
論文まとめ:GLIPv2: Unifying Localization and Vision-Language Understanding


- タイトル:GLIPv2: Unifying Localization and Vision-Language Understanding
- 著者:Haotian Zhang, Pengchuan Zhang, Xiaowei Hu, Yen-Chun Chen, Liunian Harold Li, Xiyang Dai, Lijuan Wang, Lu Yuan, Jenq-Neng Hwang, Jianfeng Gao
- 所属:University of Washington、Microsoft、UCLA
- 論文URL:https://arxiv.org/abs/2206.05836
- コード:https://github.com/microsoft/GLIP
目次
ざっくりいうと
- ローカライゼーションタスク(物体検出、インスタンス領域分割)と視覚言語理解(VQA、キャプション生成)を共通でこなすFoundationモデル
- 言語特徴量と画像特徴量をネットワーク内で融合させ、その前後で画像-単語の類似度を取り、サンプル内/外で学習。GLIPv1であった「Grounding」の概念を引き継ぐ
- Zero-shot推論もできるほか、「Prompt Tuning」と言われるプロンプト部分の少量のパラメーターを訓練することで、モデル全体を訓練するFine-tuningに匹敵する精度を達成
- 物体検出タスクにおいて、DyHeadを上回る高いFew-shot性能があるほか、数々のタスクでSoTAに近い性能を達成
以前のGLIPについて
Grounded Language-Image Pre-training
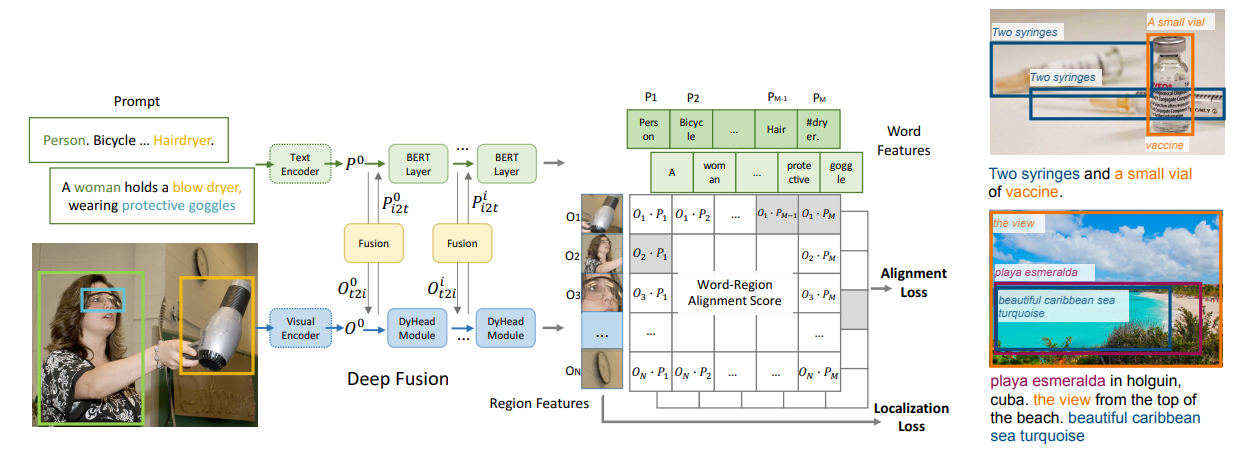
GLIPの特徴「Grounding」
- プロンプトの1つ目に、COCOの全体のクラス「Person. Bicycle … Hairdryer.」を入れている
- データセット内で共通のプロンプトと、画像ごとに異なるプロンプトを入れ、単語単位のペア類似度を計算
いきなり「Grounding」という単語が出てきて混乱するが、共通のプロンプトと、固有のプロンプトの2つを使うというのを認識しておけばOKそう。Grounding/Groundedをどう訳すか困るが、「統合」としておくのが無難か?
導入
視覚言語理解のモデルでは、ローカライゼーション(例:物体検出)での事前学習で有効であることが知られている。二段階の学習を統一し、学習コストを下げるのが長年の課題だが、双方は全く性質の異なるタスク。
- ローカライゼーション
- Visionのみ
- Boudning Boxやピクセルマスクといった細かい出力を必要とする
- 視覚言語認識(VL Recognition)
- モダリティの融合を重視
- 高度な意味出力(回答やキャプション)を必要とする
本論文では、「VL Grounding」を、ローカライゼーションと理解能力のための「メタ能力」として特定したい。
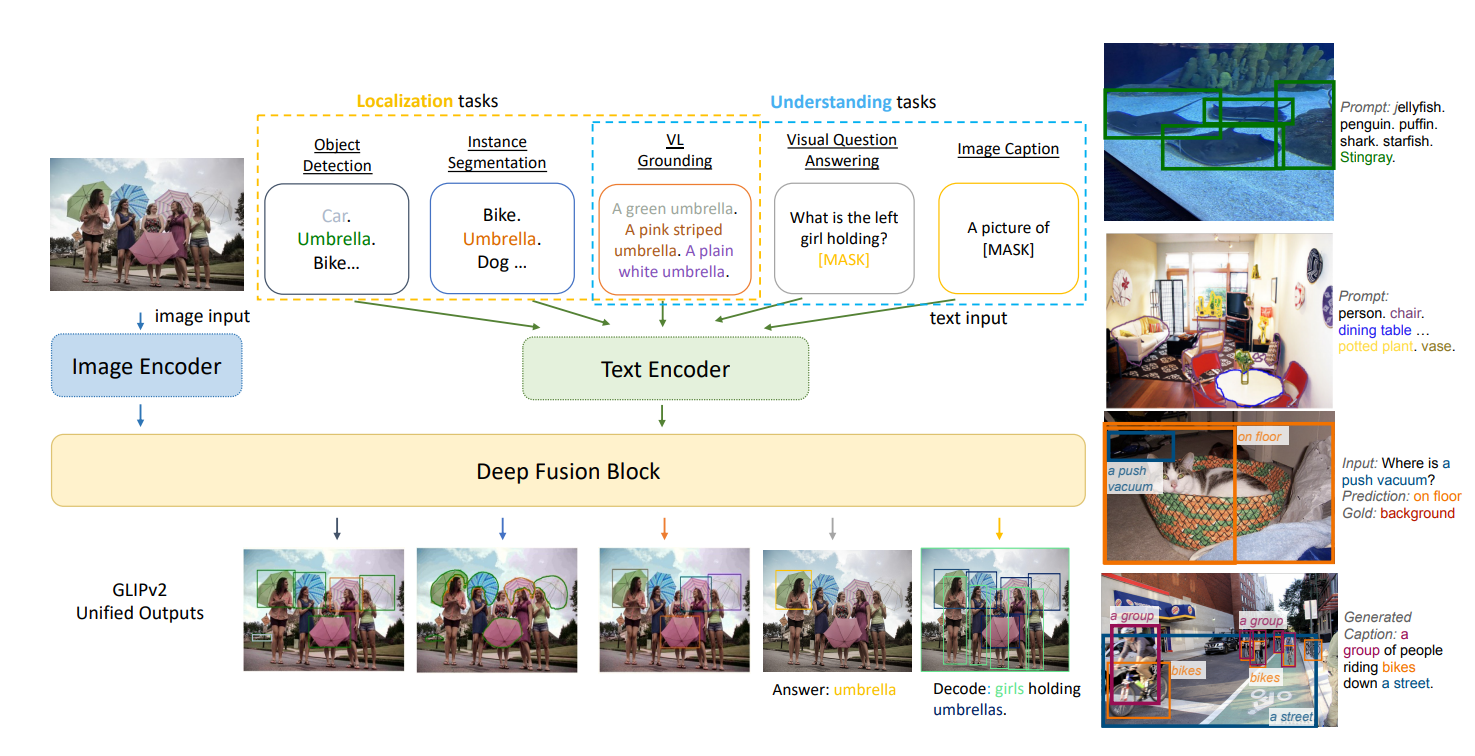
より強力な視覚言語統合タスク
- GLIPは、その事前学習タスクとして、フレーズ統合(Phrase Grounding)タスクを提案しているが、データ情報を十分に活用できていない
- フレーズ統合タスクは、「green, pink striped or plain white umbrella?」に一致させることをモデルに要求するだけ
- この選択は非常に簡単で、色を認識するだけで良く、この統合データは多くの情報が失われている
- 傘は黒や黄色などの「色」ではなく、「傘であり、車やバイク」ではないということも理解させたい
- GLIPv2では、同じバッチ内の他の文のフレーズをNegativeとして利用するモデルを導入した
- 具体的には画像間領域-単語の対照学習タスク(損失関数:Intra-image region-word alignment loss)
ローカライゼーションと視覚言語理解の統合
統合された視覚言語の定式化とアーキテクチャ
- GLIPv2の統一的な定式化の中心は、分類からマッチングへのトリック
- タスク固有の固定語彙分類問題を、タスクにとらわれないオープン語彙の視覚言語マッチング問題として再定式化
- CLIPにおける画像分類を画像-テキストマッチングとして再定式化したもの
- これによりモデルは生の画像-テキストデータから直接学習することができ、オープン語彙のタスクにおいて強いゼロショット結果を達成できた
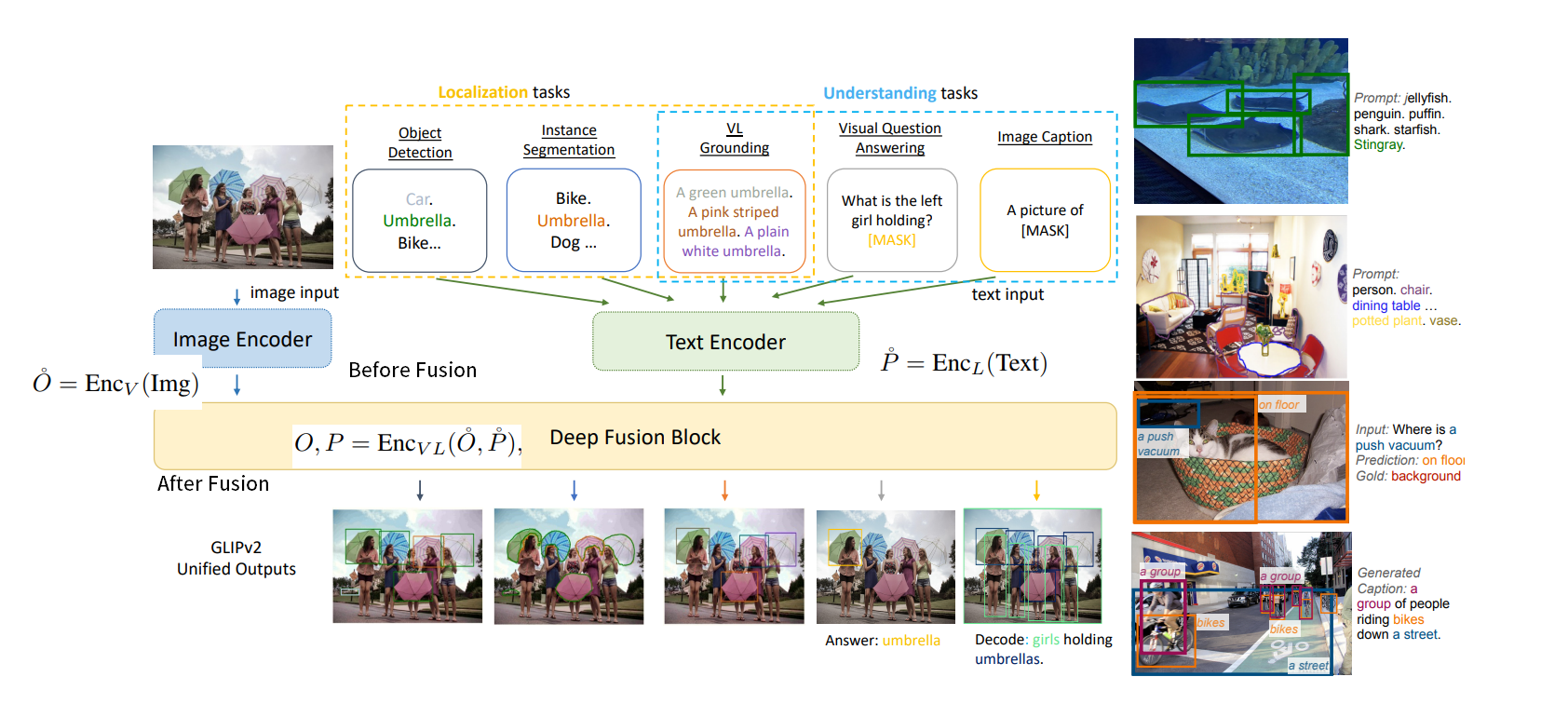
- このモデルは「Deep Fusion Block」があるのが特徴
- モダリティの融合前の特徴量$\mathring{O}, \mathring{P}$と、融合後の特徴量$O, P$をそれぞれ使う
- クロスモダリティ融合表現$O, P$があれば、タスクに特化した軽量のHeadを追加すれば、タスクを拡張できる
(言語ガイド付き)物体検出とフレーズ統合
GLIPに従い、GLIPv2は分類からマッチングへのトリックを用いて、検出と統合を統一的に行う。検出では
- クラスのロジットを、$S_{cls}=OW^T$($W$はボックスの分類器の重み行列)を(GLIPv1)
- タスクにとらわれない領域-単語の類似のロジット$S_{ground}=OP^T$に($P$はタスクにとらわれない言語エンコーダのラベルの埋め込み表現)に置き換える(GLIPv2)
入力テキストについて
- 物体検出では、物体候補ラベルを連結した文字列
- フレーズ統合では、自然言語の文
物体候補ラベルを連結した文字列とは?

「各Boudning Boxは単語に対応しているでしょ?」ということ(この画像はGLIPv1の論文より)
(言語ガイド付き)インスタンス領域分割と参照画像領域分割
- インスタンス領域分割は、物体検出の結果を利用している
- 最初に物体検出で訓練し、その後にインスタンス領域分割タスクと、参照画像領域分割タスクのどちらにも使える共通のヘッドを追加して訓練
- GLIPv2における、分類からマッチングへのトリックは、意味的領域分割など、単一モダリティのCVモデル他の多くの分類ヘッドにも適用できる
- セグメンテーション(領域分割)ならなんでも使えるヘッドを追加したよ、という解釈
GLIPv2の損失関数

Intra-image region-word alignment loss
$$\mathcal{L}_{intra}=loss(OP^T;T)$$
- $O, P$:言語特徴量と画像特徴量が「Deep Fusion Block」で融合された後の特徴量
- $OP^T$:領域の画像と単語間の類似度(CLIPと同じ考え方)
- $T$:アノテーションによって決定されるターゲットのアフィン行列
- $loss$:CrossEntropyロスやFocalロス
Inter-image region-word contrastive loss
バッチサイズ$B$の、$i$番目のサンプルについて、特徴量$(O, P)$を$(O^i, P^i)^B_{i=1}$表記する。バッチ内とバッチ間でそれぞれで類似度をとる。
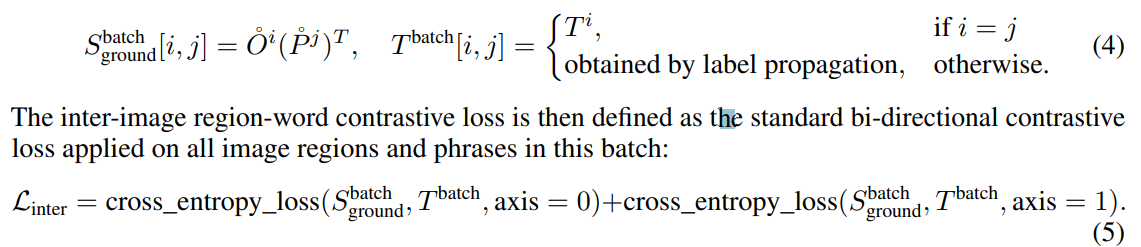
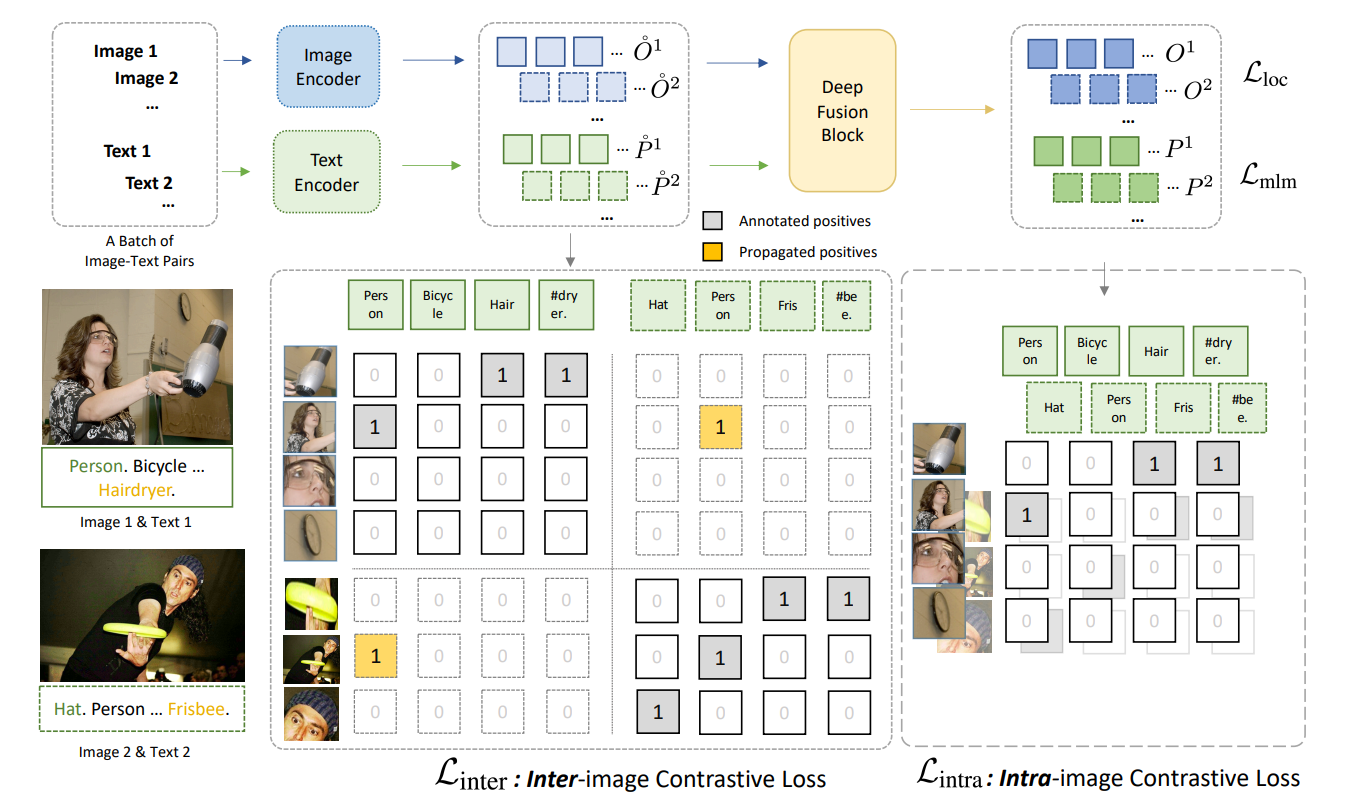
- 「Inter-image」:画像間、「Intra」:画像内
-
ポイントは、$\mathcal{L_{intra}}$がFusion後の$O,P$を使っていたのに対し、$\mathcal{L_{inter}}$がFusion前の$\mathring{O}, \mathring{P}$を使っている点
- Fusion後の画像・テキスト特徴量がペア情報を見てほしくないから
- $\mathcal{L_{intra}}$は各画像のアノテーションから、画像を飛び越えて(例:右上の2行目2列目のPerson、左下の2行目1列目のPerson)ラベルを伝播できる
CLIPと異なる点
- プロンプトを単語で分割して見ることで、物体検出や様々な下流タスクに対応
- 画像間の類似度も見ている。1枚の単語と画像パッチの類似度行列を、複数の画像にわたり総当たりで計算し、ラベルの伝播をさせている($\mathcal{L_{intra}}$)
- 画像とテキストを融合させるブロック(Deep Fusion Block)があり、融合前と融合後の特徴量の両方を見ている
事前学習の訓練方法
- GLIP(v1)事前学習モデルでテキスト中のフレーズに対するGrounding Box$\hat{T}$を生成し、GLIPv2の事前学習を行う。
- Grounding Boxとはなにか?:上の図の「Image 1」ではBicycleは登場しないが、プロンプトに入れられている。
- データセット内で登場するラベルをある程度まとめたもの(GLIPv1と同じ)
下流タスクへの転用
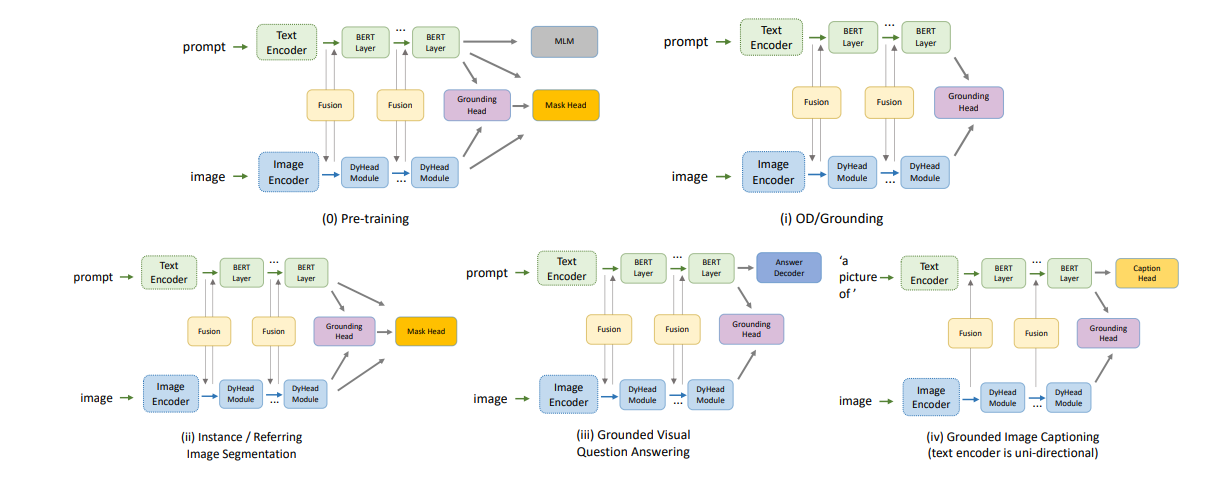
1つのモデル・アーキテクチャで全てに対応
- 検出とセグメンテーション
- 事前学習アーキテクチャが検出とセグメンテーションを本質的に実行可能
- タスク固有のヘッドは不要
- Vision & Languageの場合
- VQAの場合は、系列開始トークンの隠れ表現の上に分類ヘッドを追加
- キャプション生成の場合は、文脈を与えられた次の単語の尤度を最大化する、一方向性の言語モデリングロスを用いて学習
プロンプトチューニング
この論文では説明が省かれているので別の論文(The Power of Scale for Parameter-Efficient Prompt Tuning)で確認。プロンプトチューニングとは、プロンプトエンジニアリング(精度を上げるために入力テキストを変更する)とは別物で、タスク固有のプロンプトの部分の小さなネットワークだけ訓練する手法。
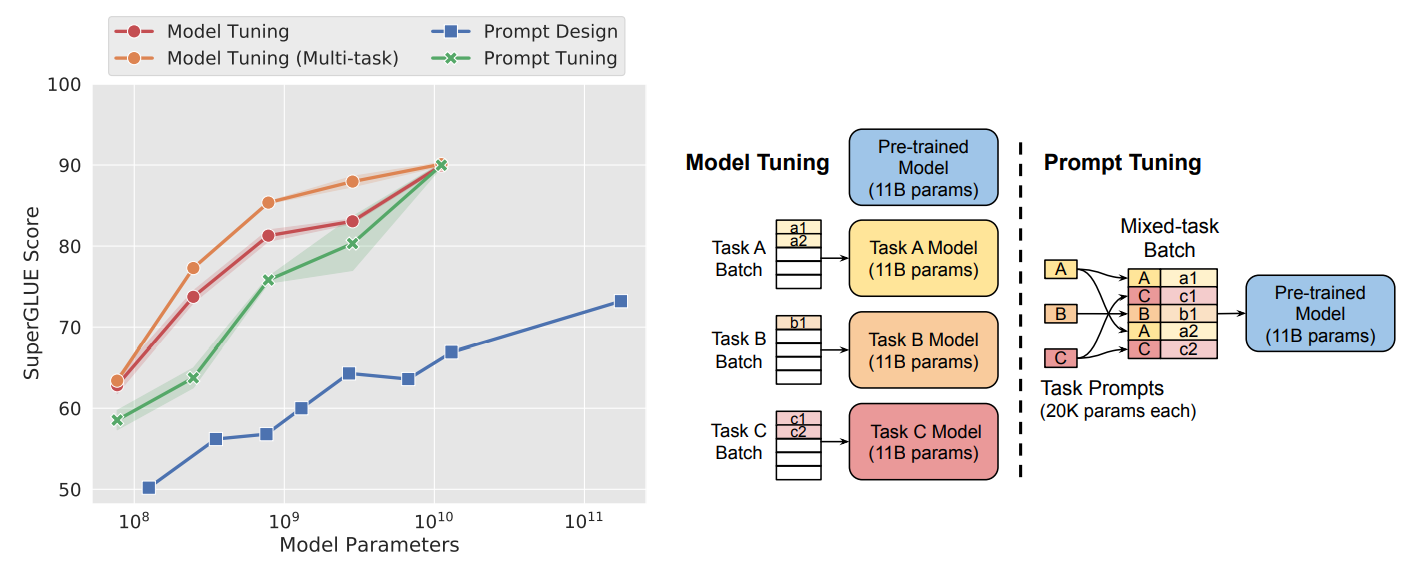
「11Bのネットワークを訓練するのはしんどいけど、20Kのネットワークなら訓練できるよね」「それでもModel Tuning(従来のFine-tuning)に匹敵する精度は出せるよ」という主張。
すべてに共通した係数
- 最小限のパラメータを変更するだけで、様々なタスクに移行できるモデルの開発に関心が高い(Not fine-tuning)
- Fine-tuningとは異なる
- Fine-tuningはモデルの全部の係数を変更する
- GLIPv2はZero-shotもできるが、プロンプトチューニングで新しいタスクに適応できる
- プロンプトチューニングとは、小さなプロンプト埋め込み行列である$\mathring{P}$を直接調整すること
- CLIPのような浅い相互作用のLinear-Probing/プロンプトエンジニアリングとは異なるもの
- GLIPv2のプロンプトチューニングは非常に効果的で、Fine-tuningの性能に匹敵する
- 局所的なモデルのチューニングが、Fine-tuningに大きく遅れをとるという従来の一般的な観測とは対照的
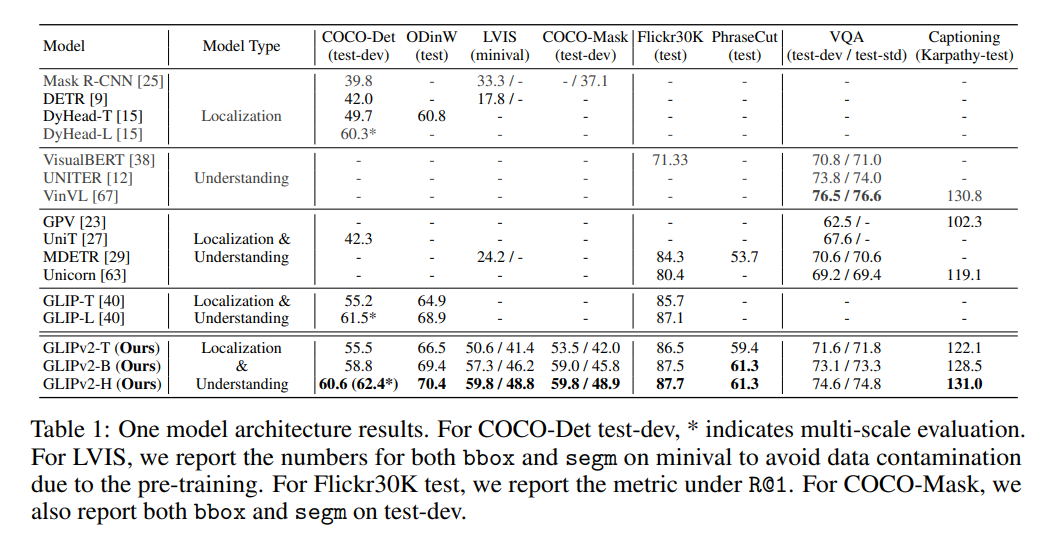
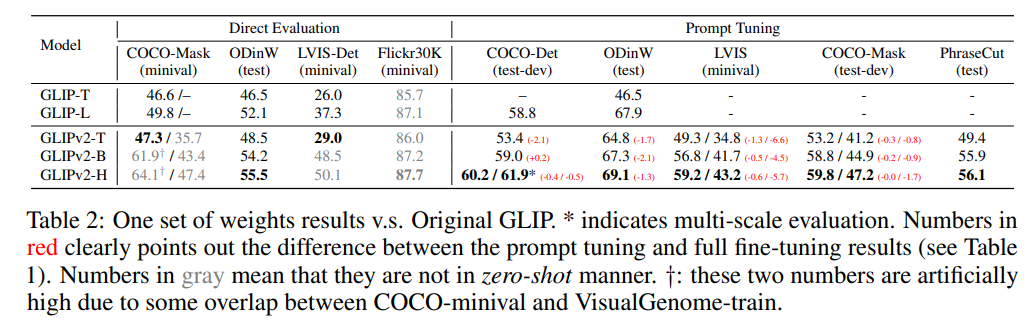
DyHead-LはFine-tuningしてCOCO-Det(物体検出)60.3%」。「Prompt tuning」の列のカッコ内の赤字が、Fine-tuningとの比較。GLIPv2ではプロンプトチューニングだけでこの精度が出る。
※グレーの部分はZeroshotのように見えるが、当該のデータセットを訓練に含んでいるため、Zeroshotとは意味が異なる
実験
アーキテクチャ
- 画像ネットワーク:Swin Transformer-Tny, Base, Huge
- テキストネットワーク:Transformer(BERT-Base)
- Fusionネットワーク:Deep Fusion
- インスタンス領域分割ネットワーク:Hourglass Network
精度
- 全部1個のモデルにやっているにも関わらず、ローカライゼーションと視覚言語理解のタスクでSoTAに近かった
- Few-shotの物体検出において、DyHeadを大幅に上回る性能があった
- Inter/Intraのロス+BERTの損失関数を加えることで、Prompt TuningでもFine-tuningと同等の精度があった
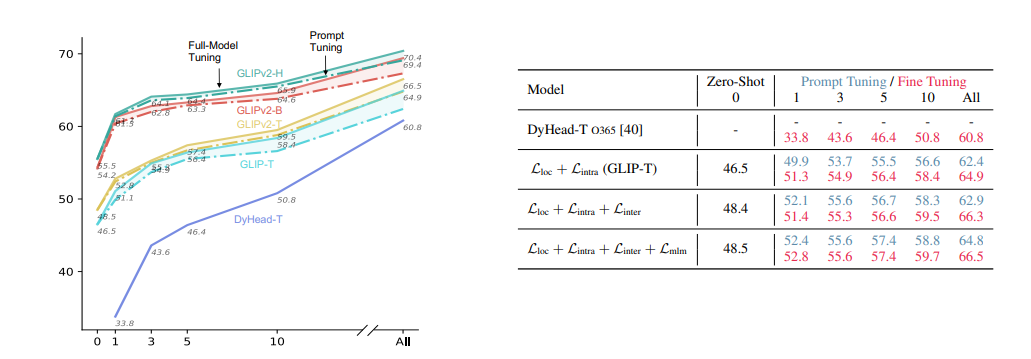
Instance Segmentationの結果。なにげに精度良さそう

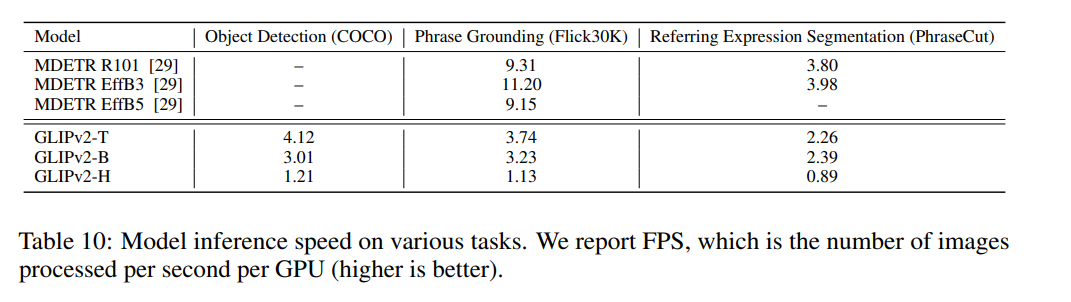
推論速度
V100バッチサイズ1での速度。さすがにFoundationモデルなので大きいが、非現実的なサイズではない。
まとめと感想
- いろんなタスクが統合されたやばやばなモデル。様々なダウンストリームタスクに対して、メリットを享受しあっているのがすごい
- 素直にやばい。ディープラーニングに対する価値観変わる。現在公開されているのがGLIPv1だが、そのうち公開されそうなので楽しみ
- 巨大なモデルに対して、Prompt Tuningがどの程度の速さで動くのか気になる
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー