
論文まとめ:Guided Image Synthesis via Initial Image Editing in Diffusion Model
Posted On 2023-05-11


- タイトル:Guided Image Synthesis via Initial Image Editing in Diffusion Model
- 著者:Jiafeng Mao, Xueting Wang, Kiyoharu Aizawa(東京大学、CyberAgent)
- URL:https://arxiv.org/abs/2305.03382
目次
ざっくりいうと
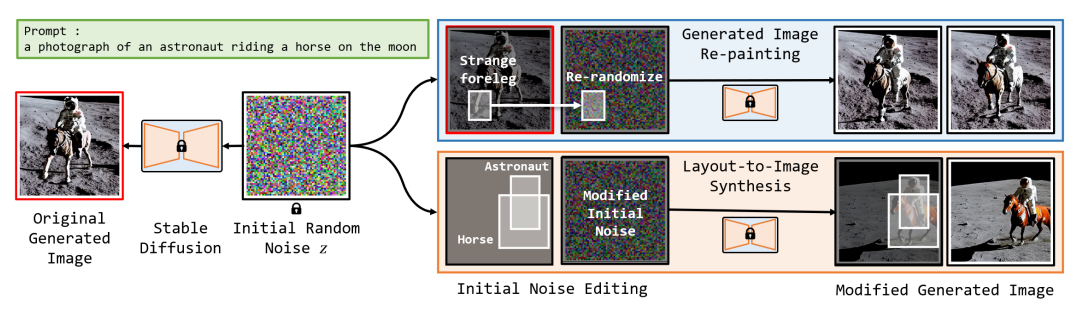
- 拡散モデルの初期ノイズを操作することで、画像生成の失敗部分の編集を可能にする研究
- 初期ノイズの画素値が、生成結果に大きな影響を与えることを発見
- Attention Mapとノイズの集約を組み合わせることで、レイアウト制御に応用可能
はじめに
- 拡散モデルはノイズを初期値とし、プロンプトで条件付け(Cross Attention)することで画像を生成する
- 従来の方法:スケッチガイド、Attentionによるガイド、サブネットワーク……
- この研究の新しいポイント:初期のノイズの画素値が生成画像に影響を与えることを発見し、初期ノイズを操作することで画像編集やレイアウトコンロールをしようとした点
- 私の所感:初期値をいじいじするのは経験的によくやっているので、研究で出てて「おー!」となったから。レイアウトコンロールするのは結構むずくて需要がある
手法
ノイズの部分的な再ガチャ
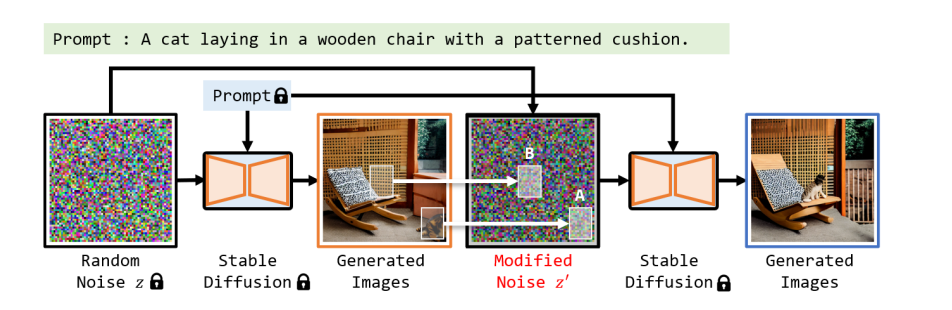
- 生成画像が部分的におかしい部分があったとする(Generated Images)
- 本来いてほしい場所に猫がいない
- 右下に猫らしき変なものが出現している
- 変えたい部分のみ乱数を再ガチャして生成すれば、残りの構図は維持される
- 私の所感:顔や手がおかしくなった場合にめっちゃ使えそう。高解像度の人間分裂現象にも使えるかも?

画像生成が失敗する理由
- 初期ノイズ画像の生成傾向とユーザーが与えたプロンプトとの間に矛盾があること
- ユーザーが互いに近い2つの物体を生成することを意図しているにもかかわらず、ランダムに生成された初期ノイズにおいて、これらの物体を生成する傾向がある2つの領域が離れている場合、目的のコンテンツを生成できない
- Attention Mapにマスクを追加して、指定した領域に指定したオブジェクトが生成される確率を高めることで、レイアウト対画像の生成を目指す手法もある
- しかし、初期画像上のユーザが指定した領域が、指定したコンテンツを生成する傾向が低い場合、そのような領域に無理にマスクを追加することは、通常、失敗につながる。
- 私の所感:Attention Couple(Attention内部でマスクをかけて、局所的に別々のプロンプトをかける手法の通称)でも失敗するときは失敗するのでわかりみが深い
Layout-to-Image
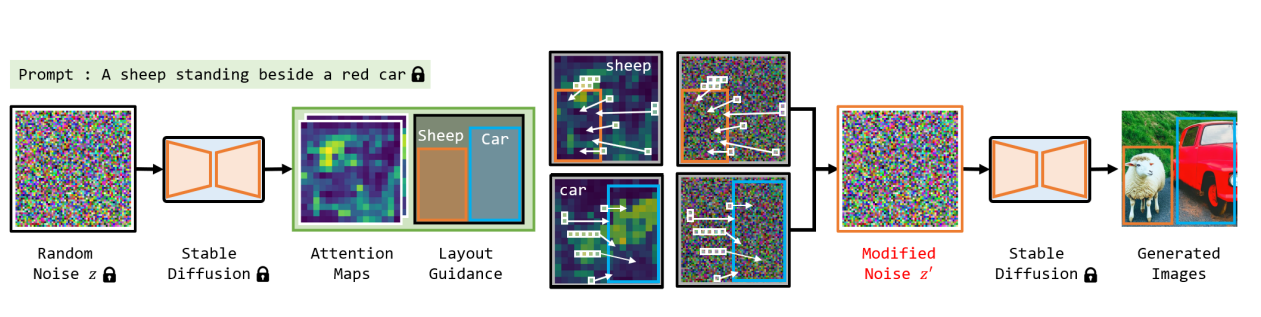
- 初期値編集の応用手法として、Attention Mapを使ったレイアウトコントールもできる
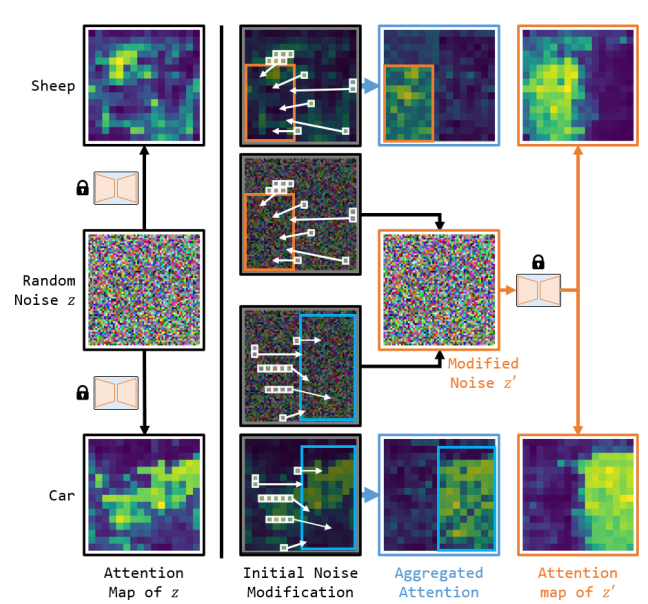
- Attention Mapとは以下のようなもの
- 本手法では、指定領域外のAttention Mapが高い部分のノイズと、領域内のAttention Mapが低い部分のノイズを入れ替えることでレイアウトコンロールを実践
- 入れ替えは、領域内外のAttention Mapの値のmin-maxをとる

- 「bus and car, best quality, extremely detailed」というプロンプトで画像生成したもの
- トークン単位で、それぞれどの領域に注目しているかを可視化したもの
- 「bus」が2つ目(1段目真ん中)、「car」が4つ目(2段目の左)
- U-Netの内部のCross AttentionのSofttmax値をとってくることで計算可能
- 私の所感:自分が「bus and car」で1枚に作ってそれぞれ入れ替えようとしたらあまりうまくいかなかったが、busとcarを別々に作って集約したのち、1枚で作ることがコツなのかもしれない
- LoRAでめっちゃ使えそう
- ありがちな疑問:Attention Mapベースで集約してノイズの特徴空間歪まないんですか?
- ガウスノイズは系列間で独立なので、その心配はいらないです
結果
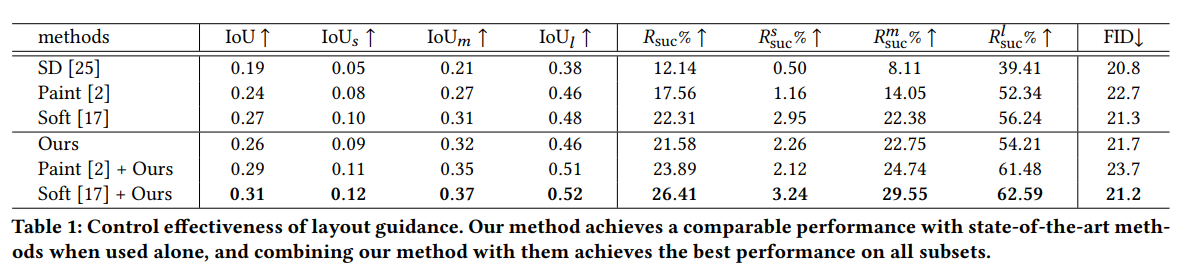
- データセットはCOCOを使い、YOLORで物体検出してIoUを比較
- 頑張るとこんなことができる

所感
- Attention Mapからノイズ入れ替えるところは目から鱗
- Diffusersでテキトーに実装してみたが、Attention Mapの値を取り出さないといけないので、PyTorch2.0のscaled_dot_product_attentionが使えなく、従来の書き方でAttentionを実装しないといけないためVRAM消費量が多い
- HD生成しようとすると今までは溢れなかったのに、普通に溢れた
- 数時間でテキトーに実装した方法だと、オブジェクトの左右を入れ替えるような、Layout Guidanceはあまりうまくいかなかった。ただ、Attention Mapとの関係を見ていると納得がいくので頑張ればできるかもしれない?
- なんとなく雰囲気で実装したが、あまりうまくいかなかったからコード公開してほしいなー
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー