
Kerasで重みを共有しつつ、必要に応じて入力の位置を変える方法


Kerasで訓練させて、途中から新しく入力を作ってそこからの出力までの値を取りたいということがたまにあります。例えば、Variational Auto Encoderのサンプリングなんかそうです。このあまり書かれていないのでざっとですが整理しておきます。
目次
こういうことをやりたい
言葉で書いても伝わりづらいのでこういう例です。
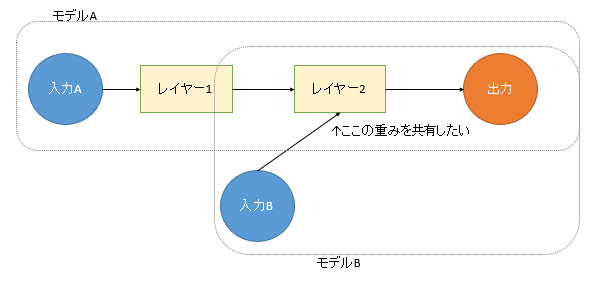
「必要に応じて入力の位置を変える」とはこういうことです。訓練する際は「入力Aから出力まで」を訓練させますが、ある場面では途中の「入力Bから出力まで」を取りたいというような状況です。
別々にモデルを作ってしまうと訓練したレイヤー2の重みが共有されないので、ここは共有レイヤーとして定義する必要があります。
共有レイヤー
重みを共有したい場合は「共有レイヤー」として定義するのが基本です。Kerasの公式にも説明があります。
https://keras.io/ja/getting-started/functional-api-guide/
Functional APIを使います。例えば普段Denseだったら、
from keras.layers import Dense, Input
input = Input((784,))
x = Dense(10)(input)
のように「関数名(引数)(変数)」のように書きますが、最後の(変数)の部分だけ取っ払って、レイヤーのオブジェクトとして保持しておく書き方です。つまり、
dense_layer = Dense(10)
x1 = dense_layer(input_1)
x2 = dense_layer(input_2)
こうです。Keras以外のPythonでも、例えば関数のオブジェクトを変数に代入しておいて、その変数に引数を与えて動的に関数を呼び出すというようなテクニックがあるので、この記法自体は特に珍しいものでもありません。
実装例
重みとか思いっきり無視していますが、例えばこのように実装してみました。
from keras.layers import Lambda, Input
from keras.models import Model
import keras.backend as K
import numpy as np
# 乱数を発生させる関数
def create_rand(inputs):
return K.random_normal(shape=(10,10))
# 10倍させる関数
def multiple_ten(inputs):
return inputs * 10
# 2つのモデルを作る
def create_models():
# 1つは乱数→10倍、もう1つは10倍だけさせる。レイヤーの重み(今はないけど)は共有する
# 共有する10倍のレイヤー
layer10 = Lambda(multiple_ten)
# 1つ目のモデル
input_a = Input((1,)) # ダミーインプット
xa = Lambda(create_rand)(input_a)
xa = layer10(xa)
model_a = Model(input_a, xa)
# 2つ目のモデル
input_b = Input((10,))
xb = layer10(input_b)
model_b = Model(input_b, xb)
return model_a, model_b
if __name__ == "__main__":
ma, mb = create_models()
# まずはモデルAで乱数を発生させて10倍
X_dummy = np.zeros((10,1), dtype=np.float32) # ダミー入力
ya = ma.predict(X_dummy)
print("Model A")
print(ya)
# 次にモデルBでただ10倍させる
Xb = np.arange(100).reshape(10,10).astype(np.float32) # これはダミーではない
yb = mb.predict(Xb)
print("Model B")
print(yb)
1つ目のレイヤーは乱数を発生させるレイヤー、2つ目のレイヤーは入力をただ10倍させるレイヤー。2つ目を共有レイヤーとして定義します。実行結果は次の通り。
Model A
[[-14.171424 -2.784944 -0.97046345 -4.6345415 -9.60215
1.8610847 1.0379182 -5.4268694 -15.079054 -31.015457 ]
[-10.067506 15.017413 -8.313494 5.030054 -3.2046678
7.5128846 -4.1036777 -12.066201 1.1947591 1.7783409 ]
[ -3.242796 0.5635674 10.531197 -1.3924004 -2.7359848
6.5062428 0.72998834 -7.281403 6.821098 0.26847383]
[ 3.928729 -0.22778808 13.042159 -3.9730072 12.684418
11.40539 -12.954694 -3.2590175 -5.90364 -0.8891677 ]
[ 6.5432982 -2.4574468 0.573207 -5.8621364 4.8784103
15.820572 -13.944576 8.554482 9.679798 -3.3461163 ]
[ 0.06409714 -4.345841 -11.098437 9.078588 13.999712
-1.8768744 -8.40677 0.6909147 -12.422537 -13.587 ]
[ 9.191393 -7.7897334 -16.26502 -8.654823 1.434179
12.283398 4.5111756 13.538376 8.84922 8.5673275 ]
[ 1.0559345 -16.302864 -0.8685695 -1.8529015 -3.3979917
-2.737006 10.955934 -5.886425 -12.419347 -2.1857073 ]
[ -9.781853 -2.9850006 2.6867461 -5.804907 11.225485
19.90472 -12.013854 -12.737608 5.637822 11.66047 ]
[ 6.5952387 11.908323 4.9963694 2.6850624 -8.195278
-3.7208378 -1.9654443 7.847238 -0.08818804 -6.2225204 ]]
Model B
[[ 0. 10. 20. 30. 40. 50. 60. 70. 80. 90.]
[100. 110. 120. 130. 140. 150. 160. 170. 180. 190.]
[200. 210. 220. 230. 240. 250. 260. 270. 280. 290.]
[300. 310. 320. 330. 340. 350. 360. 370. 380. 390.]
[400. 410. 420. 430. 440. 450. 460. 470. 480. 490.]
[500. 510. 520. 530. 540. 550. 560. 570. 580. 590.]
[600. 610. 620. 630. 640. 650. 660. 670. 680. 690.]
[700. 710. 720. 730. 740. 750. 760. 770. 780. 790.]
[800. 810. 820. 830. 840. 850. 860. 870. 880. 890.]
[900. 910. 920. 930. 940. 950. 960. 970. 980. 990.]]
モデルAでは入力を無視してただレイヤー内で発生させた乱数を返しているだけです。これがレイヤー2で10倍されて返ってきます。
モデルBでは乱数発生レイヤーはないので、ただ入力が10倍されて返ってきます。ここでの入力は0~99までの数なので、結果は10倍された0~990となっています。
これでよいのではないでしょうか。
ちょっとモデルが大きくなったら共通部分をモデルにしてしまう
共有レイヤーだとモデルが大きいときに困ります。そういうときは、共通の部分を1つのモデルにしてしまえばいいのではないでしょうか。
# 2つのモデルを作る
def create_models():
# 1つは乱数→10倍、もう1つは10倍だけさせる。レイヤーの重み(今はないけど)は共有する
# 共有する10倍のレイヤーのモデル
input_common = Input((10,))
xcommon = Lambda(multiple_ten)(input_common)
model_common = Model(input_common, xcommon)
# 1つ目のモデル
input_a = Input((1,)) # ダミーインプット
xa = Lambda(create_rand)(input_a)
xa = model_common(xa)
model_a = Model(input_a, xa)
# 2つ目のモデル
input_b = Input((10,))
xb = model_common(input_b)
model_b = Model(input_b, xb)
return model_a, model_b
これでも一応動きます。2つ目のモデルでInputが2重になっているように見えますが、Inputのプレースホルダを定義しないとModelが作れないのでこうしています。この例のように同一のモデルを返してやればいいケースでは、2つ目のモデルを作らずに「return model_a, model_common」でもいいですね。
まとめ
以上です。まず重みを共有させるには、レイヤーのオブジェクトを変数にして「共有レイヤー」として定義する。そして入力の位置を変えるには、入力の位置ごとにInputを定義する。モデルが大きくなったらModelでカプセル化する。こんなところでしょうか。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー