
論文まとめ:HiQA: A Hierarchical Contextual Augmentation RAG for Massive Documents QA
Posted On 2024-04-11


- タイトル:HiQA: A Hierarchical Contextual Augmentation RAG for Massive Documents QA
- 著者:Xinyue Chen, Pengyu Gao, Jiangjiang Song, Xiaoyang Tan
- 論文URL:https://arxiv.org/abs/2402.01767
- コード・データセット:https://github.com/TebooNok/HiQA
目次
ざっくりいうと
- 大量の区別できない図表を含む文書に対するRAG「HiQA」を提唱した論文
- カスケードメタデータを文章検索メカニズムを統合し、ドキュメント間の比較を可能にし、単純なRAGより大きく精度を向上させた
- 評価データセットとしてMasQAを作成し、公開されている。
はじめに
- 大量の区別されていないドキュメントに対するRAGの問題。
- 具体的なシナリオ
- 様々なiPhoneモデルの製品マニュアルの比較
- 会社の財務報告書、治療マニュアルの比較
- 文章構造は類似しているが、大規模であるタスク
- 具体的なシナリオ
- 先行研究:PDFTriage
- https://www.itmedia.co.jp/news/articles/2309/28/news054.html
- 文章構造をメタ情報に変換してコンテキストを取得(例:ページ5-7、表3)
- これはパーティショニングでセグメントサイズを小さくすることで検索精度を上げる手法
- しかし、文章横断的な検索や多文章比較のような複雑なタスクだと、パーティショニングは重要な情報が失われる
- HiQA(Hierarchical Contextual Augmentation RAG for Massive Documents QA)を提唱
- 複数文書環境における知識検索の精度と関連性を高める
- ベクトルベースの検索の限界を克服
- MDQA(Massive Documents QA)の複雑な要求を扱う
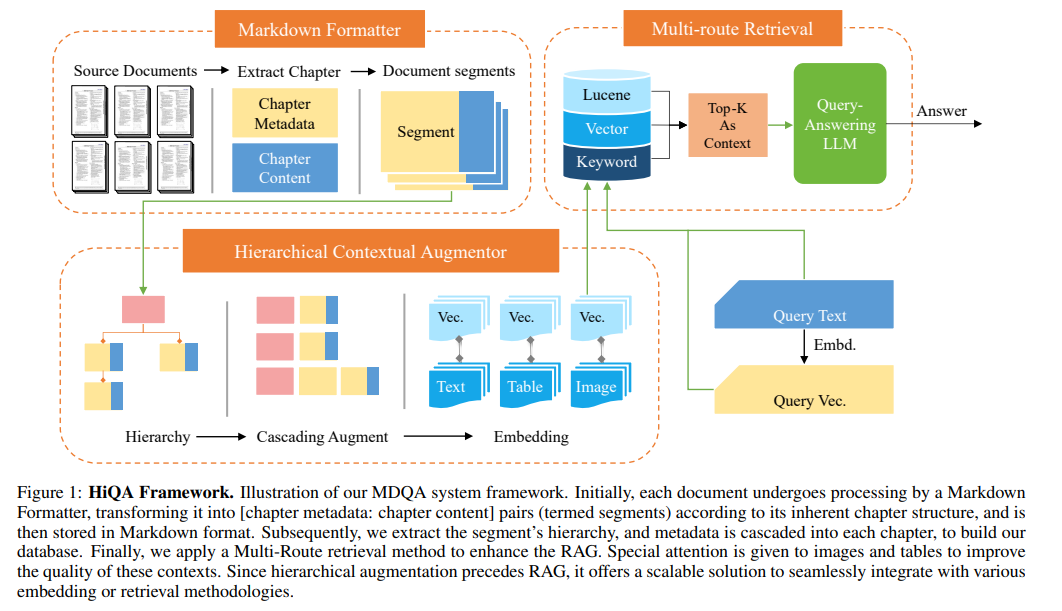
- HiQAのフレームワーク
- 各文章はMarkdown Formatterで処理される
- 固有の章構造に従って、[チャプターメタデータ:章内容]のペア(セグメント)に変換、Markdown形式で保存
- セグメントの階層を抽出して、カスケードに接続してDBを構築
- マルチルート検索法を適用し、RAGを強化
- 画像や表は特有の配慮を行う
HiQAでできること

関連研究
- マルチモーダルRAG
- RA-CM3[Yasunaga et al., 2023]はCLIPをレトリーバーにしたRAG
- 画像生成を取り込むことで精度を大幅向上
- LLMの推論能力を取り込んだRAG
- FLARE [Jiang et al., 2023] は検索が必要かどうかを動的に判断
- Self-RAG [Asai et al., 2023]は特別なトークンを生成をすることで、結果に対するサポートレベルを評価
- マルチドキュメントQA
- 単一の文章より困難なタスク、文章間の関係を区別する必要がある
- 文章間の関係に知識グラフの活用([Lu et al., 2019; Wang et al., 2023] )
- タスクを達成するために3ステップに分解し、簡単な質問によるRAGを統合する([Pereira et al., 2023])
- 本研究
- 既存研究:主に複数の文書間の接続の問題に着目
- 本研究:類似構造を持つ複数文書に対する検索問題に着目
HiQAの手法
3つのコンポーネント
- Markdown Formatter (MF)
- ソースドキュメントを処理し、マークダウンに変換
- 固定サイズのチャンクに変換するのではなく、自然な章に対応し「章メタデータ+内容」の構成
- Hierarchical Contextual Augmentor (HCA)
- マークダウンからメタデータを抽出し、カスケードメタデータを形成。セグメント情報の増大
- Multi-Route Retriever (MRR)
- マルチルート検索で最適なセグメントをみつけ、LLMのコンテクストを提供
Markdown Formatter
- Markdownは優れた構造情報を保持したフォーマッタ
- 文章解析にLLMを採用
- LLMの高度な意味理解能力を利用して、正確な章分割と効果的な表データの復元が可能[Zhao et al., 2023]。
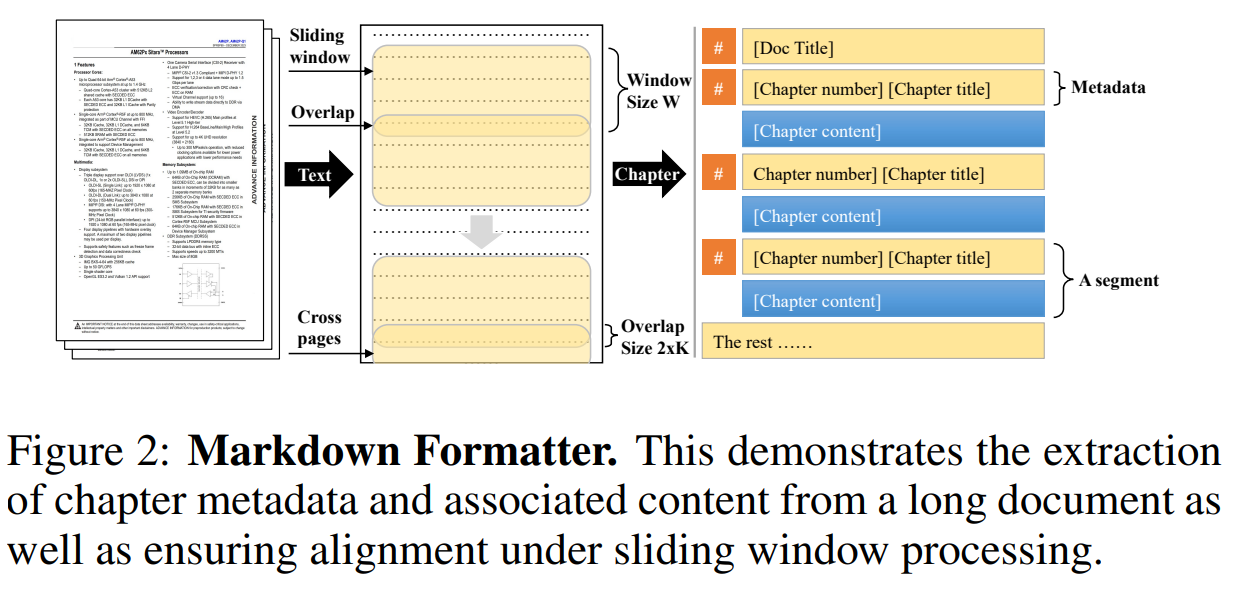
- 文章に対してスライディングウィンドウをかける
- スライディングウィンドウのインデックスがtのときの、マークダウン化のためのLLMの入力
- インデックスtの元文章
- インデックスt-1の元文章
- インデックスt-1のマークダウン(前のインデックスの生成結果)
- LLMの出力
- インデックスtのマークダウン
- スライディングウィンドウのインデックスがtのときの、マークダウン化のためのLLMの入力
インストラクションの精緻化
- 文章内のすべてのセクションを、レベルに関係なく第1レベル(H1)として扱う
- 固定サイズのチャンクではなく、知識セグメントとみなす
- 正しい章番号を設定し、章タイトルを設定する
- Markdown構造でテーブルを生成し、テーブルのタイトルを記録
画像
- PDFImageSearcherというOSSを開発した
- 画像からビットマップやSVG画像を抽出
- VLMを使い、書く画像ファイルのキャプションファイルを生成
Hierarchical Contextual Augmentor
テキスト増強
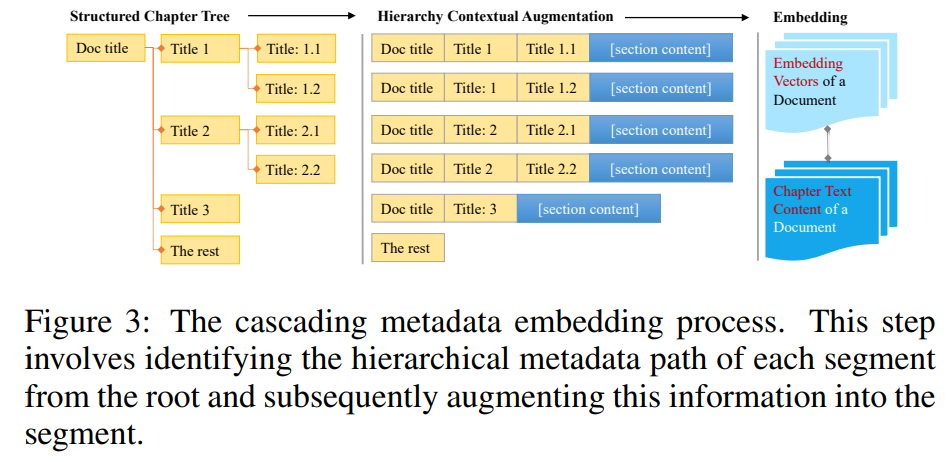
カスケード接続メタデータ:階層構造の章構造に対し、「Hierarchy Contextual Augmentation」を行う
表増強
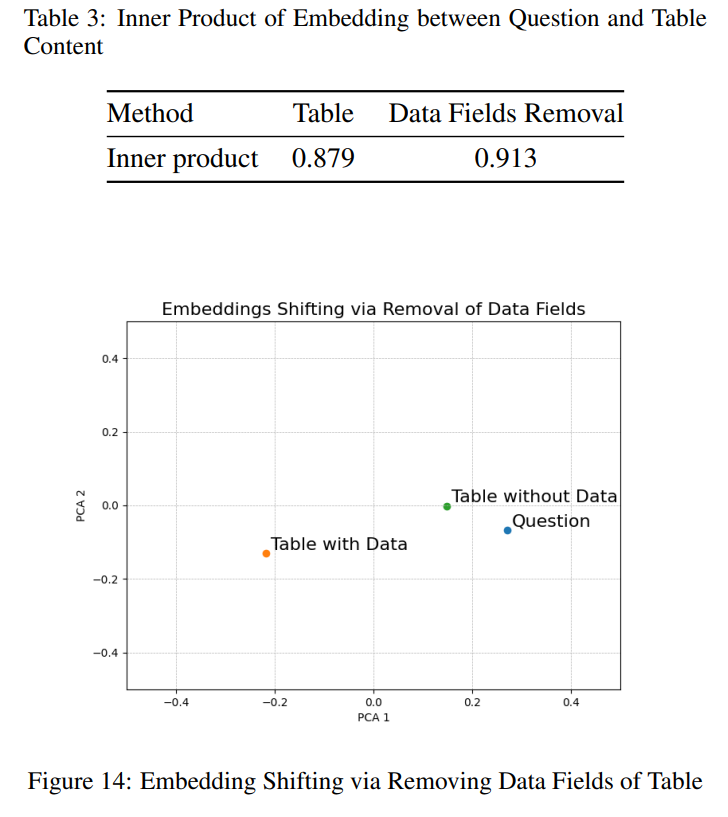
- 数値データは、QAには有用だが、Embedding計算では悪影響があるので除外
- テーブルに対して、Embeddingを計算して検索したら、数値データを抜いたほうが、そのままよりも質問文との内積が向上した(類似度が上がった)
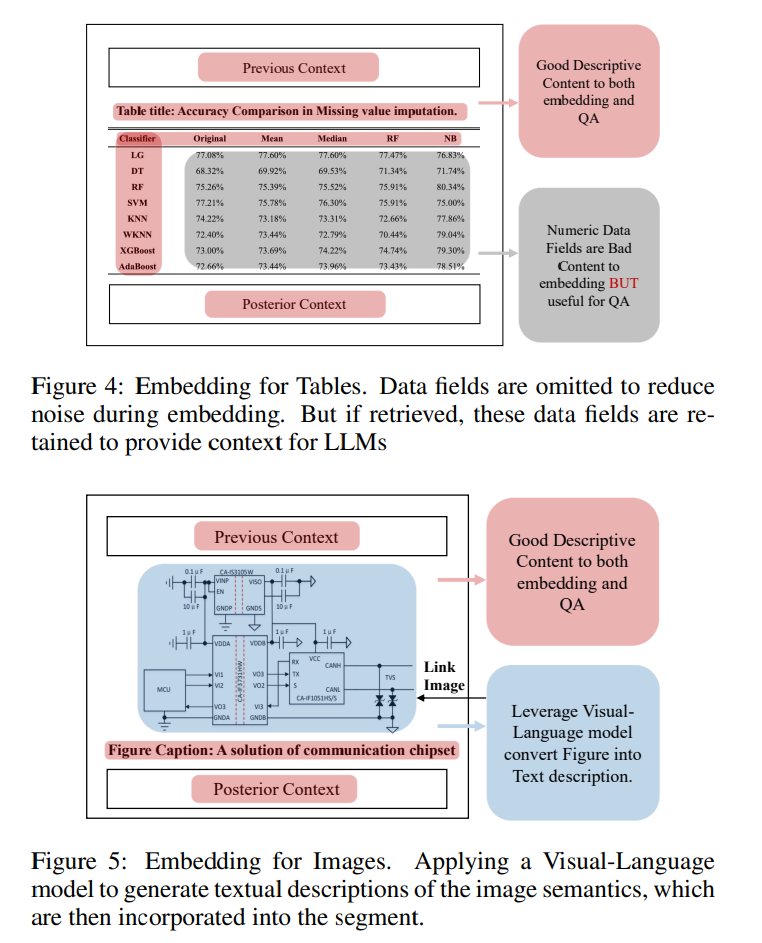
画像補強
VLMを使って図をキャプションに変換
Multi-Route Retriever
3つの手法を用いて検索を実施
- ベクトル類似度マッチング
- Elastic Search
- 単語レベルの精度のベクトルマッチングの限界を補う
- キーワードマッチング
- 名前付き固有表現検出モデルを用い、クエリと文章から重要なキーワードを抽出
- Critical Named Entity Detection法を採用
- 文章コーパスに内在するキーワードを活用し、重みを制御するElastic Searchの限界に対処
3つの検索手法からリランキング
score = α ·scorev + (1 − α)·scorer + β · log(1 + |C|)
- α、Β:ベクトル類似度と情報検索スコアをバランスさせるハイパーパラメーター
- |C|:マッチングされた重要なキーワードの数
データセット
MDQAのRAGの評価指標
- RAGASと異なる、Log-Rank Indexを導入
- RAGASの問題点
- RAGASは質問と回答を生成するためにLLMに大きく依存し、さらにノイズやハルシネーションを拡大させるおそれがある
- 質問と回答の質がLLMに大きく影響され、RAGプロセスの実際の質を覆い隠してしまう
- top-kの結果に焦点をあてている。top-kは短い文章では有効だが、ターゲット知識がtop-kランキングを作れない大規模文章コーパスではスコアは0になる
- 非線形対数順位関数を利用し、高順位領域でより敏感になるようにする

※参考:https://www.youtube.com/watch?v=DUvBtpy4Fb4
(私の注釈):Ranked listの抽出を評価するのは有効だが、RAGのGの部分を評価できていないのでは? 具体的には、チャンクの抽出を評価する際には有効だが、この評価方法は生成結果を評価できていない。ただ、そこはLLMの性能次第なので、一旦無視してしまうという方針なのだろうか?
MasQAデータセット
評価データセットを作成。
- どこからデータを取るか?
- テキサス・インスツルメンツの技術マニュアル:PDF18個、各PDFにつき約90ページ。画像テキスト表を含む
- Chipanalogの技術マニュアル:PDF88個、各PDFにつき20ページ、2カラム。画像テキスト表
- 大学のテキスト:660ページからなり、画像テキスト表数式を含む
- 上場企業の財務報告書:8個のレポート、各200ページ。画像テキスト表
- 質問集
- 単一、複数の選択肢問題
- 記述式問題
- 複数のエンティティの比較
- 文章間の比較
- 計算問題
MasQAデータセットはGitHub上で公開されている
https://github.com/TebooNok/HiQA/tree/main/datasets
結果
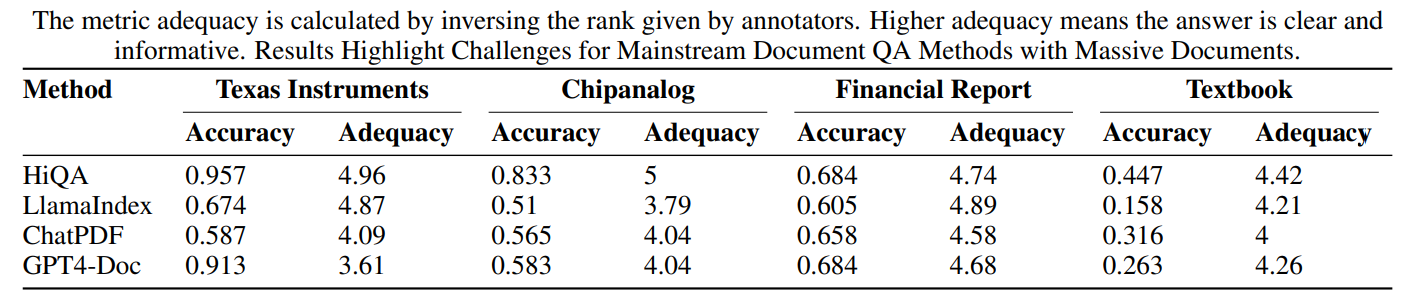
- Accuracy:評価データセットのQAに対する正解率
- Adequacy:人手での評価
- 本アプローチはHCAの統合により、トークンを2k以内に制限し、他の方法で使用される平均4kとは異なる
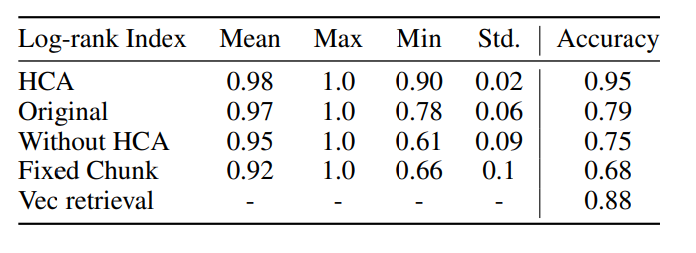
- HCA:本研究で提案したHCAを利用した場合
- Original:章のメタデータは使うものの、カスケードを用いない場合
- Without HCA:さらに章のメタデータを除外
- Fixed Chunk:チャンクサイズを固定にする
- Vec retrieval:MRRを除外し、ベクターだけの検索
Log-rank IndexがAccuracyと連動している
Embedding
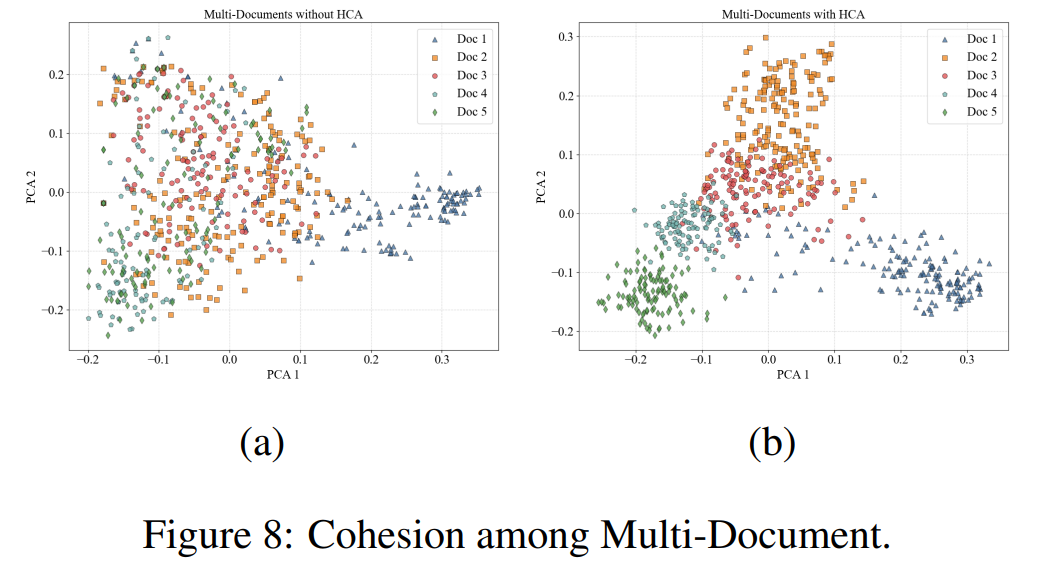
理論的な分析として、Embedding空間をPCAしている。HCAをいれたほうが複数ドキュメント間でのEmbeddingがきれいになった。他にもいろんな切り口でのEmbeddingを比較しているが、きれいになっている
所感
- かなり実用的な内容
- HCAの有効性は非常によく議論されていてよかった
- LogRank Indexの部分はいまいちよくわからなかった
- MasQAデータセットも公開されているのが◎
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー