
HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems


- タイトル:HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems
- 著者:Jiejun Tan, Zhicheng Dou, Wen Wang, Mang Wang, Weipeng Chen, Ji-Rong Wen(中国人民大学、百川智能)
- 論文URL:https://arxiv.org/abs/2411.02959
- コード:https://github.com/plageon/HtmlRAG(MIT)
- モデル:https://huggingface.co/zstanjj/HTML-Pruner-Phi-3.8B
目次
ざっくりいうと
- RAGシステムにおいて、検索された外部知識としてHTMLを直接利用し、プレーンテキストへの変換による構造情報や意味情報の損失を防ぐことで、LLMの性能を向上させる手法を提案。
- HTMLの長さや冗長性の問題を解決するために、HTMLのクリーニングと2段階の刈り込みブロック(埋め込み、生成モデル)を組み合わせた効率的な処理方法を開発。
- 6つのQAデータセットで評価し、従来のプレーンテキストやMarkdownベースの方法と比較して、一貫して性能が向上することを示した。
要約 By Gemini1.5 Pro
この論文について、各質問に一問一答形式で回答します。
・この論文において解決したい課題は何?
RAGシステムにおいて、検索された外部知識をLLMに渡す際に、HTMLからプレーンテキストへの変換によって構造情報や意味情報が失われ、LLMのパフォーマンスが低下する問題を解決したい。
・先行研究だとどういう点が課題だった?
先行研究のRAGシステムは、主にプレーンテキストを外部知識として利用しており、HTMLの構造や意味情報を十分に活用できていなかった。また、HTMLを扱う先行研究も、HTMLをそのまま入力するには長すぎる、ノイズが多いなどの課題があった。
・先行研究と比較したとき、提案手法の独自性や貢献は何?
HTMLをRAGシステムの外部知識として直接利用することを提案し、HTMLのクリーニングと構造を考慮した2段階のプルーニング手法を開発した点が独自性であり貢献。これにより、HTMLの構造情報と意味情報を保持しつつ、LLMへの入力長を適切に制御できる。
・提案手法の手法を初心者でもわかるように詳細に説明して
- HTMLクリーニング: Webから取得したHTMLから、CSS、JavaScript、コメントなど、意味的に無関係なコンテンツを削除し、冗長な構造を圧縮する。
- ブロックツリー構築: クリーニングされたHTMLを、一定の単語数(例えば256語)を上限とするブロックに分割し、ツリー構造を構築する。これにより、HTMLの構造を保持しつつ、処理を効率化する。
- テキスト埋め込みに基づくブロックプルーニング: 各ブロックのテキストとユーザーのクエリとの類似度を埋め込みモデルで計算し、類似度の低いブロックを削除することでHTMLを短縮する。
- 生成モデルに基づく細粒度ブロックプルーニング: 前段階でプルーニングされたHTMLをさらに細かいブロックに分割し、生成モデルを用いて各ブロックのスコアを計算する。スコアは、ルートタグからブロックのタグまでのパスとブロックの内容を生成する確率に基づいて計算される。スコアが低いブロックを削除し、最終的なHTMLを生成する。
・提案手法の有効性をどのように定量・定性評価した?
6つのQAデータセット(ASQA、HotpotQA、NQ、TriviaQA、MuSiQue、ELI5)を用いて、Exact Match、Hit@1、ROUGE-L、BLEUなどの指標で評価。提案手法HtmlRAGは、プレーンテキストやMarkdownベースの先行研究と比較して、全てのデータセットにおいて同等以上の性能を達成した。
・この論文における限界は?
ブロックツリーの粒度調整や生成モデルの学習データ作成など、ハイパーパラメータの設定に依存する部分がある。また、非常に複雑なHTML構造や動的に生成されるHTMLへの対応は今後の課題。
・次に読むべき論文は?
論文中で紹介されている関連研究、特にポスト検索処理に関する論文(例:[19, 22, 66])や構造化データ理解に関する論文(例: [9, 68])を読むと、この研究の文脈をより深く理解できる。また、埋め込みモデル(例:[65])や生成モデル(例:[1])に関する論文も参考になる。
コードへのリンク:
https://github.com/plageon/HtmlRAG (論文中に記載されている)
イントロ
- HTMLの課題
- プレーンテキストに変換するとページの情報損失が起きる
- Web上のHTML文章はトークン数長すぎ(80kトークン以上)。90%以上がCSSやJavaScriptなど無意味なトークン
- ネストされたタグをマージ、空タグの削除などによりHTMLを6%に削減
- 既存のRAGシステムのリファイナー→チャンクベースではHTMLの構造を考慮してない
- 提案手法の位置づけ
- HTMLのRAGシステムにおいて、HTMLを知識の形式とすることを提案
- シンプルだが効果的なHTMLクリーニングアルゴリズムを提案
- 2段階のHTML刈り込みアルゴリズムを提案。ほとんどRAGシステムに適用できる
関連研究
- RAGの検索後のプロセス
- リファイナー
- 既存のリファイナーは全てプレーンテキストベース→不合理なチャンク生成を生じる
- 抽象的なリファイナーは計算コストが高い
提案手法
- 元のHTMLを漸次的に刈り込む
- HTMLクリーニングモジュールで、無駄な要素やタグを削除
- 2段階の刈り込み構造で、HTMLを洗練させる
- 入力クエリと埋め込み類似度が低い、重要度の低いHTMLブロックを削除
- 生成モデルによる細かいブロック刈り込み
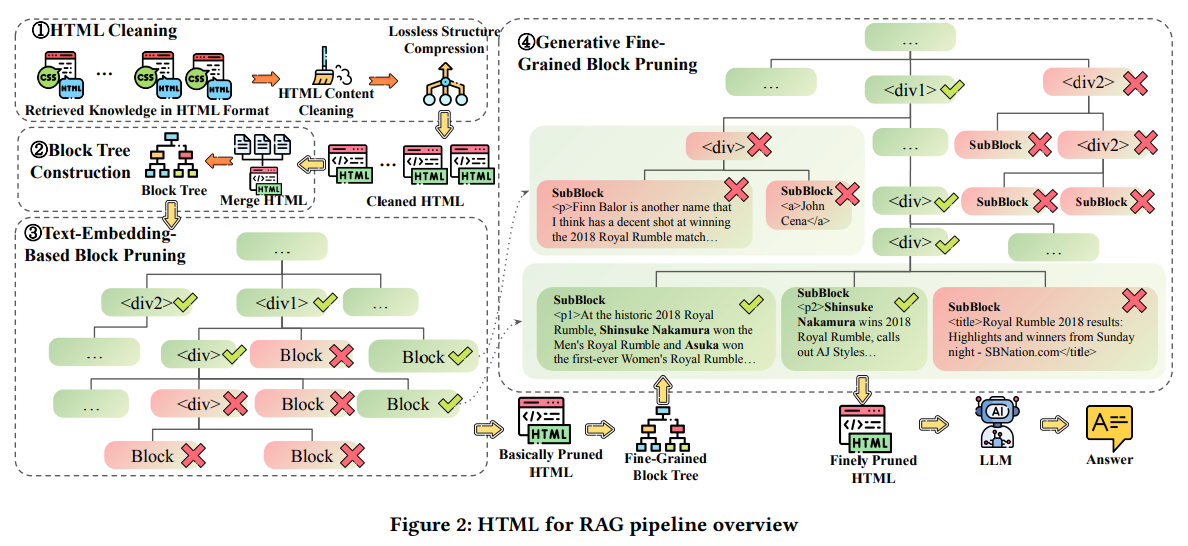
HTMLのクリーニング
- CSSスタイル、コメント、JavaScriptタグを削除
- 長いHTMLタグ属性を削除する(訳注:おそらくインラインのCSSやTailwind CSSのようなクラス)
- HTML構造の冗長性の消去
- 例:
<div><div><p>some text</p></div></div>→<p>some text</p>
- 例:
ブロックツリーの構築
- DOMのブロックに相当するツリー構造が必要。Beautiful Soupを使う
- 多数のノードと深いツリー構造は膨大な計算量。ツリー構造をマージして計算量を削減
maxWordsというパラメーターを設定し、子ノードがその文字数を超えないように再帰的にマージしていく
意味ベースのブロックツリーの刈り込み(1段階目)
- ブロックのEmbeddingを取り、ユーザーのクエリとの類似度を取る。限界が2点ある
- 埋め込みモデルのコンテクストウィンドウの制限
- 各ブロックが意味的特徴を得るのに十分な長さではないため、細かい粒度のブロックツリーを扱えない
- BGE-Large-EN を使用
生成的細かい粒度のブロックの刈り込み
- LLMに刈り込みさせるのは元のHTMLよりトークン数が多くなってしまうため不適。ゼロショットのLLMでは精度が出ない
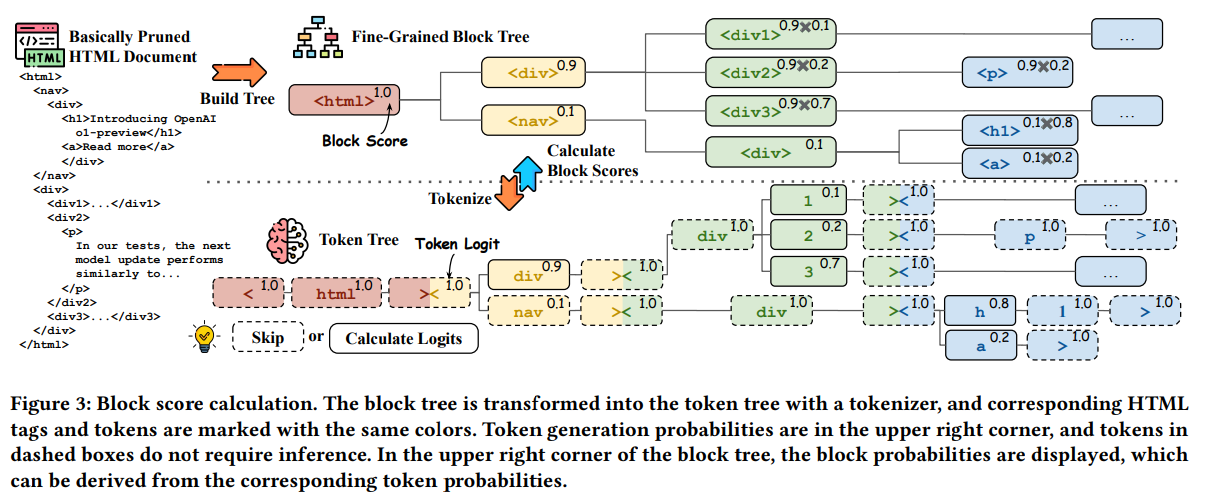
- HTMLタグをトークンに見立てて、どれが回答に関連するタグかを計算するロジットスコアを学習するモデルを学習
- 学習データの作成は、典型的なSFTプロセスに従う
- オープンソースのQAデータセットのトレーニングセットからクエリをサンプリング
- Bingを使用して関連するHTMLドキュメントを検索
- HTMLをクリーニングし、埋め込みモデルでHTML刈り込む
- ブロックツリーを構築し、ゴールドの答えとの完全一致スコアを計算
- 2Kから32Kまで自動構築された学習サンプル
- Phi-3.5-Mini-Instrcutを使用
- ファインチューニングされたモデルは公開されている:https://huggingface.co/zstanjj/HTML-Pruner-Phi-3.8B
結果
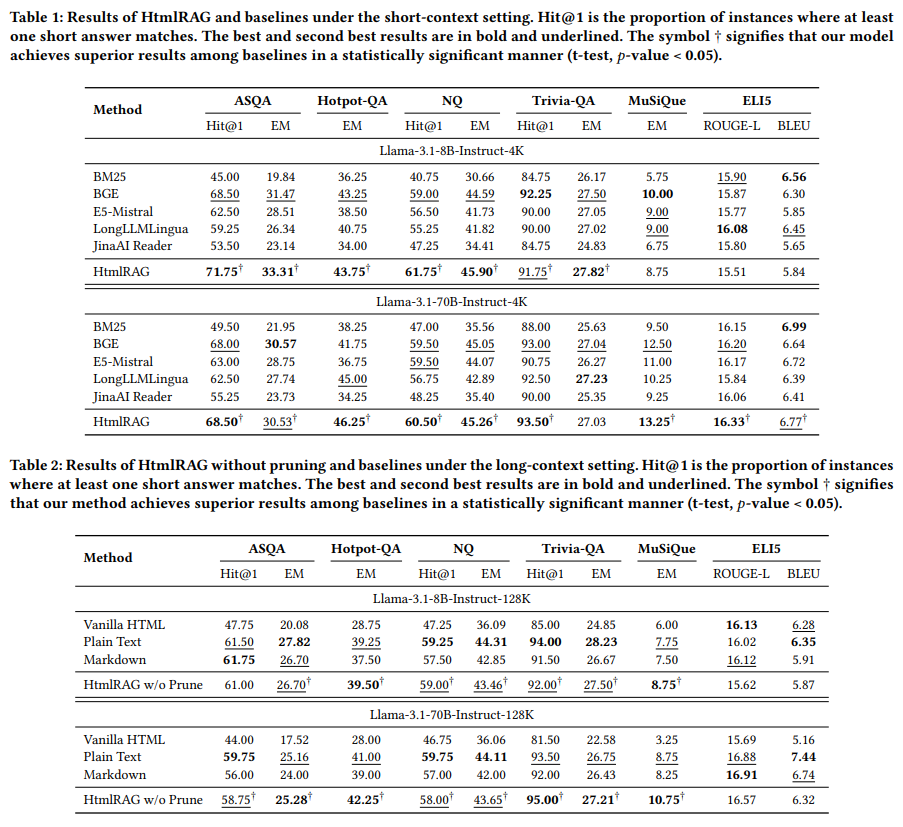
差分が少ない? (訳注:評価データセットがテキストベースで答えられるものだからいけないのかも? テーブルデータの解釈のようなタスクなら変わっていたのか?な)
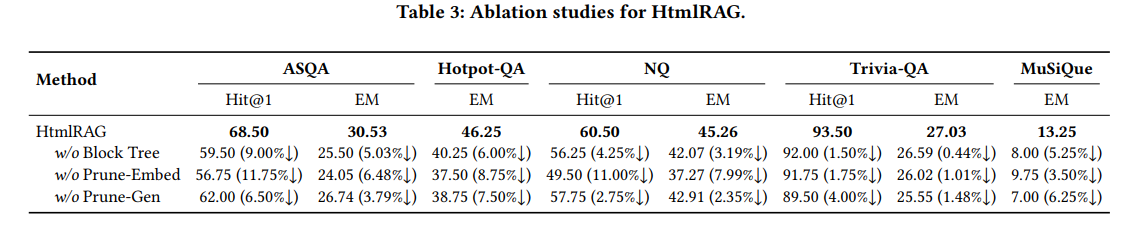
アブレーションによると、一番効いているのがEmbedding。データセットによっては(Trivia-QA、MusiQue)は生成モデルの刈り込みが効いている。
所感
- 発想は面白い。特に生成モデルによるロジットスコアの算出。比較的軽いモデル(3B)なので、頑張ればファインチューニングできるレベル
- 既存データセットでは差分を作り出すのに課題がありそうな感。評価データセットが違えばもっと差分がわかりやすかったのだろうか?
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー