
ごちうさで始める線画の自動着色(2)~TFRecordの作成~

KaggleにあったGochiUsa_Facesデータセットを使って、ごちうさキャラの線画の自動着色で遊んでみました。この投稿では訓練の前段階としてTFRecordを作成していきます。
目次
はじめに
前回のポストで、GochiUsa_FacesデータセットのEDAをしましたが、今回はモデル訓練のためのTFRecord作成をやっていきます。
ごちうさで始める線画の自動着色(1)~データセットのEDA~
https://blog.shikoan.com/gochiusa-01/
- 今回のやること:TFRecordの作成
- 次回以降やること:モデルの作成、訓練
なぜTFRecordなのか
今回の目的がTFRecordを使って実践的な訓練をしてみたかったという点があります(これが大きいです)。TensorFlowの推奨データ形式がTFRecordという点もあります。諸事情により、TFRecordを使わないで訓練するという選択肢もありですが、何かと避けがちなTFRecordに一度しっかり向き合ってみたかったのです。
作りたいモデル
線画を入力データとし、着色した画像を出力とするようなモデルを作ります。線画はデータセットに付属していませんが、カラー画像から人工的に作ります。「画像がどのキャラか」というラベル情報も使います。
今回TFRecordに記録する情報は次の3つです。
- もとのカラー画像
- 線画(1から人工的に作る)
- ラベル
Canny法によるエッジ検出
問題となるのは「どのようにカラー画像から線画を作るか」です。線画を作るとはエッジ検出の問題と捉えられるので、Canny法によるエッジ検出を使います。これはOpenCVに関数があります。
Canny法によるエッジ検出は次のようにします。Canny法には2つのスレッショルドがあり、ヒステリシスが存在する処理の最小値、最大値を示します(直感的な理解は後述)。
edge = cv2.Canny(img, 50, 200) # スレッショルドが2つある
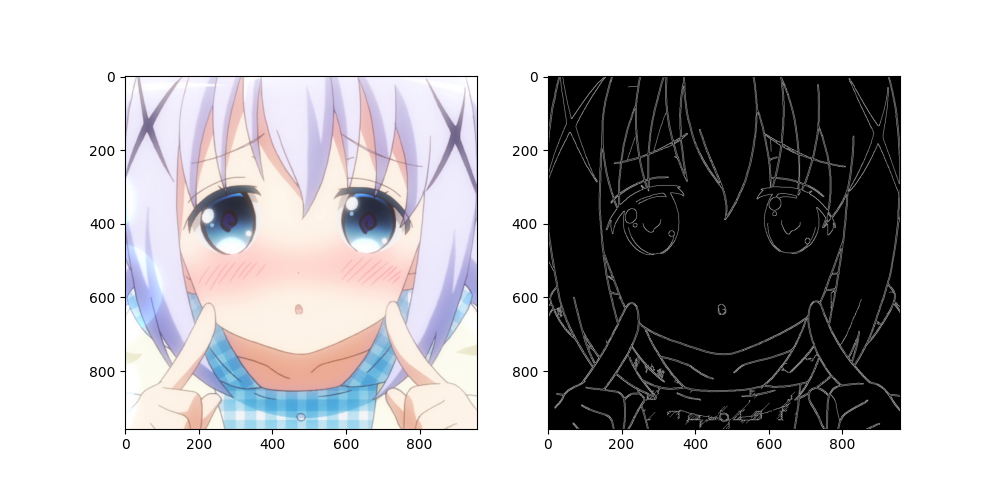
GochiUsa_Facesデータセット内の適当な画像をCanny法でエッジ検出し、元画像と並べて表示するコードは次の通りです。
def canny_simple():
# ランダムに画像を1個選ぶ
np.random.seed(21)
files = sorted(glob.glob("archive/main_dataset/main_dataset/Chino/*"))
np.random.shuffle(files)
# オリジナル画像
img = cv2.imread(files[0])
# エッジ画像
edge = cv2.Canny(img, 50, 200) # スレッショルドが2つある
# 表示
fig = plt.figure(figsize=(10, 5))
ax = fig.add_subplot(1, 2, 1)
ax.imshow(img[...,::-1]) # BGR->RGB
ax = fig.add_subplot(1, 2, 2)
ax.imshow(edge, cmap="gray", vmin=0, vmax=255)
plt.show()
結果は次の通り。このようにエッジ検出できています。
スレッショルドの直感的な理解
Canny法の2つのスレッショルドを変更したらどうなるでしょうか。
def canny_threshold():
# ランダムに画像を1個選ぶ
np.random.seed(100)
files = sorted(glob.glob("archive/main_dataset/main_dataset/Chino/*"))
np.random.shuffle(files)
# オリジナル画像
img = cv2.imread(files[0])
# エッジ画像
thresholds = [50, 100, 150, 200, 400]
fig = plt.figure(figsize=(12, 12))
for i in range(5):
for j in range(5):
x = None
if j > i:
x = cv2.Canny(img, thresholds[i], thresholds[j]) # スレッショルドが2つある
elif i == 3 and j == 1:
x = img[...,::-1] # 元画像
if x is not None:
ax = fig.add_subplot(4, 4, 4 * i + j)
if x.ndim == 2:
ax.imshow(x, cmap="gray", vmin=0, vmax=255)
ax.set_title(f"{thresholds[i], thresholds[j]}")
elif x.ndim == 3:
ax.imshow(x)
ax.axis("off")
plt.show()
スレッショルドを「50、100、150、200、400」と変更してみました。これは実質的にハイパーパラメータとなるので、頑張るのだったらチューニングしてもいいと思います。
直感的な理解としては、第1と第2の値差が小さいほど細かい線を拾う傾向があります。ただ(50, 100)のケースだと背景の線まで拾うので、どこまで拾うのがよいのかは難しいところです。突っ込んでやるんだったら線画の抽出もNNベースになるのでしょうね。

この値が正しいかどうかはわかりませんが、今回は(50, 400)で固定してみました。
TFRecordを記録する
GochiUsa_Facesは画像解像度が無数にありますが、ほとんど正方形画像なので、固定サイズにリサイズしてから記録します。320×320にリサイズして、Data Augmentationをはさみながら256×256でNNに食わせます。短辺の解像度が320未満のサンプルは捨てます。
解像度さえ決まれば簡単ですね。サンプル単位で次のようなスキームにします。
- カラー画像:uint8型 (320, 320, 3)
- エッジ画像:uint8型 (320, 320, 1)
- ラベル:float32型 (9, ) ←クラス数が9だから
ラベルは後々楽したいので、One-hotエンコーディングして記録します。TFRecordの作成コードは次の通り。
import tensorflow as tf
import numpy as np
import cv2
import glob
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
CHARACTERS = ["Blue Mountain", "Chino", "Chiya", "Cocoa", "Maya", "Megumi", "Mocha", "Rize", "Sharo"]
def serialize_sample(image, edge, class_idx):
label_binary = np.eye(len(CHARACTERS)).astype(np.float32)[class_idx].tobytes()
image_list = _bytes_feature(image.tobytes())
edge_list = _bytes_feature(edge.tobytes())
label_list = _bytes_feature(label_binary)
proto = tf.train.Example(features=tf.train.Features(feature={
"image": image_list, # uint8, (320, 320, 3)
"edge": edge_list, # uint8, (320, 320, 1)
"label": label_list # float32, (9, )
}))
return proto.SerializeToString()
def write_record(root_dir, min_image_size):
dirs = sorted(glob.glob(root_dir + "/*"))
record_name = root_dir.replace("\\", "/").split("/")[-1]
paths, classes = [], []
for d in dirs:
files = sorted(glob.glob(d + "/*"))
base_dir = d.replace("\\", "/").split("/")[-1]
class_idx = CHARACTERS.index(base_dir)
if class_idx < 0:
raise IndexError(f"class_idx < 0. class name = {base_dir}")
for f in files:
img = cv2.imread(f)
if min(img.shape[:2]) < min_image_size:
continue
paths.append(f)
classes.append(class_idx)
np.random.seed(123)
indices = np.random.permutation(len(paths))
with tf.io.TFRecordWriter(record_name + ".tfrecord") as writer:
for i in indices:
img = cv2.imread(paths[i])
img = cv2.resize(img, (min_image_size, min_image_size), interpolation=cv2.INTER_LANCZOS4)
edge = cv2.Canny(img, 50, 400)[:,:,None]
example = serialize_sample(img[:,:,::-1], edge, classes[i])
writer.write(example)
やり方はこの記事で行った通りです。NumPy配列を.tobytes()して記録しています。
途中でシャッフルを入れているのがポイントかもしれません。tf.data.Datasetでshuffleすると、ある局所的な区間のみシャッフルします。チノちゃんの画像が1万枚、シャロの画像が7000枚のように大量に連続していると、訓練中にシャッフルしてもキャラごとに団子になってしまうので、TFRecordの作成時にシャッフルを入れました。
write_recordを「write_record(“archive/main_dataset/main_dataset”, 320)」のようにデータセットのディレクトリに対して適用します。
TFRecordの可視化
TFRecordを可視化してみましょう。
import matplotlib.pyplot as plt
def deserialize_example(serialized_string):
image_feature_description = {
'image': tf.io.FixedLenFeature([], tf.string),
'edge': tf.io.FixedLenFeature([], tf.string),
'label': tf.io.FixedLenFeature([], tf.string),
}
example = tf.io.parse_single_example(serialized_string, image_feature_description)
image = tf.reshape(tf.io.decode_raw(example["image"], tf.uint8), (320, 320, 3))
edge = tf.reshape(tf.io.decode_raw(example["edge"], tf.uint8), (320, 320, 1))
label = tf.io.decode_raw(example["label"], tf.float32)
return image, edge, label
def read_record():
dataset = tf.data.TFRecordDataset("main_dataset.tfrecord").map(deserialize_example).batch(4)
for x in dataset:
for i in range(4):
fig = plt.figure(figsize=(10, 5))
ax = fig.add_subplot(1, 2, 1)
ax.imshow(x[0][i])
ax = fig.add_subplot(1, 2, 2)
ax.imshow(x[1][i], cmap="gray", vmin=0, vmax=255)
ax.set_title(CHARACTERS[np.argmax(x[2][i])])
plt.show()
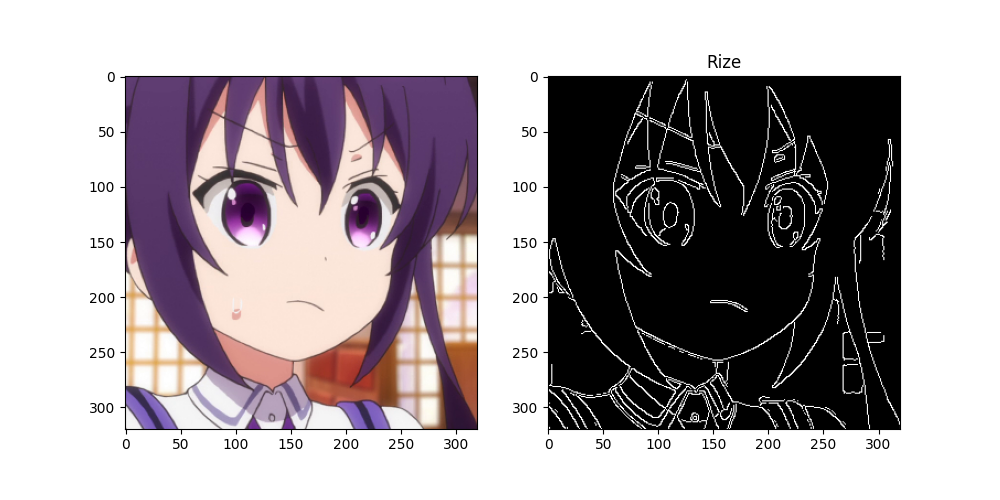
このようにしてTFRecordDatasetで使える形式になりました。
予告
次回の投稿では、モデルの設計や訓練をしていきます。
次回はこちら:https:blog.shikoan.com/gochiusa-03
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー