
論文まとめ:Imagen Video: High Definition Video Generation with Diffusion Models
Posted On 2022-10-13


- タイトル:Imagen Video: High Definition Video Generation with Diffusion Models
- 著者:Jonathan Ho*, William Chan*, Chitwan Saharia*, Jay Whang*, Ruiqi Gao, Alexey Gritsenko, Diederik P. Kingma, Ben Poole, Mohammad Norouzi, David Fleet, Tim Salimans*
- 所属:Google Brain
- プロジェクトページ:https://imagen.research.google/video/
- コード:現時点で公開する気はないらしい
目次
ざっくりいうと
- Googleが約半年前に発表した画像生成モデルImagenの動画への拡張
- 空間方向、時間方向への畳み込み・Attentionを交互に使い、画像生成モデルをほぼそのまま動画へと拡張した
- T5のエンコーダー、v-prediction、画像・動画の同時訓練の有効性を実証。高画質の動画生成や、動画へのスタイル転移を可能とした
Imagen復習
Imagenは、Googleが2022年5月に発表した、Text-to-imageの画像生成モデル。潜在空間での拡散モデルを導入し、エンコーダーとしてCLIPではなくT5(テキストのみ)を使用することで、Latent Diffusionよりも高い性能を出した。
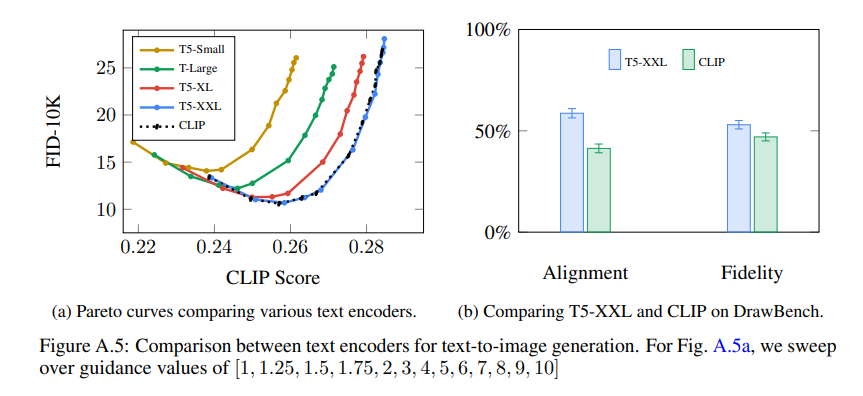
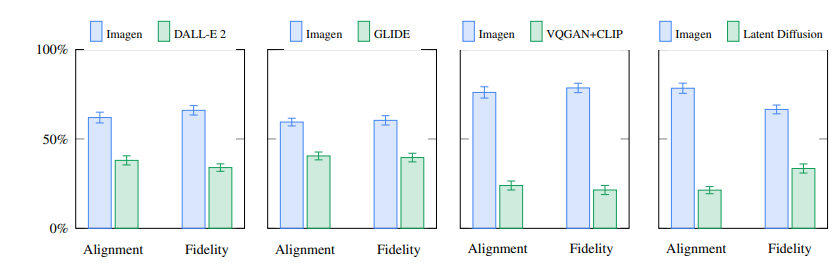
いずれもImagenの論文より。
Imagen Video
カスケード拡散モデル
カスケード拡散モデル(Cascaded Diffusion Models):低解像度で画像や動画を生成し、超解像拡散モデルで画像や動画の解像度を上げていく。
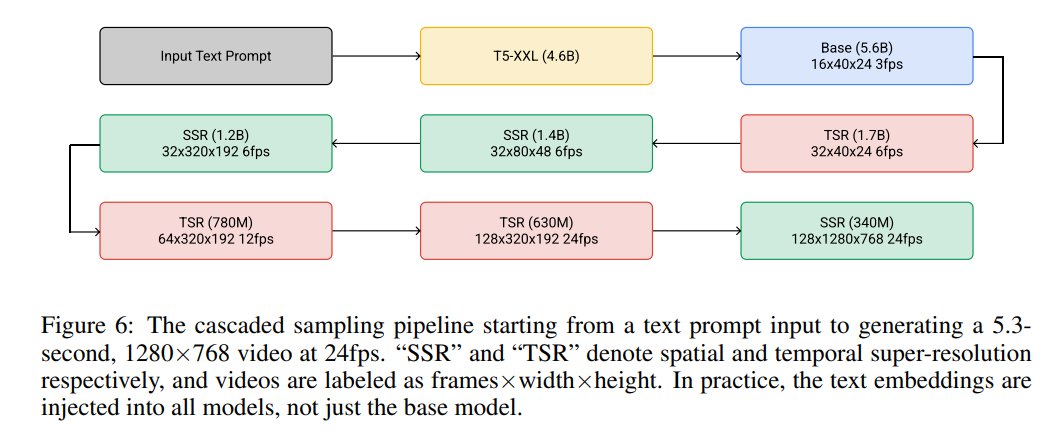
空間方向(SSR)・時間方向(TSR)の超解像モデルを互いに組み合わせていく
動画拡散モデル構造
画像の拡散モデルの場合は、典型的には2DのU-Netを使っている。時間方向、空間方向にそれぞれ畳み込み・Attentionをかけることで3Dへと拡張した。
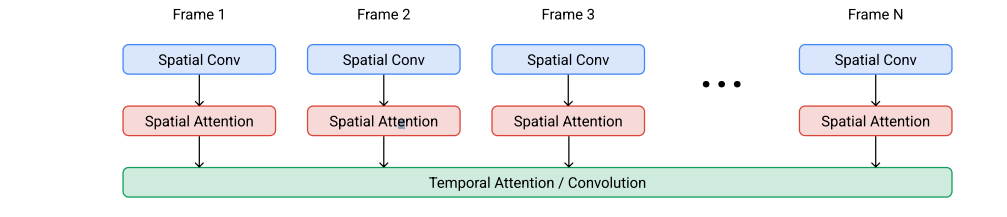
- 空間方向の演算:パラメータを共有しつつフレームごとに独立
- 時間方向の演算:フレーム間で混合させて演算で活性化を混合させる。
- 使用するレイヤー
- 基本モデル:空間Conv、空間Self Attention、時間Self Attention
- 空間・時間の超解像モデル:Attentionのかわりに時間Conv(計算量を下げるため)
- 最高空間解像度のモデル:空間Attentionなし
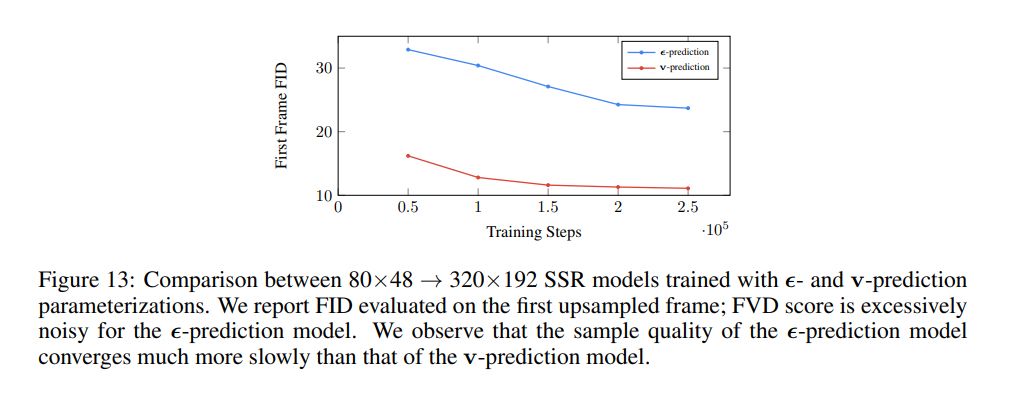
v-prediction
先行研究にもとづき、v-predictionというテクニックを使っている。少ないサンプリングステップでより高い安定性を実現するためのもの。
Conditioning Augmentation
先行研究にもとづき、Conditioning Augmentationと導入している。カスケードの1つのステージの出力と後続のステージで、入力との間のドメインギャップの影響を低下させるため。
画像と動画を同時に計算する
先行研究にもとづく
- 画像と同時を同時に訓練すると生成結果が大幅に向上する
- 個々の独立した画像を、動画と同じ長さのシーケンスとして固める
- 時間的な畳み込みや、Attention Mapをマスクすることで、フレーム間の計算を無効にする
- 同時に画像から動画への知識転移が可能になった(ゴッホの絵を動画にする)

社会への影響
コードやモデルをリリースしない理由
- T5が問題のあるデータで訓練されているソース
- 内部テストでは、性的・暴力的なコンテンツの多くをフィルタリングできたが、社会的偏見とステレオタイプはまだ検出困難なため
感想
- Imagenから素直に進歩させたなという印象。潜在変数に対して超解像モデルを適用するだけで、動画生成できるのは面白い
- 研究的に新規性のある概念はあまり登場していなく、Googleが計算資源と知名度で殴った印象はなくはない
- 拡散モデルの先行研究Tipsがいろいろ登場していて、サーベイ的な読み方するには面白い
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー