot Models
- PAINTとほぼ同じような考え方
- ゼロショットと微調整を行ったモデルの重みをアンサンブルする方法(WiSE-FT)を導入、標準的なファインチューニングと比較して、ターゲット分布の高精度を維持したまま、分布シフトの下で大きな精度向上を実現する
- ちゃんと読めてないのが非常に申し訳ないのですが、CVPR 2022 Highlightになったすごい論文です
- Editing Models with Task Arithmetic
- 係数マージの発展形で、モデル同士の係数を比較してタスクベクトル計算することで、モデル編集やDomain Generazationを可能にするもの
- なんかさんの記事が詳しいですhttps://zenn.dev/discus0434/articles/ef418a8b0b3dc0
Stable Diffusionのモデル構成
Stabel Diffusionのモデルは、以下の3つのモデルからなります
- CLIP
- Denoising U-Net
- VAE
T2I-Adapterの図がわかりやすかったので、T2I-Adapterのリポジトリから引用します。
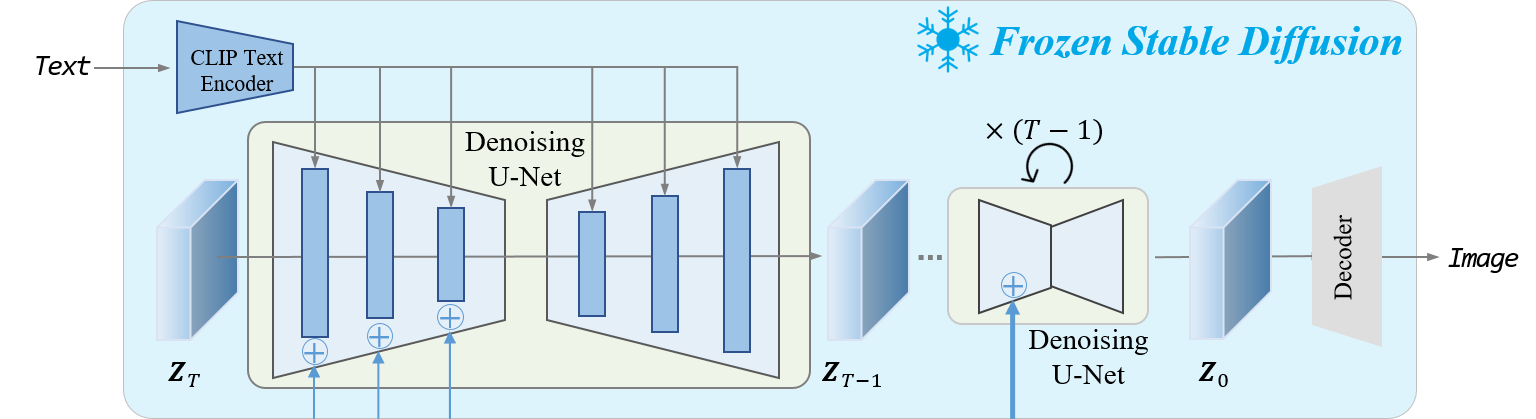
SDのCLIPはプロンプトを特徴量に変換しているだけなので、基本はFrozenではないかと思います(→実はそうではないことがわかりました)
マージできるかどうか
マージできるかどうかの判定は「モデル構造が一緒ならマージ可能」です。モデル構造が一緒かどうかはパラメーター数を見るのが簡単で、
def count_params(pipe):
num_params = 0
for k, v in pipe.unet.named_parameters():
p = np.prod([x for x in v.shape])
num_params += p
return num_params
このようにStable DiffusionのPipelineのU-Netのパラメーターを計算するのがわかりやすいと思います。SD1.5とSD2.0系では、U-Netのパラメーター数が異なるためマージできません。
U-NetとVAEをマージする
直接絵に関わりそうなのは、U-NetとVAEなので、まずはそこの部分をマージしてみます。コードは以下の通りです。
from diffusers import StableDiffusionPipeline, UniPCMultistepScheduler
import torch
import numpy as np
import copy
import torchvision
from compel import Compel
def count_params(pipe):
num_params = 0
for k, v in pipe.unet.named_parameters():
p = np.prod([x for x in v.shape])
num_params += p
return num_params
def merge_network(pipe_source, pipe_merge, attr, ratio):
merge_net = copy.deepcopy(getattr(pipe_source, attr))
pipe_source_params = dict(getattr(pipe_source, attr).named_parameters())
pipe_merge_params = dict(getattr(pipe_merge, attr).named_parameters())
for key, param in merge_net.named_parameters():
x = pipe_source_params[key] * (1-ratio) + pipe_merge_params[key] * ratio
param.data = x
return merge_net
def main():
merge_pairs = {
"journey-counter": ["prompthero/openjourney-v4", "gsdf/Counterfeit-V2.0"],
"journey-sd": ["prompthero/openjourney-v4", "runwayml/stable-diffusion-v1-5"],
"counter-journey": ["gsdf/Counterfeit-V2.0", "prompthero/openjourney-v4"],
"counter-sd": ["gsdf/Counterfeit-V2.0", "runwayml/stable-diffusion-v1-5"],
"sd-journey": ["runwayml/stable-diffusion-v1-5", "prompthero/openjourney-v4"],
"sd-counter": ["runwayml/stable-diffusion-v1-5", "gsdf/Counterfeit-V2.0"],
}
for i, (merge_key, merge_pair) in enumerate(merge_pairs.items()):
pipe1 = StableDiffusionPipeline.from_pretrained(merge_pair[0], torch_dtype=torch.float16, use_safetensors=True)
pipe1.scheduler = UniPCMultistepScheduler.from_config(pipe1.scheduler.config, use_safetensors=True)
pipe2 = StableDiffusionPipeline.from_pretrained(merge_pair[1], torch_dtype=torch.float16, use_safetensors=True)
pipe2.scheduler = UniPCMultistepScheduler.from_config(pipe2.scheduler.config, use_safetensors=True)
images = []
for unet_ratio in [0, 0.5, 1]:
for vae_ratio in [0, 0.5, 1]:
merge_unet = merge_network(pipe1, pipe2, "unet", unet_ratio)
merge_vae = merge_network(pipe1, pipe2, "vae", vae_ratio)
merge_pipe = StableDiffusionPipeline(
vae=merge_vae,
text_encoder=pipe1.text_encoder,
tokenizer=pipe1.tokenizer,
unet=merge_unet,
scheduler=UniPCMultistepScheduler.from_config(pipe1.scheduler.config),
safety_checker=lambda images, **kwargs: (images, False),
feature_extractor=pipe1.feature_extractor
)
device = "cuda:1"
generator = torch.Generator(device).manual_seed(1234)
prompt = "1girl++++, solo, traveler, rule of thirds, teens, dress++, silver hair, side view, face in profile, praying, anime face, stand on a high hill, "\
"looking down into distance, pasture, flower garden, small town, sunshine, clear sky, flowing clouds, masterpiece, best quality, detailed face"
negative_prompt = "longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, multiple girls, multiple people"
merge_pipe.to(device)
compel_proc = Compel(tokenizer=merge_pipe.tokenizer, text_encoder=merge_pipe.text_encoder)
conditioning = compel_proc(prompt)
neg_conditioning = compel_proc(negative_prompt)
image = merge_pipe(prompt_embeds=conditioning, negative_prompt_embeds=neg_conditioning, generator=generator, output_type="numpy", num_images_per_prompt=1, width=512, height=768).images
images.append(image)
images = np.concatenate(images)
images = torch.from_numpy(images).permute(0, 3, 1, 2)
torchvision.utils.save_image(images, f"merge_{i}_{merge_key}.jpg", quality=92, nrow=3, normalize=False)
if __name__ == "__main__":
main()
Compelを入れてプロンプトに重み付けできるようにしています。
結果の見方
結果の見方は以下の通りです。
「A-B」という形でモデルマージしたとして、
| VAE 0 | VAE 0.5 | VAE 1 | |
|---|---|---|---|
| U-Net 0 | U-Net A:B=1:0 VAE A:B=1:0 |
U-Net A:B=1:0 VAE A:B=0.5:0.5 |
U-Net A:B=1:0 VAE A:B=0:1 |
| U-Net 0.5 | U-Net A:B=0.5:0.5 VAE A:B=1:0 |
U-Net A:B=0.5:0.5 VAE A:B=0.5:0.5 |
U-Net A:B=0.5:0.5 VAE A:B=0:1 |
| U-Net 1 | U-Net A:B=0:1 VAE A:B=1:0 |
U-Net A:B=0:1 VAE A:B=0.5:0.5 |
U-Net A:B=0:1 VAE A:B=0:1 |
とします。横がVAEの変化で、縦がU-Netの変化です。
マージするモデル
3つのモデルを全パターンでマージしてみます。
- OpenJourneyV4 : https://huggingface.co/prompthero/openjourney-v4
- Counterfeit-V2.0 : https://huggingface.co/gsdf/Counterfeit-V2.0
- runwayml/stable-diffusion-v1-5 : https://huggingface.co/runwayml/stable-diffusion-v1-5
これらはすべてモデル構造が等しいので、マージ可能です。
merge_pairs = {
"journey-counter": ["prompthero/openjourney-v4", "gsdf/Counterfeit-V2.0"],
"journey-sd": ["prompthero/openjourney-v4", "runwayml/stable-diffusion-v1-5"],
"counter-journey": ["gsdf/Counterfeit-V2.0", "prompthero/openjourney-v4"],
"counter-sd": ["gsdf/Counterfeit-V2.0", "runwayml/stable-diffusion-v1-5"],
"sd-journey": ["runwayml/stable-diffusion-v1-5", "prompthero/openjourney-v4"],
"sd-counter": ["runwayml/stable-diffusion-v1-5", "gsdf/Counterfeit-V2.0"],
}
このように6通りの組み合わせが考えられます。
ケース1:「OpenJourneyV4 : Counterfeit-V2.0」

OpenJourneyのハイコントラストな感じから、Counterfeitの淡い感じに移っていきました。U-Netを半々ぐらいでマージすると背景がいい感じになりますね。
ケース2:「OpenJourneyV4 : StableDiffusionV1.5」

ちょっとこれがおかしな結果です。Stable Diffusionでは実写のほうが入っているため、右下のようなケースはかなり実写に近くならなんくてはいけません。なので、マージしていないCLIPの部分になにかトリックがあるのだと思います。
ケース3:「Counterfeit-V2.0 : OpenJourneyV4」

ケース1のSourceとTargetを入れ替えた例です。同じアニメが得意なもの同士なので、違和感は特にないです。CounterfeitはデフォルトのVAEがあまりよくなく、OpenJourneyのVAEを使ってあげるといい感じになりそうですね。VAEはモデル関係なく好きなの使っても良さそうです。
ケース4:「Counterfeit-V2.0 : StableDiffusionV1.5」

フルマージすると、実写にいきました。OpenJourneyがちょっとおかしいのかもしれません。SDのVAEはなかなかで、実写っぽいタッチのアニメ絵を書きたいときはSDのVAEを使ってもいいかもしれません。
ケース5:「StableDiffusionV1.5:OpenJourneyV4」

ベースがSDなので、左上→右下でアニメ調に映るはずです。このケースでは、CLIP(Text Encoder)はSD1.5のを使っていますが、アニメに特化したCLIPでなくても大丈夫そうですね。
CLIPって広範囲のデータで学習したほうがいいものができる(と勝手に思っている)ので、ここをFine-tuningしてしまうと、破滅的忘却の影響が出てあんまりよくないと思います。
ケース2の逆のケースですが、こっちのほうがプロンプトの意味をちゃんと解釈してそうなので、OpenJourneyのCLIPがちょっとおかしいのかもしれません。
ケース6:「StableDiffusionV1.5:Counterfeit-V2.0」

これも納得行く結果になりました。Counterfeit-V2.0はVAEを別なのに置き換えてみると良さそうです。
わかったこと
以下のことがわかりました
- U-Netはやはり構図のコントロールに非常に効いている
- VAEは彩度とかくすみとか低レベルの特徴しか動かないので、好きなの使って良さそう
- CLIPがFine-tuningされているかどうかがものすごく怪しい
U-NetとCLIPのマージをする
今度はU-NetとCLIPでマージしてみます。結果の見方は以下のようになります。VAEはStable Diffusion1.5ので固定します。
| CLIP 0 | CLIP 0.5 | CLIP 1 | |
|---|---|---|---|
| U-Net 0 | U-Net A:B=1:0 CLIP A:B=1:0 |
U-Net A:B=1:0 CLIP A:B=0.5:0.5 |
U-Net A:B=1:0 CLIP A:B=0:1 |
| U-Net 0.5 | U-Net A:B=0.5:0.5 CLIP A:B=1:0 |
U-Net A:B=0.5:0.5 CLIP A:B=0.5:0.5 |
U-Net A:B=0.5:0.5 CLIP A:B=0:1 |
| U-Net 1 | U-Net A:B=0:1 CLIP A:B=1:0 |
U-Net A:B=0:1 CLIP A:B=0.5:0.5 |
U-Net A:B=0:1 CLIP A:B=0:1 |
コード
コードはこのようになります
def main_clip():
merge_pairs = {
"journey-counter": ["prompthero/openjourney-v4", "gsdf/Counterfeit-V2.0"],
"journey-sd": ["prompthero/openjourney-v4", "runwayml/stable-diffusion-v1-5"],
"counter-journey": ["gsdf/Counterfeit-V2.0", "prompthero/openjourney-v4"],
"counter-sd": ["gsdf/Counterfeit-V2.0", "runwayml/stable-diffusion-v1-5"],
"sd-journey": ["runwayml/stable-diffusion-v1-5", "prompthero/openjourney-v4"],
"sd-counter": ["runwayml/stable-diffusion-v1-5", "gsdf/Counterfeit-V2.0"],
}
base_pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True)
for i, (merge_key, merge_pair) in enumerate(merge_pairs.items()):
pipe1 = StableDiffusionPipeline.from_pretrained(merge_pair[0], torch_dtype=torch.float16, use_safetensors=True)
pipe1.scheduler = UniPCMultistepScheduler.from_config(pipe1.scheduler.config, use_safetensors=True)
pipe2 = StableDiffusionPipeline.from_pretrained(merge_pair[1], torch_dtype=torch.float16, use_safetensors=True)
pipe2.scheduler = UniPCMultistepScheduler.from_config(pipe2.scheduler.config, use_safetensors=True)
images = []
for unet_ratio in [0, 0.5, 1]:
for clip_ratio in [0, 0.5, 1]:
merge_unet = merge_network(pipe1, pipe2, "unet", unet_ratio)
merge_clip = merge_network(pipe1, pipe2, "text_encoder", clip_ratio)
merge_pipe = StableDiffusionPipeline(
vae=base_pipe.vae,
text_encoder=merge_clip,
tokenizer=pipe1.tokenizer,
unet=merge_unet,
scheduler=UniPCMultistepScheduler.from_config(pipe1.scheduler.config),
safety_checker=lambda images, **kwargs: (images, False),
feature_extractor=pipe1.feature_extractor
)
device = "cuda:1"
generator = torch.Generator(device).manual_seed(1234)
prompt = "1girl++++, solo, traveler, rule of thirds, teens, dress++, silver hair, side view, face in profile, praying, anime face, stand on a high hill, "\
"looking down into distance, pasture, flower garden, small town, sunshine, clear sky, flowing clouds, masterpiece, best quality, detailed face"
negative_prompt = "longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, multiple girls, multiple people"
merge_pipe.to(device)
compel_proc = Compel(tokenizer=merge_pipe.tokenizer, text_encoder=merge_pipe.text_encoder)
conditioning = compel_proc(prompt)
neg_conditioning = compel_proc(negative_prompt)
image = merge_pipe(prompt_embeds=conditioning, negative_prompt_embeds=neg_conditioning, generator=generator, output_type="numpy", num_images_per_prompt=1, width=512, height=768).images
images.append(image)
images = np.concatenate(images)
images = torch.from_numpy(images).permute(0, 3, 1, 2)
torchvision.utils.save_image(images, f"merge_{i+10}_{merge_key}.jpg", quality=92, nrow=3, normalize=False)
ベースとターゲットを入れ替えて同じことが成立するか?
先ほどは(U-NetとVAEのマージ)、
- 「ベースをOpenJourney」「マージターゲットをStable Diffusion」の結果
- 「ベースをStable Diffusion」「マージターゲットをOpenJourney」の結果
に一貫性がありませんでした。今回はどうでしょうか?
ケース2:「OpenJourneyV4 : StableDiffusionV1.5」

ケース5:「StableDiffusionV1.5:OpenJourneyV4」

このようにそれぞれ反転した結果となり,一貫性が保証されました。つまり、CLIPのFine-tuningも行われており、CLIP空間の変化が画風や構図・細部の変化をもたらしていたというこのを表します。
面白いのがケース2の下段のケースで、U-Netを完全にSDのものにしても(マージ比率1)、CLIPがOpenJourneyのもの(マージ比率0)、半々マージ(マージ比率0.5)ならアニメ調のままということです。
もちろんマージのケースでは、前景の芝桜の部分が後ろの背景に転移していたり、ちょっとおかしいところはあります。しかし、画風のコントロールの支配的な部分はU-Netではなく、CLIPということが示唆されます。したがって、CLIP部分にAdapter的なアフィン変換のレイヤーを追加して、他全部フリーズして訓練してもある程度行けるのではないかと思われます。
ケース1:「OpenJourneyV4 : Counterfeit-V2.0」
他のケースも見ていきましょう。ソースとターゲットを反転しても同じなので、特定の組み合わせのみみます。

U-NetとCLIPの効きが面白いように相互作用かかっています。U-Netでカメラアングルが変わるのは納得ですが、CLIPを変えると髪型や服装が微妙に変わっていくのが面白いですね。
ケース4:「Counterfeit-V2.0 : StableDiffusionV1.5」

CLIPがポーズに効いているのが面白いですね。多分モデルのバイアスなのではないかと思います。
2段目の右のように、CLIPを完全にSDにしてしまうと、牧草地のプロンプトがもう少し強く出ています。
OpenAIのCLIPとマージする
ここであることに気づきます。元のOpenAIのCLIPってものすごいEmbeddingいいんだから、そっちとマージしちゃえばいいやん。
SD1.5で使っているCLIPはなにか
SD1.5で使っているCLIPはなにかを探す必要があります。いまいち情報なくてソースコード買得したのですが、「openai/clip-vit-large-patch14」でした。
class FrozenCLIPEmbedder(AbstractEncoder):
"""Uses the CLIP transformer encoder for text (from Hugging Face)"""
def __init__(self, version="openai/clip-vit-large-patch14", device="cuda", max_length=77):
super().__init__()
self.tokenizer = CLIPTokenizer.from_pretrained(version)
self.transformer = CLIPTextModel.from_pretrained(version)
self.device = device
self.max_length = max_length
self.freeze()
SD1.5のソースよりです。見てわかるように、本来のSDってCLIP部分はフリーズしているので、CLIP部分に影響が出ることは基本ないはずなんですよね…
パラメーターチェック
マージできるか調べていきましょう。このようにStable DiffusionとOpenAI CLIP間で、係数とパラメーター名があっているかどうかチェックします。
from diffusers import StableDiffusionPipeline, UniPCMultistepScheduler
import torch
import numpy as np
import copy
import torchvision
from compel import Compel
from transformers import CLIPModel
def count_params(pipe):
num_params = 0
for k, v in pipe.named_parameters():
p = np.prod([x for x in v.shape])
num_params += p
return num_params
def check_models():
pipe1 = StableDiffusionPipeline.from_pretrained("prompthero/openjourney-v4", torch_dtype=torch.float16, use_safetensors=True)
model = CLIPModel.from_pretrained("openai/clip-vit-large-patch14")
print("--num parameters --")
print(count_params(model.text_model))
print(count_params(pipe1.text_encoder))
print("--named parameters --")
param_name_sd = list(k for k, _ in pipe1.text_encoder.named_parameters())
param_name_clip = list(k for k, _ in model.text_model.named_parameters())
print(param_name_sd)
print(param_name_clip)
print("-- is same name ?")
print(all([s == "text_model."+c for s, c in zip(param_name_sd, param_name_clip)]))
結果は以下のようになります。
--num parameters --
123060480
123060480
--named parameters --
['text_model.embeddings.token_embedding.weight', 'text_model.embeddings.position_embedding.weight', 'text_model.encoder.layers.0.self_attn.k_proj.weight', 'text_model.encoder.layers.0.self_attn.k_proj.bias', 'text_model.encoder.layers.0.self_attn.v_proj.weight', 'text_model.encoder.layers.0.self_attn.v_proj.bias', 'text_model.encoder.layers.0.self_attn.q_proj.weight', 'text_model.encoder.layers.0.self_attn.q_proj.bias', 'text_model.encoder.layers.0.self_attn.out_proj.weight', 'text_model.encoder.layers.0.self_attn.out_proj.bias', 'text_model.encoder.layers.0.layer_norm1.weight', 'text_model.encoder.layers.0.layer_norm1.bias', 'text_model.encoder.layers.0.mlp.fc1.weight', 'text_model.encoder.layers.0.mlp.fc1.bias', 'text_model.encoder.layers.0.mlp.fc2.weight', 'text_model.encoder.layers.0.mlp.fc2.bias', 'text_model.encoder.layers.0.layer_norm2.weight', 'text_model.encoder.layers.0.layer_norm2.bias', 'text_model.encoder.layers.1.self_attn.k_proj.weight', 'text_model.encoder.layers.1.self_attn.k_proj.bias', 'text_model.encoder.layers.1.self_attn.v_proj.weight', 'text_model.encoder.layers.1.self_attn.v_proj.bias', 'text_model.encoder.layers.1.self_attn.q_proj.weight', 'text_model.encoder.layers.1.self_attn.q_proj.bias', 'text_model.encoder.layers.1.self_attn.out_proj.weight', 'text_model.encoder.layers.1.self_attn.out_proj.bias', 'text_model.encoder.layers.1.layer_norm1.weight', 'text_model.encoder.layers.1.layer_norm1.bias', 'text_model.encoder.layers.1.mlp.fc1.weight', 'text_model.encoder.layers.1.mlp.fc1.bias', 'text_model.encoder.layers.1.mlp.fc2.weight', 'text_model.encoder.layers.1.mlp.fc2.bias', 'text_model.encoder.layers.1.layer_norm2.weight', 'text_model.encoder.layers.1.layer_norm2.bias', 'text_model.encoder.layers.2.self_attn.k_proj.weight', 'text_model.encoder.layers.2.self_attn.k_proj.bias', 'text_model.encoder.layers.2.self_attn.v_proj.weight', 'text_model.encoder.layers.2.self_attn.v_proj.bias', 'text_model.encoder.layers.2.self_attn.q_proj.weight', 'text_model.encoder.layers.2.self_attn.q_proj.bias', 'text_model.encoder.layers.2.self_attn.out_proj.weight', 'text_model.encoder.layers.2.self_attn.out_proj.bias', 'text_model.encoder.layers.2.layer_norm1.weight', 'text_model.encoder.layers.2.layer_norm1.bias', 'text_model.encoder.layers.2.mlp.fc1.weight', 'text_model.encoder.layers.2.mlp.fc1.bias', 'text_model.encoder.layers.2.mlp.fc2.weight', 'text_model.encoder.layers.2.mlp.fc2.bias', 'text_model.encoder.layers.2.layer_norm2.weight', 'text_model.encoder.layers.2.layer_norm2.bias', 'text_model.encoder.layers.3.self_attn.k_proj.weight', 'text_model.encoder.layers.3.self_attn.k_proj.bias', 'text_model.encoder.layers.3.self_attn.v_proj.weight', 'text_model.encoder.layers.3.self_attn.v_proj.bias', 'text_model.encoder.layers.3.self_attn.q_proj.weight', 'text_model.encoder.layers.3.self_attn.q_proj.bias', 'text_model.encoder.layers.3.self_attn.out_proj.weight', 'text_model.encoder.layers.3.self_attn.out_proj.bias', 'text_model.encoder.layers.3.layer_norm1.weight', 'text_model.encoder.layers.3.layer_norm1.bias', 'text_model.encoder.layers.3.mlp.fc1.weight', 'text_model.encoder.layers.3.mlp.fc1.bias', 'text_model.encoder.layers.3.mlp.fc2.weight', 'text_model.encoder.layers.3.mlp.fc2.bias', 'text_model.encoder.layers.3.layer_norm2.weight', 'text_model.encoder.layers.3.layer_norm2.bias', 'text_model.encoder.layers.4.self_attn.k_proj.weight', 'text_model.encoder.layers.4.self_attn.k_proj.bias', 'text_model.encoder.layers.4.self_attn.v_proj.weight', 'text_model.encoder.layers.4.self_attn.v_proj.bias', 'text_model.encoder.layers.4.self_attn.q_proj.weight', 'text_model.encoder.layers.4.self_attn.q_proj.bias', 'text_model.encoder.layers.4.self_attn.out_proj.weight', 'text_model.encoder.layers.4.self_attn.out_proj.bias', 'text_model.encoder.layers.4.layer_norm1.weight', 'text_model.encoder.layers.4.layer_norm1.bias', 'text_model.encoder.layers.4.mlp.fc1.weight', 'text_model.encoder.layers.4.mlp.fc1.bias', 'text_model.encoder.layers.4.mlp.fc2.weight', 'text_model.encoder.layers.4.mlp.fc2.bias', 'text_model.encoder.layers.4.layer_norm2.weight', 'text_model.encoder.layers.4.layer_norm2.bias', 'text_model.encoder.layers.5.self_attn.k_proj.weight', 'text_model.encoder.layers.5.self_attn.k_proj.bias', 'text_model.encoder.layers.5.self_attn.v_proj.weight', 'text_model.encoder.layers.5.self_attn.v_proj.bias', 'text_model.encoder.layers.5.self_attn.q_proj.weight', 'text_model.encoder.layers.5.self_attn.q_proj.bias', 'text_model.encoder.layers.5.self_attn.out_proj.weight', 'text_model.encoder.layers.5.self_attn.out_proj.bias', 'text_model.encoder.layers.5.layer_norm1.weight', 'text_model.encoder.layers.5.layer_norm1.bias', 'text_model.encoder.layers.5.mlp.fc1.weight', 'text_model.encoder.layers.5.mlp.fc1.bias', 'text_model.encoder.layers.5.mlp.fc2.weight', 'text_model.encoder.layers.5.mlp.fc2.bias', 'text_model.encoder.layers.5.layer_norm2.weight', 'text_model.encoder.layers.5.layer_norm2.bias', 'text_model.encoder.layers.6.self_attn.k_proj.weight', 'text_model.encoder.layers.6.self_attn.k_proj.bias', 'text_model.encoder.layers.6.self_attn.v_proj.weight', 'text_model.encoder.layers.6.self_attn.v_proj.bias', 'text_model.encoder.layers.6.self_attn.q_proj.weight', 'text_model.encoder.layers.6.self_attn.q_proj.bias', 'text_model.encoder.layers.6.self_attn.out_proj.weight', 'text_model.encoder.layers.6.self_attn.out_proj.bias', 'text_model.encoder.layers.6.layer_norm1.weight', 'text_model.encoder.layers.6.layer_norm1.bias', 'text_model.encoder.layers.6.mlp.fc1.weight', 'text_model.encoder.layers.6.mlp.fc1.bias', 'text_model.encoder.layers.6.mlp.fc2.weight', 'text_model.encoder.layers.6.mlp.fc2.bias', 'text_model.encoder.layers.6.layer_norm2.weight', 'text_model.encoder.layers.6.layer_norm2.bias', 'text_model.encoder.layers.7.self_attn.k_proj.weight', 'text_model.encoder.layers.7.self_attn.k_proj.bias', 'text_model.encoder.layers.7.self_attn.v_proj.weight', 'text_model.encoder.layers.7.self_attn.v_proj.bias', 'text_model.encoder.layers.7.self_attn.q_proj.weight', 'text_model.encoder.layers.7.self_attn.q_proj.bias', 'text_model.encoder.layers.7.self_attn.out_proj.weight', 'text_model.encoder.layers.7.self_attn.out_proj.bias', 'text_model.encoder.layers.7.layer_norm1.weight', 'text_model.encoder.layers.7.layer_norm1.bias', 'text_model.encoder.layers.7.mlp.fc1.weight', 'text_model.encoder.layers.7.mlp.fc1.bias', 'text_model.encoder.layers.7.mlp.fc2.weight', 'text_model.encoder.layers.7.mlp.fc2.bias', 'text_model.encoder.layers.7.layer_norm2.weight', 'text_model.encoder.layers.7.layer_norm2.bias', 'text_model.encoder.layers.8.self_attn.k_proj.weight', 'text_model.encoder.layers.8.self_attn.k_proj.bias', 'text_model.encoder.layers.8.self_attn.v_proj.weight', 'text_model.encoder.layers.8.self_attn.v_proj.bias', 'text_model.encoder.layers.8.self_attn.q_proj.weight', 'text_model.encoder.layers.8.self_attn.q_proj.bias', 'text_model.encoder.layers.8.self_attn.out_proj.weight', 'text_model.encoder.layers.8.self_attn.out_proj.bias', 'text_model.encoder.layers.8.layer_norm1.weight', 'text_model.encoder.layers.8.layer_norm1.bias', 'text_model.encoder.layers.8.mlp.fc1.weight', 'text_model.encoder.layers.8.mlp.fc1.bias', 'text_model.encoder.layers.8.mlp.fc2.weight', 'text_model.encoder.layers.8.mlp.fc2.bias', 'text_model.encoder.layers.8.layer_norm2.weight', 'text_model.encoder.layers.8.layer_norm2.bias', 'text_model.encoder.layers.9.self_attn.k_proj.weight', 'text_model.encoder.layers.9.self_attn.k_proj.bias', 'text_model.encoder.layers.9.self_attn.v_proj.weight', 'text_model.encoder.layers.9.self_attn.v_proj.bias', 'text_model.encoder.layers.9.self_attn.q_proj.weight', 'text_model.encoder.layers.9.self_attn.q_proj.bias', 'text_model.encoder.layers.9.self_attn.out_proj.weight', 'text_model.encoder.layers.9.self_attn.out_proj.bias', 'text_model.encoder.layers.9.layer_norm1.weight', 'text_model.encoder.layers.9.layer_norm1.bias', 'text_model.encoder.layers.9.mlp.fc1.weight', 'text_model.encoder.layers.9.mlp.fc1.bias', 'text_model.encoder.layers.9.mlp.fc2.weight', 'text_model.encoder.layers.9.mlp.fc2.bias', 'text_model.encoder.layers.9.layer_norm2.weight', 'text_model.encoder.layers.9.layer_norm2.bias', 'text_model.encoder.layers.10.self_attn.k_proj.weight', 'text_model.encoder.layers.10.self_attn.k_proj.bias', 'text_model.encoder.layers.10.self_attn.v_proj.weight', 'text_model.encoder.layers.10.self_attn.v_proj.bias', 'text_model.encoder.layers.10.self_attn.q_proj.weight', 'text_model.encoder.layers.10.self_attn.q_proj.bias', 'text_model.encoder.layers.10.self_attn.out_proj.weight', 'text_model.encoder.layers.10.self_attn.out_proj.bias', 'text_model.encoder.layers.10.layer_norm1.weight', 'text_model.encoder.layers.10.layer_norm1.bias', 'text_model.encoder.layers.10.mlp.fc1.weight', 'text_model.encoder.layers.10.mlp.fc1.bias', 'text_model.encoder.layers.10.mlp.fc2.weight', 'text_model.encoder.layers.10.mlp.fc2.bias', 'text_model.encoder.layers.10.layer_norm2.weight', 'text_model.encoder.layers.10.layer_norm2.bias', 'text_model.encoder.layers.11.self_attn.k_proj.weight', 'text_model.encoder.layers.11.self_attn.k_proj.bias', 'text_model.encoder.layers.11.self_attn.v_proj.weight', 'text_model.encoder.layers.11.self_attn.v_proj.bias', 'text_model.encoder.layers.11.self_attn.q_proj.weight', 'text_model.encoder.layers.11.self_attn.q_proj.bias', 'text_model.encoder.layers.11.self_attn.out_proj.weight', 'text_model.encoder.layers.11.self_attn.out_proj.bias', 'text_model.encoder.layers.11.layer_norm1.weight', 'text_model.encoder.layers.11.layer_norm1.bias', 'text_model.encoder.layers.11.mlp.fc1.weight', 'text_model.encoder.layers.11.mlp.fc1.bias', 'text_model.encoder.layers.11.mlp.fc2.weight', 'text_model.encoder.layers.11.mlp.fc2.bias', 'text_model.encoder.layers.11.layer_norm2.weight', 'text_model.encoder.layers.11.layer_norm2.bias', 'text_model.final_layer_norm.weight', 'text_model.final_layer_norm.bias']
['embeddings.token_embedding.weight', 'embeddings.position_embedding.weight', 'encoder.layers.0.self_attn.k_proj.weight', 'encoder.layers.0.self_attn.k_proj.bias', 'encoder.layers.0.self_attn.v_proj.weight', 'encoder.layers.0.self_attn.v_proj.bias', 'encoder.layers.0.self_attn.q_proj.weight', 'encoder.layers.0.self_attn.q_proj.bias', 'encoder.layers.0.self_attn.out_proj.weight', 'encoder.layers.0.self_attn.out_proj.bias', 'encoder.layers.0.layer_norm1.weight', 'encoder.layers.0.layer_norm1.bias', 'encoder.layers.0.mlp.fc1.weight', 'encoder.layers.0.mlp.fc1.bias', 'encoder.layers.0.mlp.fc2.weight', 'encoder.layers.0.mlp.fc2.bias', 'encoder.layers.0.layer_norm2.weight', 'encoder.layers.0.layer_norm2.bias', 'encoder.layers.1.self_attn.k_proj.weight', 'encoder.layers.1.self_attn.k_proj.bias', 'encoder.layers.1.self_attn.v_proj.weight', 'encoder.layers.1.self_attn.v_proj.bias', 'encoder.layers.1.self_attn.q_proj.weight', 'encoder.layers.1.self_attn.q_proj.bias', 'encoder.layers.1.self_attn.out_proj.weight', 'encoder.layers.1.self_attn.out_proj.bias', 'encoder.layers.1.layer_norm1.weight', 'encoder.layers.1.layer_norm1.bias', 'encoder.layers.1.mlp.fc1.weight', 'encoder.layers.1.mlp.fc1.bias', 'encoder.layers.1.mlp.fc2.weight', 'encoder.layers.1.mlp.fc2.bias', 'encoder.layers.1.layer_norm2.weight', 'encoder.layers.1.layer_norm2.bias', 'encoder.layers.2.self_attn.k_proj.weight', 'encoder.layers.2.self_attn.k_proj.bias', 'encoder.layers.2.self_attn.v_proj.weight', 'encoder.layers.2.self_attn.v_proj.bias', 'encoder.layers.2.self_attn.q_proj.weight', 'encoder.layers.2.self_attn.q_proj.bias', 'encoder.layers.2.self_attn.out_proj.weight', 'encoder.layers.2.self_attn.out_proj.bias', 'encoder.layers.2.layer_norm1.weight', 'encoder.layers.2.layer_norm1.bias', 'encoder.layers.2.mlp.fc1.weight', 'encoder.layers.2.mlp.fc1.bias', 'encoder.layers.2.mlp.fc2.weight', 'encoder.layers.2.mlp.fc2.bias', 'encoder.layers.2.layer_norm2.weight', 'encoder.layers.2.layer_norm2.bias', 'encoder.layers.3.self_attn.k_proj.weight', 'encoder.layers.3.self_attn.k_proj.bias', 'encoder.layers.3.self_attn.v_proj.weight', 'encoder.layers.3.self_attn.v_proj.bias', 'encoder.layers.3.self_attn.q_proj.weight', 'encoder.layers.3.self_attn.q_proj.bias', 'encoder.layers.3.self_attn.out_proj.weight', 'encoder.layers.3.self_attn.out_proj.bias', 'encoder.layers.3.layer_norm1.weight', 'encoder.layers.3.layer_norm1.bias', 'encoder.layers.3.mlp.fc1.weight', 'encoder.layers.3.mlp.fc1.bias', 'encoder.layers.3.mlp.fc2.weight', 'encoder.layers.3.mlp.fc2.bias', 'encoder.layers.3.layer_norm2.weight', 'encoder.layers.3.layer_norm2.bias', 'encoder.layers.4.self_attn.k_proj.weight', 'encoder.layers.4.self_attn.k_proj.bias', 'encoder.layers.4.self_attn.v_proj.weight', 'encoder.layers.4.self_attn.v_proj.bias', 'encoder.layers.4.self_attn.q_proj.weight', 'encoder.layers.4.self_attn.q_proj.bias', 'encoder.layers.4.self_attn.out_proj.weight', 'encoder.layers.4.self_attn.out_proj.bias', 'encoder.layers.4.layer_norm1.weight', 'encoder.layers.4.layer_norm1.bias', 'encoder.layers.4.mlp.fc1.weight', 'encoder.layers.4.mlp.fc1.bias', 'encoder.layers.4.mlp.fc2.weight', 'encoder.layers.4.mlp.fc2.bias', 'encoder.layers.4.layer_norm2.weight', 'encoder.layers.4.layer_norm2.bias', 'encoder.layers.5.self_attn.k_proj.weight', 'encoder.layers.5.self_attn.k_proj.bias', 'encoder.layers.5.self_attn.v_proj.weight', 'encoder.layers.5.self_attn.v_proj.bias', 'encoder.layers.5.self_attn.q_proj.weight', 'encoder.layers.5.self_attn.q_proj.bias', 'encoder.layers.5.self_attn.out_proj.weight', 'encoder.layers.5.self_attn.out_proj.bias', 'encoder.layers.5.layer_norm1.weight', 'encoder.layers.5.layer_norm1.bias', 'encoder.layers.5.mlp.fc1.weight', 'encoder.layers.5.mlp.fc1.bias', 'encoder.layers.5.mlp.fc2.weight', 'encoder.layers.5.mlp.fc2.bias', 'encoder.layers.5.layer_norm2.weight', 'encoder.layers.5.layer_norm2.bias', 'encoder.layers.6.self_attn.k_proj.weight', 'encoder.layers.6.self_attn.k_proj.bias', 'encoder.layers.6.self_attn.v_proj.weight', 'encoder.layers.6.self_attn.v_proj.bias', 'encoder.layers.6.self_attn.q_proj.weight', 'encoder.layers.6.self_attn.q_proj.bias', 'encoder.layers.6.self_attn.out_proj.weight', 'encoder.layers.6.self_attn.out_proj.bias', 'encoder.layers.6.layer_norm1.weight', 'encoder.layers.6.layer_norm1.bias', 'encoder.layers.6.mlp.fc1.weight', 'encoder.layers.6.mlp.fc1.bias', 'encoder.layers.6.mlp.fc2.weight', 'encoder.layers.6.mlp.fc2.bias', 'encoder.layers.6.layer_norm2.weight', 'encoder.layers.6.layer_norm2.bias', 'encoder.layers.7.self_attn.k_proj.weight', 'encoder.layers.7.self_attn.k_proj.bias', 'encoder.layers.7.self_attn.v_proj.weight', 'encoder.layers.7.self_attn.v_proj.bias', 'encoder.layers.7.self_attn.q_proj.weight', 'encoder.layers.7.self_attn.q_proj.bias', 'encoder.layers.7.self_attn.out_proj.weight', 'encoder.layers.7.self_attn.out_proj.bias', 'encoder.layers.7.layer_norm1.weight', 'encoder.layers.7.layer_norm1.bias', 'encoder.layers.7.mlp.fc1.weight', 'encoder.layers.7.mlp.fc1.bias', 'encoder.layers.7.mlp.fc2.weight', 'encoder.layers.7.mlp.fc2.bias', 'encoder.layers.7.layer_norm2.weight', 'encoder.layers.7.layer_norm2.bias', 'encoder.layers.8.self_attn.k_proj.weight', 'encoder.layers.8.self_attn.k_proj.bias', 'encoder.layers.8.self_attn.v_proj.weight', 'encoder.layers.8.self_attn.v_proj.bias', 'encoder.layers.8.self_attn.q_proj.weight', 'encoder.layers.8.self_attn.q_proj.bias', 'encoder.layers.8.self_attn.out_proj.weight', 'encoder.layers.8.self_attn.out_proj.bias', 'encoder.layers.8.layer_norm1.weight', 'encoder.layers.8.layer_norm1.bias', 'encoder.layers.8.mlp.fc1.weight', 'encoder.layers.8.mlp.fc1.bias', 'encoder.layers.8.mlp.fc2.weight', 'encoder.layers.8.mlp.fc2.bias', 'encoder.layers.8.layer_norm2.weight', 'encoder.layers.8.layer_norm2.bias', 'encoder.layers.9.self_attn.k_proj.weight', 'encoder.layers.9.self_attn.k_proj.bias', 'encoder.layers.9.self_attn.v_proj.weight', 'encoder.layers.9.self_attn.v_proj.bias', 'encoder.layers.9.self_attn.q_proj.weight', 'encoder.layers.9.self_attn.q_proj.bias', 'encoder.layers.9.self_attn.out_proj.weight', 'encoder.layers.9.self_attn.out_proj.bias', 'encoder.layers.9.layer_norm1.weight', 'encoder.layers.9.layer_norm1.bias', 'encoder.layers.9.mlp.fc1.weight', 'encoder.layers.9.mlp.fc1.bias', 'encoder.layers.9.mlp.fc2.weight', 'encoder.layers.9.mlp.fc2.bias', 'encoder.layers.9.layer_norm2.weight', 'encoder.layers.9.layer_norm2.bias', 'encoder.layers.10.self_attn.k_proj.weight', 'encoder.layers.10.self_attn.k_proj.bias', 'encoder.layers.10.self_attn.v_proj.weight', 'encoder.layers.10.self_attn.v_proj.bias', 'encoder.layers.10.self_attn.q_proj.weight', 'encoder.layers.10.self_attn.q_proj.bias', 'encoder.layers.10.self_attn.out_proj.weight', 'encoder.layers.10.self_attn.out_proj.bias', 'encoder.layers.10.layer_norm1.weight', 'encoder.layers.10.layer_norm1.bias', 'encoder.layers.10.mlp.fc1.weight', 'encoder.layers.10.mlp.fc1.bias', 'encoder.layers.10.mlp.fc2.weight', 'encoder.layers.10.mlp.fc2.bias', 'encoder.layers.10.layer_norm2.weight', 'encoder.layers.10.layer_norm2.bias', 'encoder.layers.11.self_attn.k_proj.weight', 'encoder.layers.11.self_attn.k_proj.bias', 'encoder.layers.11.self_attn.v_proj.weight', 'encoder.layers.11.self_attn.v_proj.bias', 'encoder.layers.11.self_attn.q_proj.weight', 'encoder.layers.11.self_attn.q_proj.bias', 'encoder.layers.11.self_attn.out_proj.weight', 'encoder.layers.11.self_attn.out_proj.bias', 'encoder.layers.11.layer_norm1.weight', 'encoder.layers.11.layer_norm1.bias', 'encoder.layers.11.mlp.fc1.weight', 'encoder.layers.11.mlp.fc1.bias', 'encoder.layers.11.mlp.fc2.weight', 'encoder.layers.11.mlp.fc2.bias', 'encoder.layers.11.layer_norm2.weight', 'encoder.layers.11.layer_norm2.bias', 'final_layer_norm.weight', 'final_layer_norm.bias']
-- is same name ?
True
係数サイズも名前も一緒なので(ちょっといじる必要ありますが)、マージできるということになります。
OpenAI CLIPのText Encoderをマージしていく
やり方はこれまでと同じです。
def merge_clip_parameters(pipe_source, openai_clip, ratio):
merge_net = copy.deepcopy(getattr(pipe_source, "text_encoder"))
pipe_source_params = dict(getattr(pipe_source, "text_encoder").named_parameters())
pipe_merge_params = dict(getattr(openai_clip, "text_model").named_parameters())
for key, param in merge_net.named_parameters():
x = pipe_source_params[key] * (1-ratio) + pipe_merge_params[key.replace("text_model.", "")] * ratio
param.data = x
return merge_net
def merge_network(pipe_source, pipe_merge, attr, ratio):
merge_net = copy.deepcopy(getattr(pipe_source, attr))
pipe_source_params = dict(getattr(pipe_source, attr).named_parameters())
pipe_merge_params = dict(getattr(pipe_merge, attr).named_parameters())
for key, param in merge_net.named_parameters():
x = pipe_source_params[key] * (1-ratio) + pipe_merge_params[key] * ratio
param.data = x
return merge_net
def merge_clip():
merge_pairs = {
"journey-journey": ["prompthero/openjourney-v4", "prompthero/openjourney-v4"],
"journey-counter": ["prompthero/openjourney-v4", "gsdf/Counterfeit-V2.0"],
"journey-sd": ["prompthero/openjourney-v4", "runwayml/stable-diffusion-v1-5"],
"counter-counter": ["gsdf/Counterfeit-V2.0", "gsdf/Counterfeit-V2.0"],
"counter-sd": ["gsdf/Counterfeit-V2.0", "runwayml/stable-diffusion-v1-5"],
"sd-sd": ["runwayml/stable-diffusion-v1-5", "runwayml/stable-diffusion-v1-5"],
}
device = "cuda:1"
sd_pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True)
openai_clip = CLIPModel.from_pretrained("openai/clip-vit-large-patch14", torch_dtype=torch.float16)
for i, (merge_key, merge_pair) in enumerate(merge_pairs.items()):
pipe1 = StableDiffusionPipeline.from_pretrained(merge_pair[0], torch_dtype=torch.float16, use_safetensors=True)
pipe1.scheduler = UniPCMultistepScheduler.from_config(pipe1.scheduler.config, use_safetensors=True)
pipe2 = StableDiffusionPipeline.from_pretrained(merge_pair[1], torch_dtype=torch.float16, use_safetensors=True)
pipe2.scheduler = UniPCMultistepScheduler.from_config(pipe2.scheduler.config, use_safetensors=True)
images = []
for clip_ratio in [0, 0.33, 0.66, 1]:
merge_clip = merge_clip_parameters(pipe1, openai_clip, clip_ratio)
merge_unet = merge_network(pipe1, pipe2, "unet", 0.5)
merge_pipe = StableDiffusionPipeline(
vae=sd_pipe.vae,
text_encoder=merge_clip,
tokenizer=pipe1.tokenizer,
unet=merge_unet,
scheduler=UniPCMultistepScheduler.from_config(pipe1.scheduler.config),
safety_checker=lambda images, **kwargs: (images, False),
feature_extractor=pipe1.feature_extractor
)
generator = torch.Generator(device).manual_seed(1234)
prompt = "1girl++++, solo, traveler, rule of thirds, teens, dress++, silver hair, side view, face in profile, praying, anime face, stand on a high hill, "\
"looking down into distance, pasture, flower garden, small town, sunshine, clear sky, flowing clouds, masterpiece, best quality, detailed face"
negative_prompt = "longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, multiple girls, multiple people"
merge_pipe.to(device)
compel_proc = Compel(tokenizer=merge_pipe.tokenizer, text_encoder=merge_pipe.text_encoder)
conditioning = compel_proc(prompt)
neg_conditioning = compel_proc(negative_prompt)
image = merge_pipe(prompt_embeds=conditioning, negative_prompt_embeds=neg_conditioning, generator=generator, output_type="numpy", num_images_per_prompt=1, width=512, height=768).images
images.append(image)
images = np.concatenate(images)
images = torch.from_numpy(images).permute(0, 3, 1, 2)
torchvision.utils.save_image(images, f"merge_{i+20}_{merge_key}.jpg", quality=92, nrow=4, normalize=False)
実験設定
ここで行う実験は以下のとおりです。
- Text Encoder:比率を変えながら、OpenAI CLIPとマージする
- マージ比率は0、0.33、0.66、1
- U-Net: 3個のモデルをそのまま使うケース、50%ずつマージするケースを比較
- VAE: SD1.5のを使う
横軸はCLIPのマージ比率で、6パターン実験します。各パターンはU-Netのマージ比率の違いです。
- OpenJourneyV4 100%
- OpenJourneyV4 50% + Counterfeit-V2.0 50%
- OpenJourneyV4 50% + StableDiffusionV1.5 50%
- Counterfeit-V2.0 100%
- Counterfeit-V2.0 50% + StableDiffusionV1.5 50%
- StableDiffusionV1.5 100%
結果
(1) OpenJourneyV4 100%

OpenJourney自体がText EncoderをFine-tuningしているとしか考えられません。ただ、CLIPが0か1にしてしまうと背景が似たような感じになるのはちょっと興味深いです。
(2) OpenJourneyV4 50% + Counterfeit-V2.0 50%

SD全く関係ないモデルでも、SDが使っているOpenAI CLIPをマージしてうまくいくのが面白いです
(3) OpenJourneyV4 50% + StableDiffusionV1.5 50%

これはCLIP関係なく、SD1.5とマージしたときと同じ結果になるはずです。CLIPのマージ比率を0.66まで上げてもアニメ調が維持されるの面白いですね。
(4) Counterfeit-V2.0 100%

Counterfeit単体だとそこまでCLIPの影響はないように見えます。
(5) Counterfeit-V2.0 50% + StableDiffusionV1.5 50%

しかし、U-Netにマージが入ると、異なる結果になりました。おそらくU-Netの係数がマージで曖昧になったので、Text Embeddingの影響が大きくなったのではないかと思います。CLIPをOpenAIのものに置き換えてもあまり悪影響はないので、置き換えてしまうのも一つの手かと思います。
(6) StableDiffusionV1.5 100%

SD1.5のCLIPとOpenAI CLIPは係数が同じなので、影響がないはずです。それが実証されました。
この実験からわかること
この実験からわかることは以下の通りです。
- Fine-tuningされたDiffusionモデルは、基本的にCLIPの空間が変わっていると考えるべき
- 見た目は影響が少ないが、U-Netのマージ等もしていると顕著に影響が出ることがある
- CLIPのText EncoderはOpenAI CLIP(SD1.5で使用)に差し替えても、今回のケース特に問題はなかった
ただあくまでこれはSD1.5までの話で、SD2系は使っているCLIPが変わるので、また別途検証する必要がありそうです。
また、スタイルを限定するために特定のワードを入れるモデルでは検証していないので、CLIPを入れ替えると大きく結果が異なる可能性があります。特定ワードの部分がCLIPで吸収しているのか、U-NetのAttentionで吸収しているのかよくわかりませんが、CLIPを入れ替えるとスタイルの限定がうまくいかなかくなるということも十分考えられます。
逆の見方をすれば、各Fine-tuningモデルのCLIPの部分だけとってきて、プロンプトなり単語なり入れて、どのように変わったのか定量化するというこもと可能なはずです。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー