
論文まとめ:Genie: Generative Interactive Environments
Posted On 2024-03-07


- タイトル:Genie: Generative Interactive Environments
- 論文URL:https://arxiv.org/abs/2402.15391
- 著者:DeepMindの方々
- プロジェクトURL:https://sites.google.com/view/genie-2024/
目次
ざっくりいうと
- DeepMindが開発した、ゲームのように入力を受け付ける動画生成モデル(対話的生成環境)
- 2Dゲーム大規模動画データから訓練、時空間Transformerを使用し、潜在的行動をモデリング
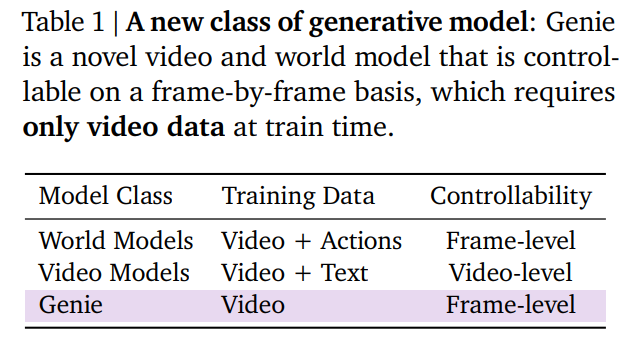
- 先行研究と異なり、ドメイン固有の訓練が不要な基盤的世界モデル。ロボットのエージェントの基盤モデルとして期待
概略
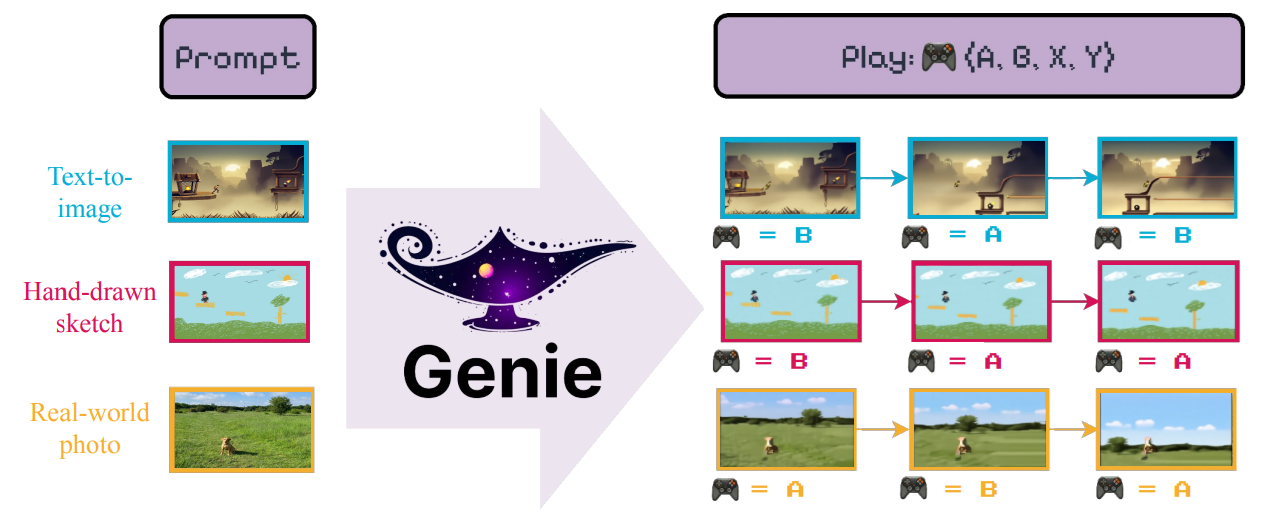
- ラベル付けされていないインターネット動画から教師無しで学習させた最初の生成的対話環境であるGenie
- テキスト、合成画像、写真、さらにはスケッチを通して記述される、限りなく多様なアクションコントロール可能な仮想世界を生成
- Genieは11Bパラメータの基盤的な世界モデル
- 既存の研究は、ドメイン固有の訓練が必要だった。Genieはこれが不要で基盤モデルとして扱えるにもかかわらず。フレーム単位で環境を生成可能
- 学習された潜在的行動空間は、未知のビデオから行動を模倣するようにエージェントを訓練することを容易にし、未来のジェネラリストエージェントを訓練するための道を開く
はじめに
- 動画生成や画像生成は進化しているが、動画生成モデルとChatGPTのような言語ツールとのインタラクションやエンゲージメントでは、没入感のある体験とまではいっていない。溝が残っている
- Genieは、インターネット上のパブリックな20万時間以上(最終的には3万時間)のインターネットゲームビデオの大規模データセットから学習。アクションやテキストのラベルなしの訓練で、潜在的アクション空間介してフレーム単位で制御可能
- 設計の核
- Xu et al., (2020)で提唱された時空間Transformer(Spatiotemporal (ST) Transformers)。これを全てのモデルコンポーネントで使用
- ビデオトークナイザーを利用し、因果関係行動モデルによって潜在的な行動を抽出
- ビデオトークン+潜在的なアクション→ダイナミクスモデル
- 先行研究のMaskGITを用いて次のフレームを自己回帰的に予測
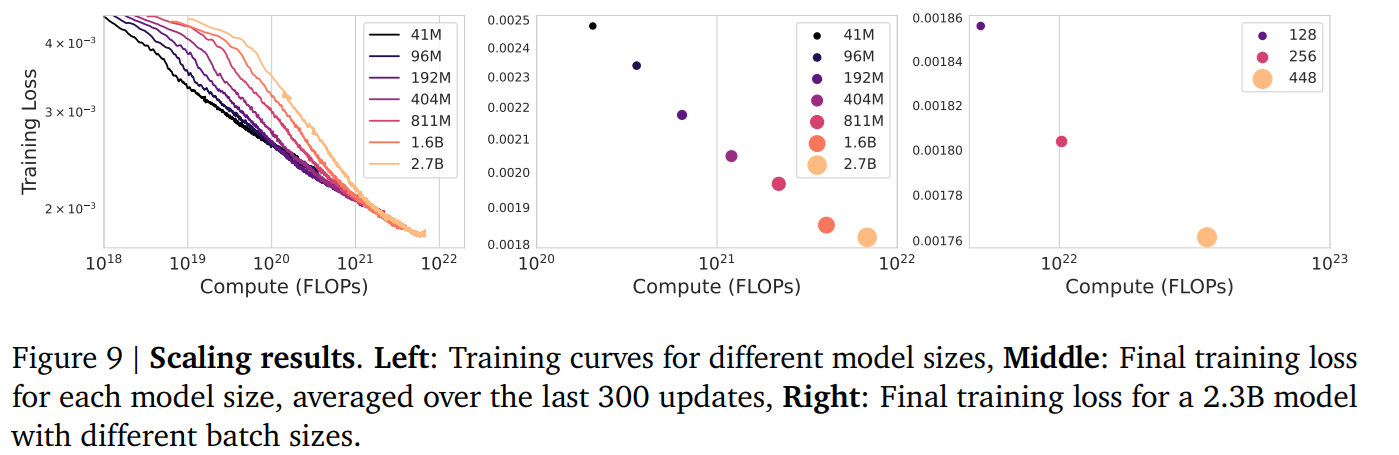
- 40Mから2.7Bのパラメーターと変化し、最終的に11Bのモデルまでのスケーリング則を確認
- 強化学習(RL)における、ゼロショットエージェントとしての活用可能性を持っている
パラダイム:世界モデル、動画生成モデル、Genie
手法
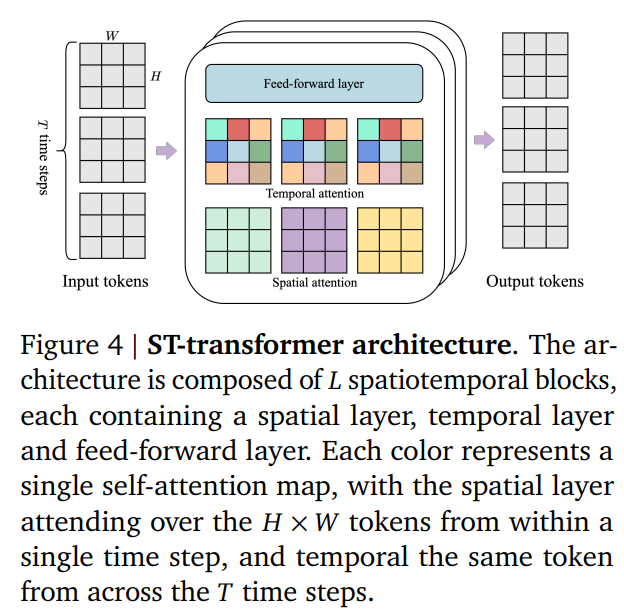
- 基本はViT(Vision Transformer)。Transformersの指数関数的のメモリコストが動画の場合特に課題になる。O(10^4)トークン最大含む
- メモリの効率化のために、時空間Transformerを利用
- 時空間Transformer:空間方向と時間方向に独立したAttention Mapをとる
- 各色が1個のAttention
- タイムステップ内で1×H×Wのトークン(空間方向)
- タイムステップ間ではT×1×1のトークン(時間方向)
- 私の注釈:昔の動画認識モデルであった2D+1Dのアプローチの延長線上に似ている
- 各色が1個のAttention
- Genieの主要コンポーネント
- Latent Action Model
- Video Tokenizer
- Dynamics Model
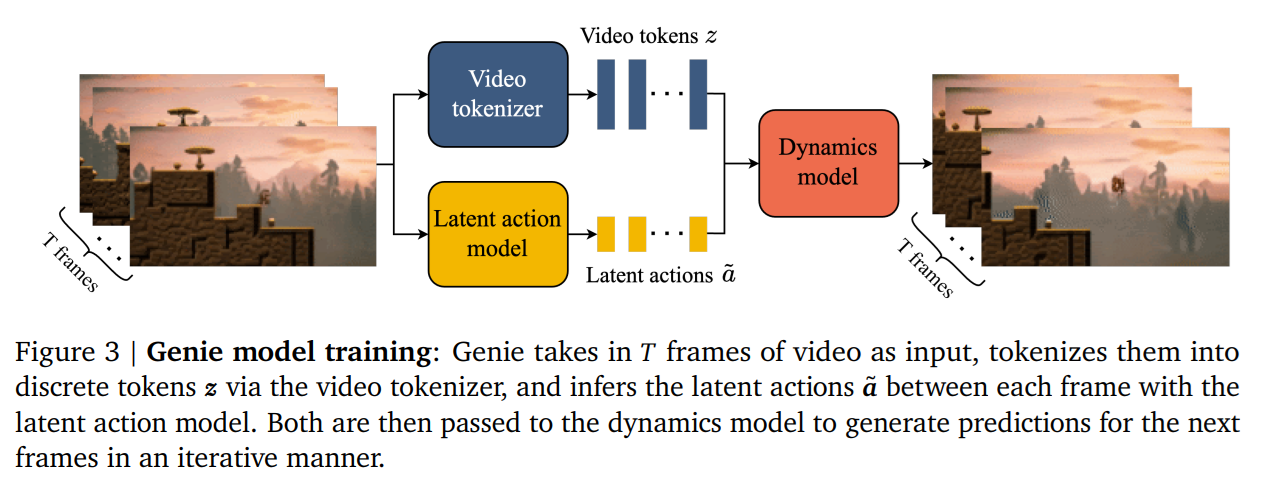
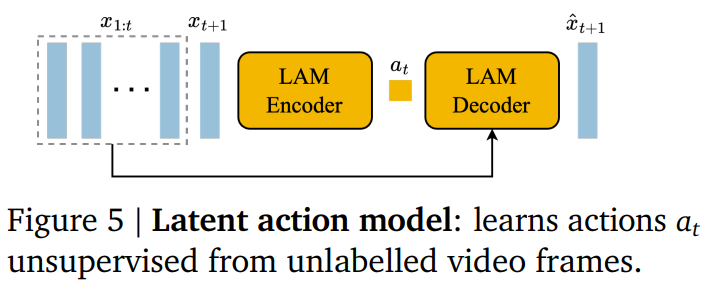
Latent Action Model
- 制御可能な動画生成のために条件付する行動ラベルがほしいが、アノテーションコストが高価。教師なしで潜在的な行動を学習
- VQVAEベース
- LAMDecoderは学習時のみ使い、推論時は捨てる。ユーザー入力の行動に置き換える。これにより、制御可能性を実現
- 時空間Transformerを使用
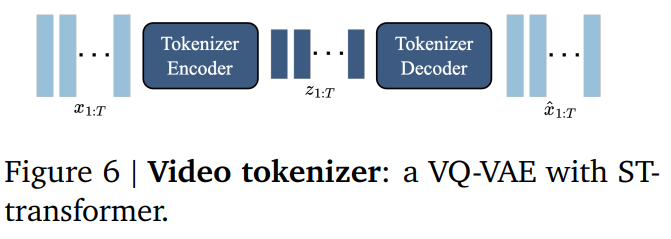
Video Tokenizer
- 入力「T×H×W×C」→出力「T×D」となるような符号化を行うTokenizer
- このTokenizerはVQ-VAEのEncoder-Decoderモデルで学習
- 先行研究との違いは、時空間Transformerの使用。先行研究のC-ViViTだとフレーム数に対して二次関数で、計算量が多い
Dynamics Model
- デコーダーのみのMaskGIT Transformer
- 入力z:ビデオ+a:潜在的な行動→出力z:出力フレーム
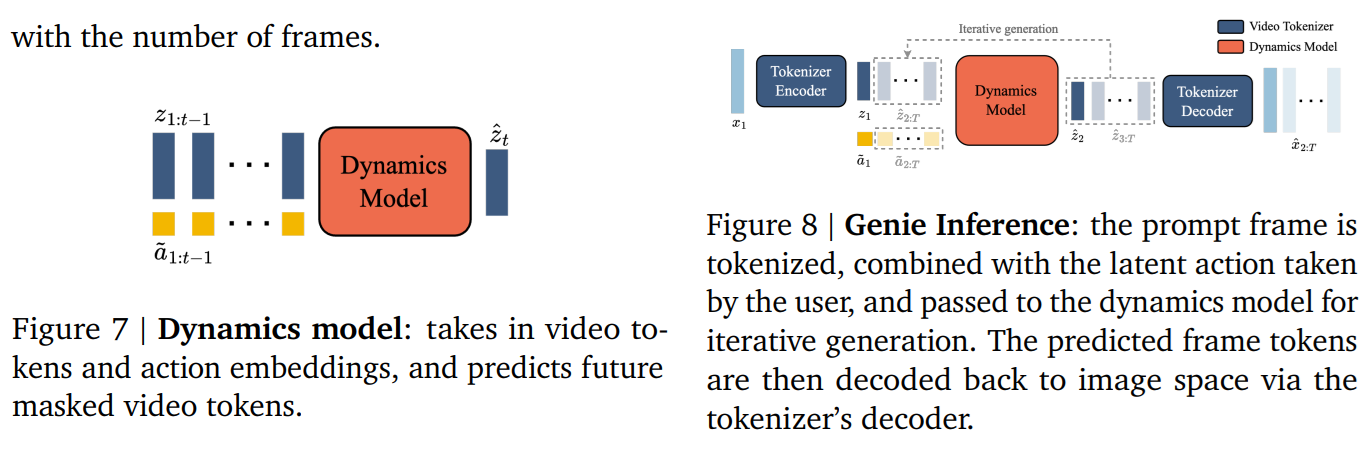
推論時
- ユーザーはベースの画像を指定
- 潜在的な離散的アクションはユーザーから入力させる
- 自己回帰的にフレームを生成し、動画を生成
実験結果
- データセット。ネット上に公開されている2D Platformerのインターネット上動画の大規模データセット
- 元データは10FPS、55M個、16秒の動画クリップを160×90の解像度のものをフィルタリング
- 最終的には6.8M個、16秒のビデオクリップ30k時間
- 評価指標
- フレーム間のPSNRで比較。GTと生成結果で、フレーム間のPSNRが小さいほどよい
モデルの性能についてスケーリング則が観測できた
興味深いのは、ゲームを見せているだけで、視差(前景は多く動き、背景は少なく動く)をエミュレートできたこと

この世界モデルは、ロボットのエージェントにおける基盤モデルとしての活用方法が期待できる。
アブレーション
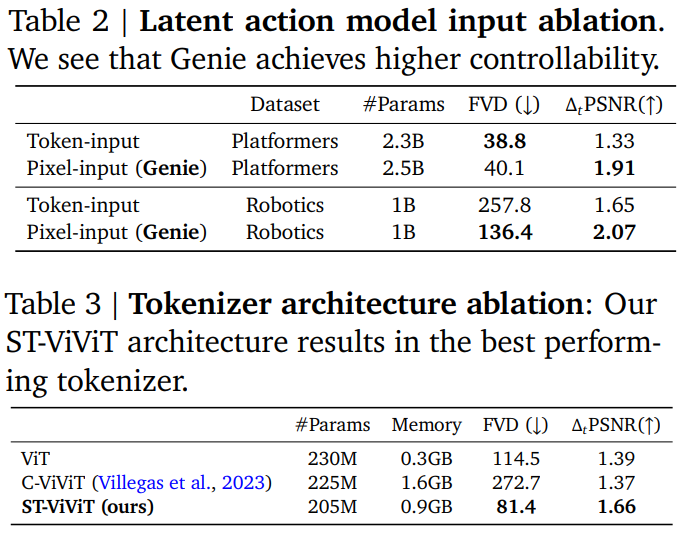
- 評価指標のFVD=FIDの動画版(だと思う)。FIDはInception Scoreのワッサースタイン距離で、画像生成のメトリック
- 潜在的行動モデルは、実はあとから調べたらトークン化より生のピクセルのほうが性能が良かった。トークン化すると動きが滑らかではなくなる。最終的にはピクセルを使うことにした
- (私の注釈)本文中の言っていることと違うが、ここはまだ調整の余地があるということだと思う
- 時空間Transformerめっちゃ効いてる
議論
- 限界
- 自己回帰モデルの弱点を継承しており、非現実的な未来のハルシネーションがおこる
- 16フレームの生成しかできない
- 学習データや学習済みモデルやチェックポイントは、ビデオゲームコミュニティと関わり、研究を安全で責任あるものにしたいので公開じません←(^^^^^^^)
所感
- Gから始まるGoogle系の生成モデル多すぎない?
- 読みやすい構成で書かれた論文
- ロボットのPretrainに使える基盤モデルってありそうでまだなかったんだ
- 自然言語をいっぱい読ませたら人間の思考を模倣できるLLMができたように、動画をいっぱい読ませたら世界の動きを模倣できる大規模動画生成モデルというのは今後起こりえそう
- 動画生成と世界モデルの組み合わせが今後多く出てきそう
- 最初見たとき、潜在的行動モデルは拡散モデルかと思ったが、単なるEncoder-Decoderだった
- 潜在的行動モデルが状態空間モデルに近いので、LLMのMambaみたいなアプローチと相性良さそう。こういう方向に進んでいくのかな…?
- 時空間Transformerだったり、世界モデルだったりひたすら用語がかっこいい
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー