
論文まとめ:InstructPix2Pix: Learning to Follow Image Editing Instructions
Posted On 2023-01-26


- タイトル:InstructPix2Pix: Learning to Follow Image Editing Instructions
- 著者:Tim Brooks, Aleksander Holynski, Alexei A. Efros(カリフォルニア大学)
- 論文URL:https://arxiv.org/abs/2211.09800
- コード:https://github.com/timothybrooks/instruct-pix2pix
- プロジェクト:https://www.timothybrooks.com/instruct-pix2pix
目次
ざっくりいうと
- 画像に対して、テキストで直接指示を与えて、編集後の画像を対話的に生成するモデル
- GPT-3, Stable Diffusion, prompt-to-promptを使い訓練データセットを自動で生成した点が新規性
- CLIPによるデータのノイズ除去、元画像vsプロンプトのトレードオフコントロールなどの工夫

ニュース
- https://twitter.com/Yamkaz/status/1617643476866437129
- https://twitter.com/Yamkaz/status/1618028421581524992
- https://twitter.com/Yamkaz/status/1618360600949841920
- https://twitter.com/_akhaliq/status/1617849296170225665
概要
- GPT3とStable Diffusionで、Input-Editedのプロンプトと画像が対応された、ペアのデータセットを自動生成
- ペアの学習データを自動作成するというのが本研究の新規性
- データセットで拡散モデルを訓練すると、画像編集を学習するため、追加学習の必要がなく画像編集が可能に
- Stable Diffusion単体だと、画像編集を学習できていないため、別途学習が必要
関連研究
画像編集の生成モデル
- StyleGANの潜在空間に変換
- CLIP類似度を最大化するような画像レイヤーを最適化(Text2Live)
- Prompt-to-Prompt
- プロンプトベースでの画像編集という点では同じ
- 類似のプロンプトが類似の画像を生成する保証がないという問題に取り組んだ
- SDEdit
- ターゲットプロンプトを持つ入力画像にノイズを与え、ノイズを除去
- この研究のベースライン
手法
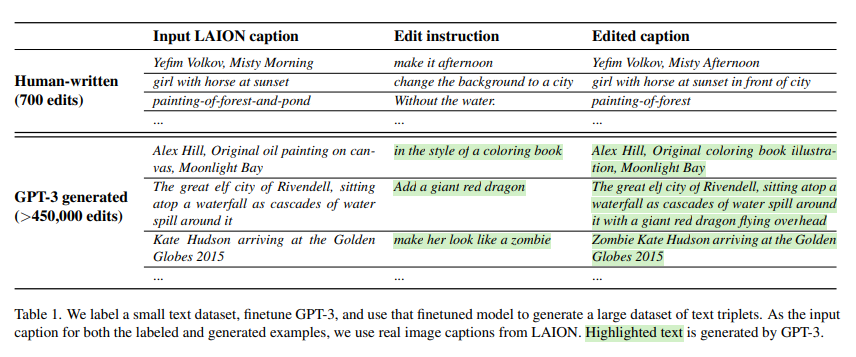
データセットの生成
編集プロンプトのデータ作成
- 最初に少量(700)の手書きデータを与えて、GPT-3をファインチューニング
- GPT-3 Davinciを1エポック、デフォルト設定
- ファインチューンしたGPT-3で大量のデータ(45万以上)を作成
- 入力キャプションはLAIONデータセット
- 長所は内容の多様性(固有名詞や大衆文化)、媒体の耐用性、サイズが大きい
- 欠点はノイズが多い→対策を追加
ペア画像の作成
- Stable Diffusion+Prompt-to-prompt
- 最初の画像はStable Diffusionで作る
- 編集後の画像はそれをPrompt to promptで変換
- Prompt-to-promptがないとプロンプトを少しいじっただけで全く別の画像が出てくる
- Prompt-to-promptにはノイズ除去の値pがあり、p ∼ U(0.1, 0.9)と一様乱数にすることで、編集の幅を確保した
- CLIPベースのフィルタリングで、Stable DiffusionやPrompt-to-promptの失敗をカバー

訓練
モデルの訓練
- Stable Diffusionをベースに訓練
- A100が8枚で25.5h。256 × 256の解像度でbatch sizeは1024
- 推論時に512×512としても問題ない。推論は100stepでA1001枚で9s
Classifier-free Guidance for Two Conditionings
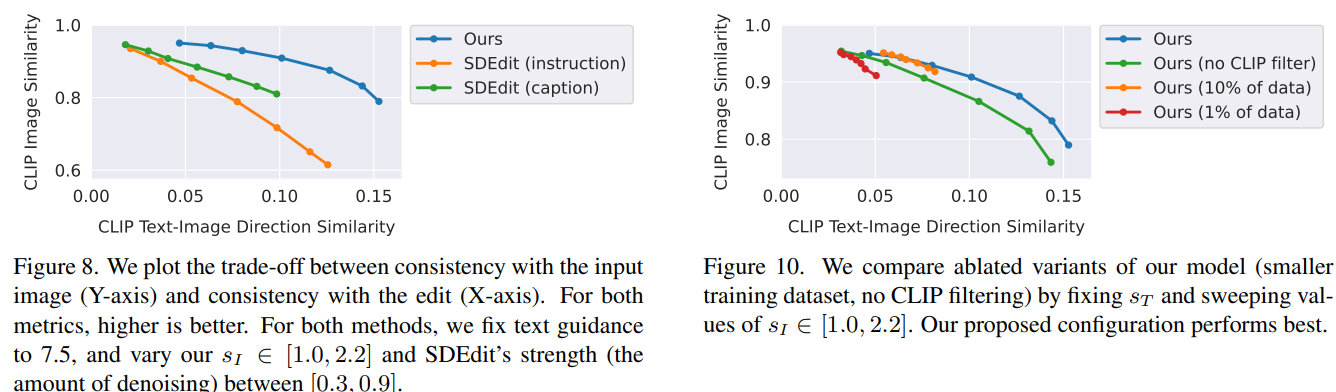
元の画像とどのぐらい一致させるか(s_I)、出力画像にどの程度一貫性を持たせるか(s_T)というトレードオフがある。

これを2つのパラメーターからスコアリングする手法を作り、トレードオフをコントロールする
結果
SDEditよりも良い結果を示した(左)
s_Iを変化させて実験(右)
- データセットに対する、CLIPによるフィルタリングを抜くと、入力画像との整合性が低下する
- 縦軸のCLIPスコアが小さくなる
- データセットを小さくすると、画像を大きく編集する能力が落ちる
- 横軸の方向性スコアが小さくなる
成功例・失敗例

物の数を数えることや空間操作(「画像の左に移動させる」、「位置を入れ替える」、「コップを2つテーブルに置き、1つを椅子に置く」)に苦戦。Prompt-to-promptと同様の失敗

連鎖的な指示による生成も可能

著者らによる議論
- モデルの性能が頭打ちになる要素
- GPT-3をファインチューンするため人間が書いた指示
- GPT-3の指示作成能力とキャプション修正能力
- 生成画像を修正するPrompt-to-Promptの能力
- 物体を数えることや、空間操作が難しい
- Human-in-the-Loop強化学習のような戦略が今後有効ではないか
私の所感
- GPT-3、Stable Diffusion、Prompt to promptを使って、データセットを自動生成するのがとても面白い(編集に限らず、Image-to-Imageのタスクはペアデータを用意するのが大変なため)
- 指示ベースでインタラクティブに生成していくと、発注者とクリエーターのやり取りを模倣しているようで、(ビジネス的には)相性は良さそう
- (キャプションベースか、指示ベースかの違いはあるとはいえ)Prompt-to-promptとの差分がいまいち分かりづらい。編集後の画像をPrompt-to-promptで作っているため、定量的にはPrompt-to-promptと大して変わらないのではないか
- 一時期GANでもData Augmentationやデータの自動作成の話はあったが(あって立ち消えになったが)、当時と比べるとモデルのゼロショットや外挿能力が著しく上がっているので、別途議論してもいいのではないか
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー