
論文まとめ:Extreme Compression for Pre-trained Transformers Made Simple and Efficient
Posted On 2022-06-10


- タイトル:Extreme Compression for Pre-trained Transformers Made Simple and Efficient
- 著者:Xiaoxia Wu, Zhewei Yao, Minjia Zhang, Conglong Li, Yuxiong He
- 所属:Microsoft
- URL:https://arxiv.org/abs/2206.01859
- コード:https://github.com/microsoft/DeepSpeed
目次
ざっくりいうと
- 訓練済みTransformer(BERT)の軽量化、特に超低ビット精度(1ビット、2ビット)で量子化し、モデルサイズを極限まで削るための極限圧縮(Extreme Compression)の研究
- 先行研究では3段階に分かれていた複雑な蒸留のパイプラインを、1段階に簡素化し、Data Augmentationを使用し、長く訓練するXTCというフレームワークを提唱
- 極限量子化+層削減により、モデルサイズを50倍削減でき、GLUEタスクでSoTAを達成
要旨
- 極限圧縮のような積極的な圧縮方式で精度を維持するために、先行研究では、複雑な圧縮パイプライン(例えば、大規模なハイパーパラメータチューニングを伴う多段で高価な知識抽出)を導入している
- 蒸留によって圧縮された小規模モデルにはあまり焦点が当てられておらず、その手法の有効性を示す体系的な研究が不足していた。そこを包括的に研究したよ
- その結果、これまでの超低ビット量子化のベースラインは著しく訓練不足だったことがわかった
超低ビット精度量子化のためのシンプルかつ効果的な圧縮パイプライン(XTC)を提案。XTCは、
- 事前学習の知識蒸留をスキップして5層BERTを得ながら、これまでの最先端手法、例えば6層TinyBERTよりも優れた性能を達成できた
- 極限量子化+層削減により、モデルサイズを50倍削減でき、その結果GLUEタスクで新たな最先端結果を得られた

左が従来の方法。右が提案手法。従来の手法はパイプラインが複雑。
導入
モチベーション
- なぜ係数を3値化(2ビット)、2値化(1ビット)化けるしたいか?
- 理論的には重みの量子化の限界で16~32倍の圧縮率が得られるから
- 極限量子化には、「精度損失を回復するためのアドホックな最適化の必要性とは何か」という根本的な疑問が残されている
蒸留と量子化の関係性
- 先行する極端な量子化では、主にネットワークの精度を下げることに焦点が当てられていた。
- 一方、知識の蒸留という研究方向でもいくつかの進歩があり、大きな教師モデルが小さな生徒モデルの学習を導くために使用されている
- これらの重蒸留されたモデルとの極端な量子化の相互作用に関する研究はほとんどなかった
- 小さな蒸留モデルがどの程度、極端な量子化からのメリットを享受しているのか、問題を提起している
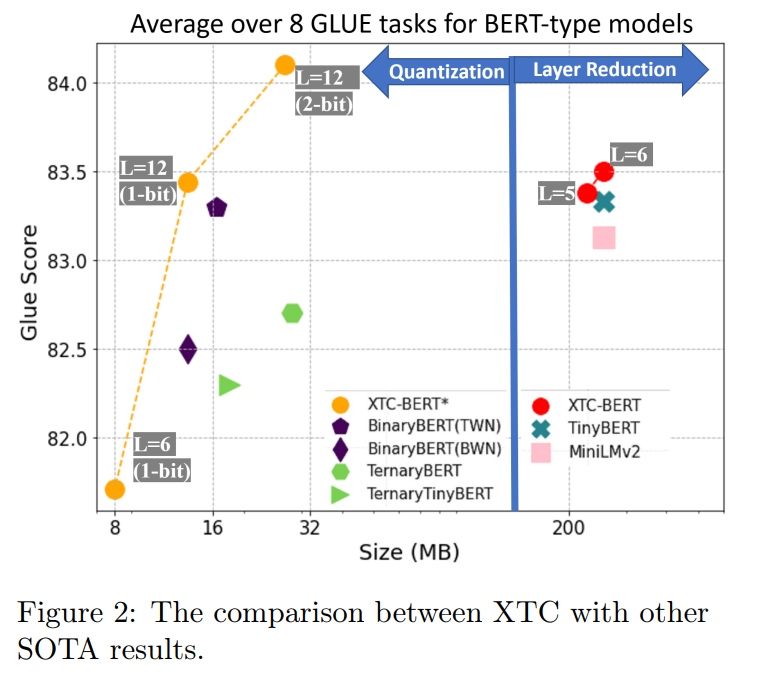
12層1ビットBERTbaseなどの先行する極限量子化法よりも高い精度を達成し、GLUEタスクの新しい先端的な結果になることがわかった。
極限圧縮手順の解析
性能の急激な低下を緩和するために、3段階の蒸留の段階的実施が必要なのか?
→長く学習すれば別に3段階にしなくてもいい
多段知識蒸留の役割
→ より多くの学習や学習率の探索を伴うシングルステージの知識蒸留をすれば、マルチステージのものから得られる精度と同等、むしろ上回った。
データ拡張の重要性
DAを使用しないトレーニングは、様々な圧縮タスクの下流タスク、特に小さいタスクのパフォーマンスを低下させる。
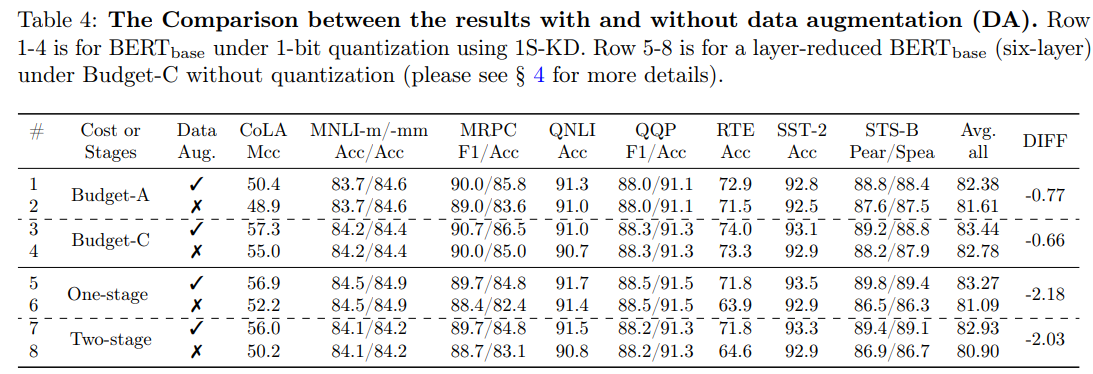
Budget-A, Cが3ステージ。1ステージでもDAをかければ3ステージと同様の精度が出る。
まとめと感想
- Transformerを1/50にしてもそれほど精度落ちないのすごい
- DeepSpeedの拡張なので、そのうちライブラリ側で対応すると思われる
- ViTの軽量化できたらかなり便利そう
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー