
Kerasで評価関数にF1スコアを使う方法


Kerasで訓練中の評価関数(metrics)にF1スコアを使う方法を紹介します。Kerasのmetricsに直接F1スコアの関数を入れると、バッチ間の平均計算により、調和平均であるF1スコアは正しい値が計算されません。そこだけ注意が必要です。
目次
F1スコアをmetricsに入れるときは要注意
詳しくはQiitaのほうで書きましたが、F1スコアをmetricsに入れる場合は要注意です。ここではそれを軽くおさらいします。
バッチ間のTrueNegative(TN), FalseNegative(FN), FalsePositive(FP), TruePositive(TP)を例にします。定義をおさらいすると、
- 精度(Accuracy): (TN+TP)/(TN+FN+FP+TP)
- 適合率(Precision): TP/(TP+FP)
- 再現率(Recall):TP/(TP+FN)
- F1スコア:2×Precision×Recall/(Precision+Recall)
です。今わかりやすいようにバッチサイズを100としますが、各バッチにおいて、
- 1バッチ目:TN=50, FN=10, FP=10, TP=30
- 2バッチ目:TN=90, FN=9, FP=0, TP=1
- 3バッチ目:TN=70, FN=0, FP=0, TP=30
としましょう。バッチ単位で精度とF1スコアを計算すると以下のようになります。
- 1バッチ目:精度0.8、F1スコア0.75
- 2バッチ目:精度0.91、F1スコア0.181818…
- 3バッチ目:精度1、F1スコア1
ちなみに1バッチ目~3バッチ目のサンプル数の合計は、
- 合計:TN=210, FN=19, FP=10, TP=61
- 精度 = 0.9033… F1スコア = 0.807947
これがデータ全体の本来の値です。ところがバッチ間の精度、F1スコアを平均するとどうでしょうか。
- 精度平均=(0.8 + 0.91 + 1) / 3 = 0.90333… (これは正しい)
- F1スコア平均=(0.75 + 0.1818… + 1) / 3 = 0.643939… (これは間違い)
F1スコアの場合は正しい値から16%も低い値が出てきました。つまり、精度はバッチ間の精度を平均してもよいが、F1スコアはバッチ間のF1スコアを(算術)平均してはいけないということです。
Kerasのmetricsでは、どうもこのバッチ間の集計を算術平均(あるいはそれに近い計算)でやっているので、F1スコアの関数をそのままモデルのmetricsに放り込むのはよろしくありません。事実このように明らか違う値が出てくることがあります。
854/854 [==============================] - 2s 2ms/step - loss: 5.7325e-04 - acc:
1.0000 - f1: 0.5160 - val_loss: 0.0065 - val_acc: 0.9982 - val_f1: 0.4728
f1score_train 0.997502
f1score_test 0.93532336
KerasのログがモデルのmetricsにF1スコアの関数を入れた場合、その後のf1score_train/testがmodel.predict()でラベルを推定し、SklearnのF1スコアの関数で計算させた正しい値です。このようにmetricsに放り込むと正しい値から大きな乖離が出ることがあります。
無難な方法:Callback
無難な方法はQiitaの記事で紹介したCallbackを使う方法です。Qiitaで解説したのでコードだけ貼ります。
from sklearn.metrics import f1_score
from keras.callbacks import Callback
class F1Callback(Callback):
def __init__(self, model, X_val, y_val):
self.model = model
self.X_val = X_val
self.y_val = y_val
def on_epoch_end(self, epoch, logs):
pred = self.model.predict(self.X_val)
f1_val = f1_score(self.y_val, np.round(pred))
print("f1_val =", f1_val)
これをmodel.train(…, callbacks=[ここ])に入れます。on_epoch_endでpredictし、それをSklearnの関数に食わせる方法です。これは間違う要素がないので確実です。
どうしてもmetricsの中で計算したい
ただ、Callbackかつジェネレータからデータを読ませている場合は、y_trueの値をバッチ単位ではなく全体で取得する必要があります。データサイズが極端に大きくなるとメモリの制約が出てくるので(まずラベルだけでメモリがあふれるというのは遭遇しづらいと思いますが)、metricsの中で計算したくなることがあります。上手い方法がありました。
TN, FN, FP, TPのバッチ単位での数(比率)をmetricsに入れましょう。なぜ精度はバッチ間で平均を取ってよくて、F1スコアはダメかというと、精度は算術平均でF1スコアは調和平均だからです。言い換えれば、metricsには調和平均ではなく、F1スコアを計算する前の算術平均で求められるパラメーターを入れればよいのです。あとはコールバックでlogから各値を取得してF1スコアを計算すればよいのです。この場合は、正解ラベルを全部メモリに入れる必要はありません。metricsで計算した結果を再利用しているだけなので。
metricsはこう定義します。
def true_positives(y_true, y_pred):
return K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
def possible_positives(y_true, y_pred):
return K.sum(K.round(K.clip(y_true, 0, 1)))
def predicted_positives(y_true, y_pred):
return K.sum(K.round(K.clip(y_pred, 0, 1)))
上からTPのみ返す関数、Recallの計算に使うTP+FNを返す関数、Precisionの計算に使うTP+FPを返す関数です。これはサンプル数単位で返していますが、Kerasのほうで全て母数(全体のサンプル数)で適宜割って返してくれるので、出てくる値はデータの総数を分母とした比率になります。比率で計算しても一般性を損ないません(Precision, Recallの定義の分子分母をサンプル数で割ればいいだけなので)。
検証用コードはこちらです。
出てきたログを元にF1スコアを求めているのがF1Callbackで、先程のコールバックを使う方法がVerifyCallbackです。この方法ではF1Callbackのみ必要で、VerifyCallbackは正しい値が出てきているかの確認用で本来はいらないものです。
「結局Callbackを使っているじゃないか、どこが違うんだ!?」と思うかもしれませんが、先程の方法の大きな違いはmetricsの中で適宜計算された値を再利用してF1スコアを計算している、つまりコールバックの中でpredictをする必要がないということです。これはかなりメモリに優しいです。
結果は以下の通りです。From logと書かれたのがF1Callbackで求めた値、Verifyと書かれたのがVerifyCallbackで求めた値です。
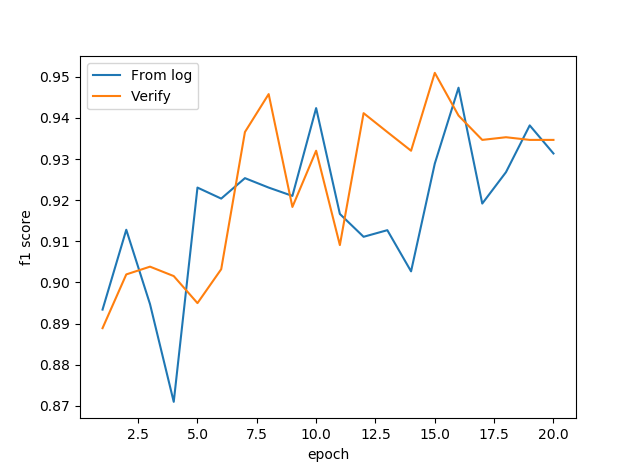
全体として2~3%の誤差はあるものの、概ね良好な感じはします。なぜこのような誤差が生まれるのかというと、おそらくfit_generatorのほうでバッチの端数分のサンプルを切り捨てているからだと思います。他にも集計の小数の処理などがあるかもしれません。
2~3%の誤差を気にする場合は先程のコールバックの方法で求めればよいです。いずれにしても、logから計算するこの方法では、先程のダメな例のログで出ていたような40%や50%の誤差は出ないはずです。
以上です。F1スコアは精度と違って扱い方が少しむずかしいですが、慣れれば精度同じように使いこなせると思いますよ。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー