
論文まとめ:LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control
Posted On 2024-07-25


- タイトル:LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control
- 著者:Jianzhu Guo, Dingyun Zhang, Xiaoqiang Liu, Zhizhou Zhong, Yuan Zhang, Pengfei Wan, Di Zhang
- 論文URL:https://arxiv.org/abs/2407.03168
- コード:https://github.com/KwaiVGI/LivePortrait
- デモ:https://huggingface.co/spaces/KwaiVGI/LivePortrait
目次
要約 By Claude3
- この論文において解決したい課題は、静止画像から生き生きとした動画を生成することです。特に、高い生成品質、計算効率、および細かな制御性を目指しています。
- 先行研究のうち、拡散モデルベースの手法は高品質な生成を実現していますが、計算コストが高く、細かな制御性に課題がありました。一方、暗黙的キーポイントベースの手法は効率的ですが、表情の生成などの表現力に課題がありました。
- 本論文の提案手法は、暗黙的キーポイントベースの手法を拡張し、大規模データセットの活用、ネットワークアーキテクチャの改善、ランドマークガイド付き最適化などにより、生成品質と汎化性能を大幅に向上させています。さらに、ステッチングモジュールと瞳孔・唇のリターゲティングモジュールを導入することで、細かな制御性も実現しています。
- 提案手法の詳細は以下の通りです。まず、顔の特徴点、姿勢、表情変形を推定するネットワークを統合し、大規模データセットを用いて学習します。次に、ステッチングモジュールでは入力画像と駆動画像のキーポイントの差分を推定し、それを用いて入力画像を滑らかに変形させます。瞳孔・唇のリターゲティングモジュールでは、小規模なMLPネットワークを用いて、入力画像の瞳孔や唇の開閉度を任意に制御できます。
- 提案手法の有効性は、自己再現実験と他者再現実験の両方で定量的・定性的に評価されています。自己再現実験では、従来手法と比べて高いPSNR、SSIM、低いLPIPS、L1距離を達成しており、特に瞳孔方向誤差が大幅に改善されています。他者再現実験でも、生成品質と動作精度の両面で優れた結果を示しています。
- 本論文の限界としては、大きな姿勢変化への対応や、駆動動画に大きな肩の動きがある場合の安定性に課題があることが指摘されています。
- 次に読むべき論文としては、拡散モデルを用いた肖像アニメーション手法(FADM、AniPortrait、X-Portrait)や、表情リグモデルを用いた手法(StyleRig、GIF)などが考えられます。

導入
- やりたいこと:静止画をアニメーション化。リアルで表現力豊かな画像化を目指すとともに、高い推論効率と正確な制御性を追求
- Diffusionベースは計算コストが高く制御性が欠ける。本研究では暗黙的なキーポイントに基づくアプローチをとることで、制御性・表現力を両立させる(非拡散ベース)。
- 具体的には
- 学習データを約6900万枚の高品質なポートレート画像にスケールアップ
- 画像と映像の混合学習戦略を導入
- ランドマークガイド付き暗黙キーポイント最適化、いくつかのカスケード損失項を設計
- 「暗黙のキーポイント」手法が強いらしい
- ステッチング制御などの制御性を高めるために、小さなMLPを利用。極小計算量のステッチングモジュールと2つのリターゲティングモジュールを追加
- 貢献
- 生成品質と汎化能力を大幅に向上させる、暗黙のキーポイントに基づくビデオ駆動型ポートレートアニメーションフレームワークの開発、
- ステッチングモジュールと2つのリターゲティングモジュールの設計
- 結果:RTX 4090上で12.8msのポートレートアニメーションの生成が可能
関連研究

- 非拡散ベース:
- 速い
- 制御性(Stiching、Eye retargeting、Lip retargeting)が弱い。汎化性も弱め
- 拡散ベース
- 遅い
- 汎化性能が高い。しかし、制御性で課題がある
- 非拡散ベースで使われている手法:暗黙的キーポイントベース
- 動きの表現を何らかの陰関数で表現し、オプティカルフローでターゲット画像に転移
- FOMM:各キーポイントの近傍で1次のテイラー展開し、局所のアフィン変換でキーポイントの動きを近似
- MRAA:PCAで関節運動を表現
- Face vid2vid:暗黙的キーポイントを3Dに拡張
- IWA:クロスモーダルなAttentionでワープをネットワーク上で表現
- DaGAN:深度マップの活動
- MCNet:同一の駆動運動によって引き起こされる曖昧な生成に取り組むため、補助ネットワークを設計
- 3DMMブレンドシェイプのような、あらかじめ定義された動き表現を採用している研究もある
- 動きの表現を何らかの陰関数で表現し、オプティカルフローでターゲット画像に転移
- 拡散モデルベース
- FADM:暗黙的キーポイントで粗いアニメーションを作り、拡散モデルで3DMMを教師としてリファイン
- FaceAdapter:同一性保持を強化するためにIDアダプタを使用し、キーポイントとマスクをネットワークで生成
- Animaticなど:Attentionで頑張る
手法
ベースライン:Face vid2vid
ソース(s)とターゲット(d)の3Dのキーポイントの関係。ワープの場(各点ごとの移動の方向。風向風速の可視化を想像するとわかりやすい)をニューラルネットで生成する。
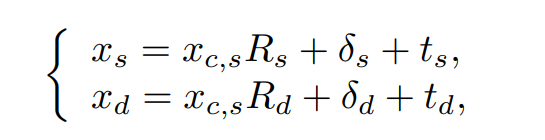
- x:3D正準キーポイント(K×3の行列)
- R:ポーズ(3×3の回転行列)
- t:並進(3次元のベクトル、アフィン変換と同じ)
- δ:細かなブレ(K×3の行列)
Face vid2vidの論文の図がわかりやすい。CVPR 2021のNVIDIAの論文
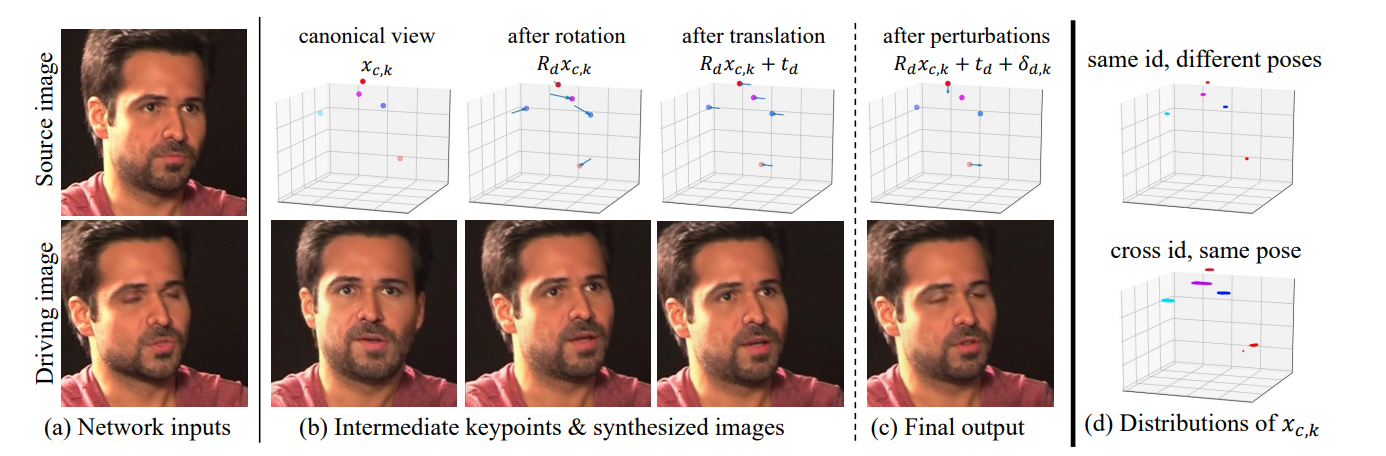
Face vid2vidとの差分
- 学習データのキュレーション
- 画像と動画の混合学習戦略
- ニューラルネットワークのアーキテクチャ
- スケーラブルな動き変換
- ランドマークガイドによる暗黙的キーポイントの最適化
- カスケード損失
データのキュレーション
- 既存の公開ビデオデータセットVoxceleb、MEAD、RAVDESS、スタイル付き画像データセッAAHQ
- 4K解像度のポートレート動画の大規模なコーパスの収集
- 200時間のトーキング・ヘッド動画
- 顔認証を使って各クリップに1人しか含まれていないことを確認
- KVQを使って低品質なデータを削除
画像と動画の混合学習戦略
- リアルな肖像画のみ:人間の肖像画では良好だが、アニメなどのスタイルの肖像画では汎化性が低い
- スタイルされたポートレート動画は少ない
- 一方で、スタイルされた肖像画はかなり多く存在する
この論文では、画像と動画のモダリティを両方が学習できるという観点よりも、データセットの過不足に対し、ドメインを汎化的に学習できるという観点で混合学習戦略をとっている
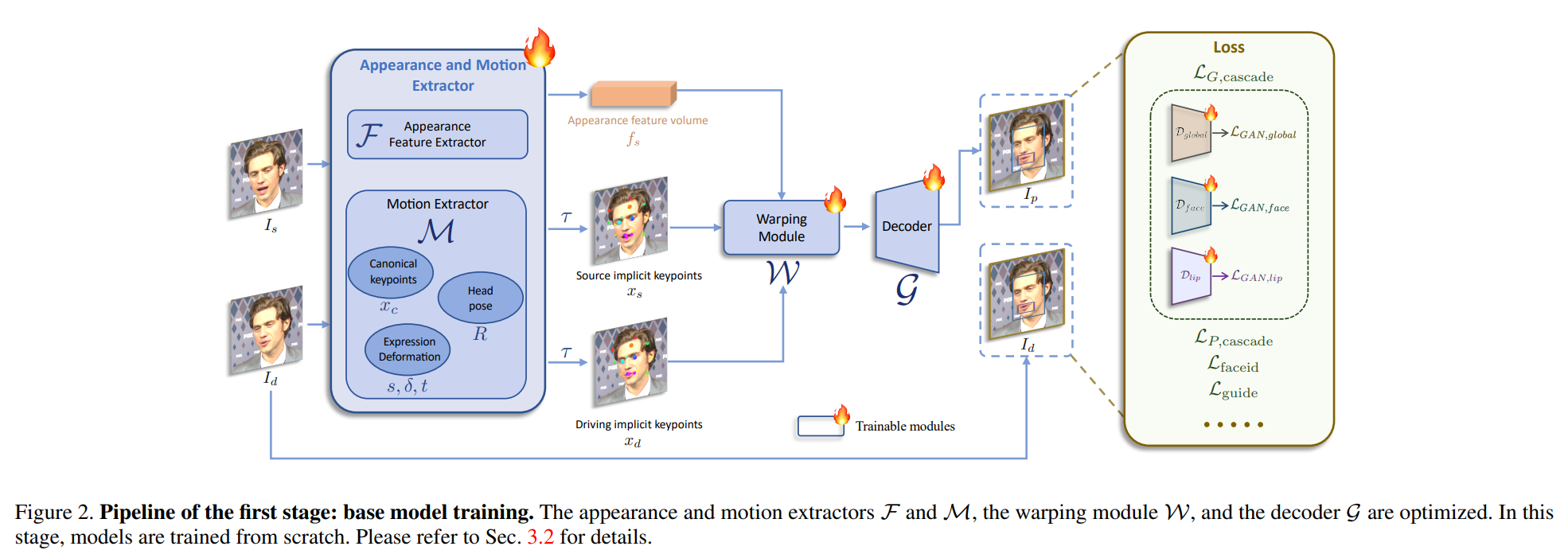
ニューラルネットワークのアーキテクチャ
- ConvNeXt-V2-TinyをバックボーンにいろんなHeadをつける
- SPADEデコーダーをGeneratorとする
- Gの最終層にPixelShuffleを導入
→全般的に使っているネットワーク技術が、数年前のものでこれで結果が出るのがすごい
スケーラブルな動き変換
Face vid2vidはスケール項(拡大・縮小)を無視してる。追加しないと学習の難易度が上がる
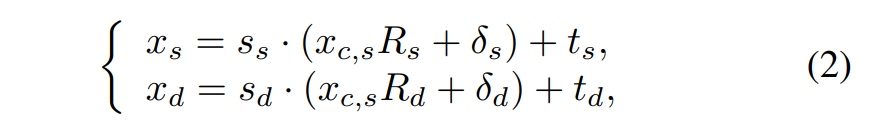
ランドマークガイド付き暗黙的キーポイント最適化
- Face vid2vidはウィンクや眼球運動を鮮明に動かす機能が欠けている
- 微妙な表情を学習することが困難
暗黙点の学習を最適化するためキーポイントを、2次元のランドマークに対してガイダンス損失を追加。WingLossという2017年の研究で、もともとFacial Landmark用に開発された損失関数。WingLossの研究より
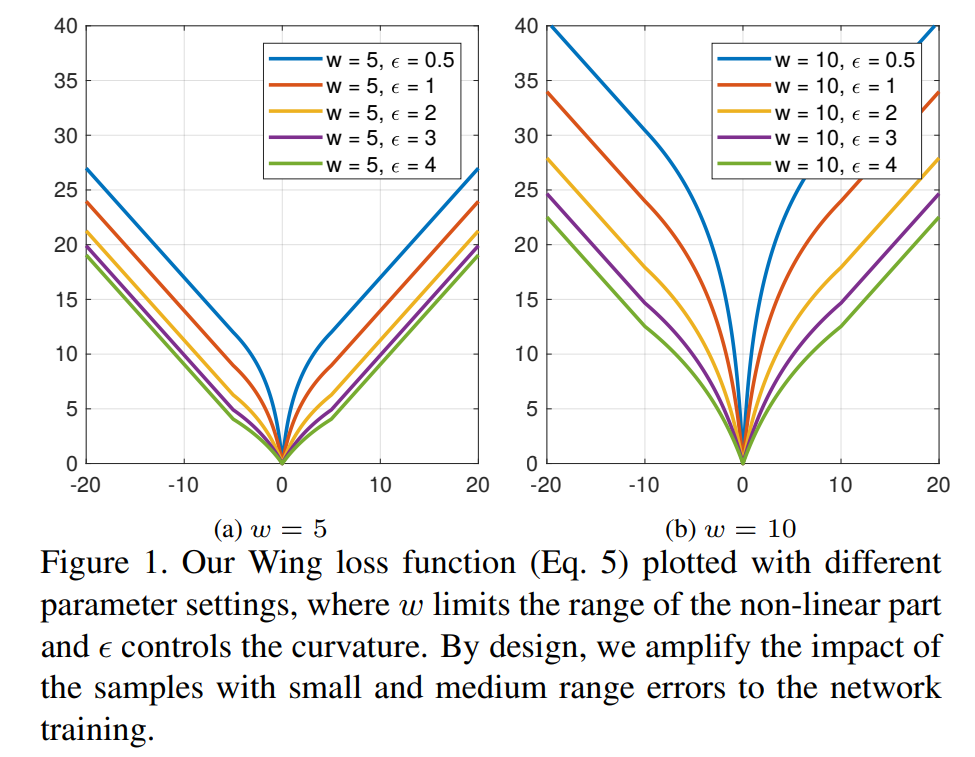
全体の損失関数はいろいろ盛り込んだGAN

ステージII:ステッチングとリターゲティング
- コンパクトな暗黙なキーポイント→一種の暗黙のブレンドシェイプと考えられる
- 組み合わせが必要なように見えるが、小さなMLPネットワークだけでブレンドシェイプを学習できることがわかった
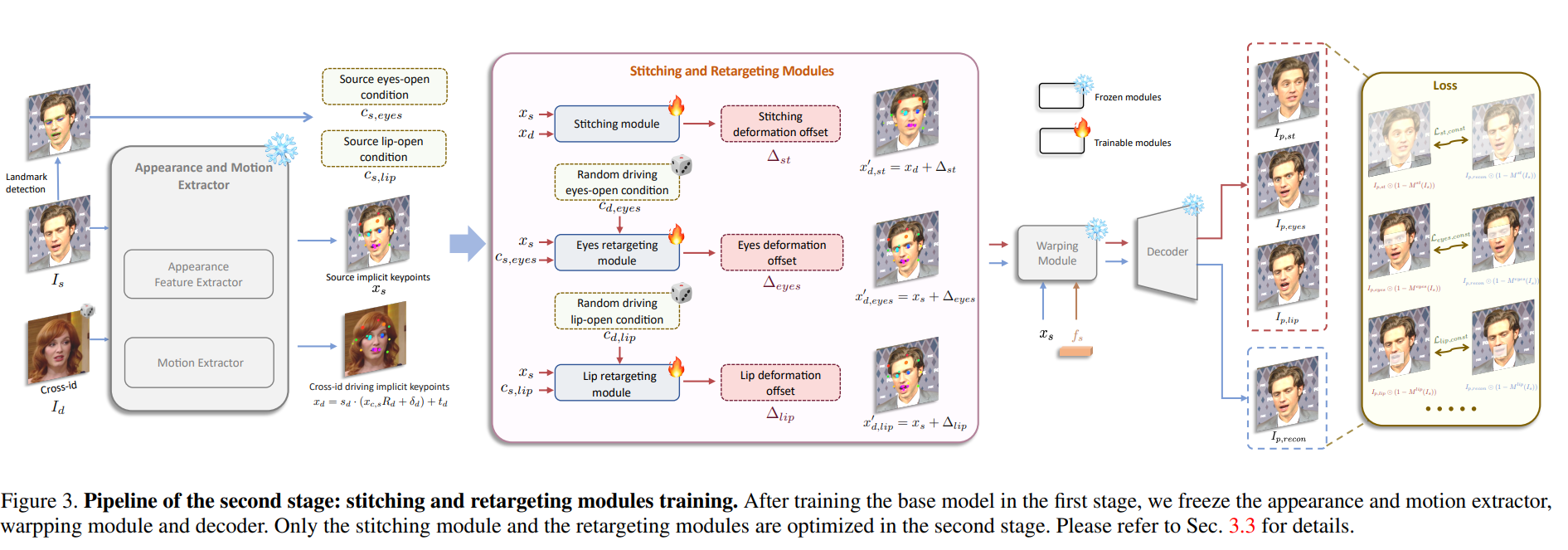
- ステッチングモジュール
- 非肩領域のみに着目した、画素値に対するマスク付きのL1ロス
- 目と唇のリターゲティングモジュール
- 開眼とリップシンクに特化した損失関数を設計する
- Δeyes:開眼したかどうか
- Δlip:口が空いたかどうか

推論時
- 入力画像:正準キーポイントを抽出
- 入力動画:各フレームの動き(s, δ, t, R)を抽出
→その上で結構複雑な推論手順を行っている
結果
評価指標
- 画像生成の定番指標:
- PSNRやSSIM、L1:ピクセル単位の違いを見る原始的な指標
- LPIPSやFID:特徴量ベースの類似度
- 顔特有の評価指標:
- 表情についての平均距離(AED)
- 平均姿勢距離
- 眼球方向の平均角度誤差(MAE)
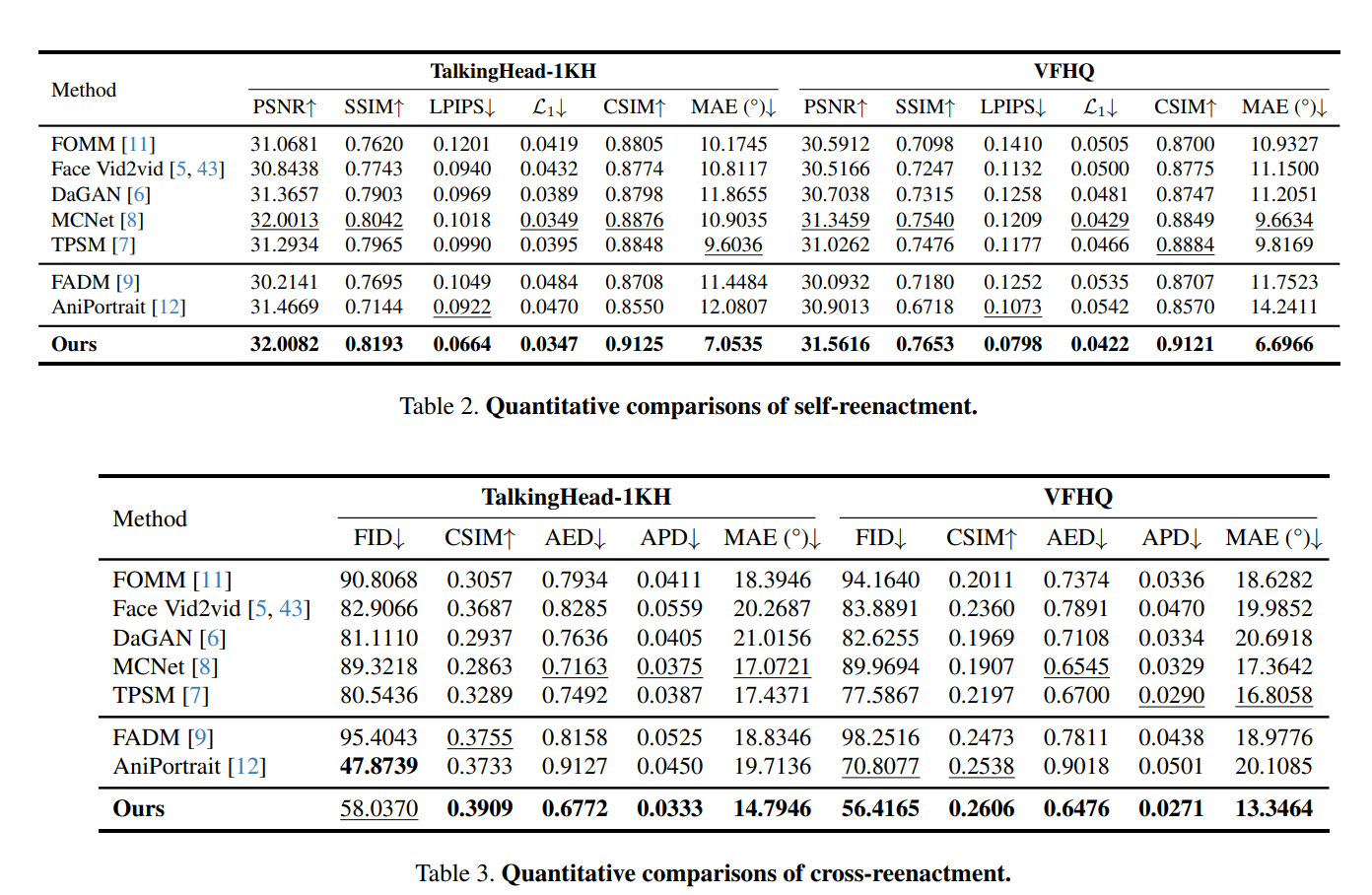
拡散ベースとの比較
- Diffusionベース(AniPortrait)は特有の時間方向の非一貫性がある
- 背景が乱れる
- 手が混入する

リターゲッティング
- 唇のリターゲッティング:この変数を抜いて学習すると唇の動きを学習できない
- 目と唇のリターゲッティング:瞬きと唇を独立して操作可能

限界
我々の現在のモデルは、大きなポーズバリエーションを含むクロスリアクションシナリオで良好な性能を発揮するのに苦労している
所感
- この手の論文初めて読んだが、今は場の学習が主流になっており、2次元なのに3次元復元と考え方は近い部分はある
- 顔特有の評価指標は、表情や姿勢、眼球の方向について差分をとるらしい
- GANベースだけではなく、SPADEやPixelShuffle、WingLossなど古くて枯れた技術を多様しており、これが2024年に出てきて大盛りあがりしているのがかなり意外だった
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー