
論文まとめ:Mélange: Cost Efficient Large Language Model Serving by Exploiting GPU Heterogeneity


- タイトル:Mélange: Cost Efficient Large Language Model Serving by Exploiting GPU Heterogeneity
- 論文URL:https://arxiv.org/abs/2404.14527v4
- GitHub:https://github.com/tyler-griggs/melange-release
Mélangeはリクエストサイズやレイテンシー要件を考慮し、複数種類のGPUを自動割り当てすることで最大77%のコスト削減を達成する。また、99.5%以上のSLO達成率を維持しながら、会話型から文書ベースまで多様なワークロードに柔軟に対応できる。
目次
要約 By Gemini 1.5
この論文は、大規模言語モデル(LLM)の推論サービングにおけるGPUコスト効率を最大化するための手法、Mélangeを提案しています。
・この論文において解決したい課題は何?
LLMの推論サービングはGPUインスタンスが高コストであるため、費用対効果の高いGPUの種類を選択する効率的な方法がない。
・先行研究だとどういう点が課題だった?
先行研究はLLMサービングの高コスト問題に対し、推論エンジンの改善に焦点を当てており、特定のLLMサービスにとって最も費用対効果の高いGPUの種類の選択はあまり考慮されていなかった。また、LLM特有の特性(リクエストサイズ、リクエストレート、SLO)がコスト効率に与える影響を詳細に分析していなかった。
・先行研究と比較したとき、提案手法の独自性や貢献は何?
LLMサービスの特性(リクエストサイズ、リクエストレート、SLO)がGPUコスト効率に強く影響することに着目し、これらの特性とGPUの異質性を考慮したコスト最小化のためのGPU割り当てフレームワークMélangeを提案している。Mélangeは、複数のGPUタイプを混在させて利用する初めてのGPU割り当てフレームワークである。
・提案手法の手法を初心者でもわかるように詳細に説明して
- オフラインプロファイリング: まず、利用可能な各GPUタイプについて、様々なリクエストサイズとレートで性能を測定します。これにより、各GPUが特定のSLOを満たしつつ、どの程度の最大スループットを達成できるかを把握します。
- ワークロード分割: LLMサービスのワークロード(リクエストサイズとレートの分布)を小さな「スライス」に分割します。これにより、GPUへの割り当てをより細かく調整できます。
- ビンパッキング問題として定式化: GPUを「ビン」、ワークロードスライスを「アイテム」と見なし、コストを最小化しつつ、全てのアイテムをビンに詰め込む問題として定式化します。SLO制約も考慮されます。
- 整数線形計画法 (ILP) で解く: 定式化されたビンパッキング問題をILPソルバーを用いて解き、最小コストのGPU割り当てを求めます。
・提案手法の有効性をどのように定量・定性評価した?
NVIDIA L4、A10G、A100、H100の4種類のGPUを用いて、会話型(Chatbot Arenaデータセット)、文書ベース(PubMedデータセット)、および混合ワークロードでMélangeを評価しました。結果として、単一のGPUタイプのみを使用する場合と比較して、Mélangeは会話型設定で最大77%、文書ベース設定で最大33%、混合設定で最大51%のコスト削減を達成しました。また、TPOT SLOの達成率は99.5%以上でした。
・この論文における限界は?
Mélangeは固定のワークロード分布とリクエストレートを想定しており、GPUの可用性や動的なリクエストレート、サイズ分布への自動スケーリングには対応していません。
・次に読むべき論文は?
論文中で参考文献として挙げられている、LLM推論の最適化やクラウド資源を用いた機械学習に関する論文、特に[19] vLLM, [58] Distserveなどが関連性の高い研究として挙げられます。
コードへのリンクは論文中に明示的に示されていません。
はじめに
- Llama2 70BをBF16でホストするには、A100-80Gが2台で、オンデマンドだと月額5200ドル以上かかる
- LLMサービスのコスト要因
- リクエストサイズ。LLMのリクエストサイズは入出力のトークン長で決定。リクエストサイズが小さい場合は、ローエンドGPUはハイエンドGPUよりも、コスパが良い(T/ドルが大きい)
- リクエストレート:リクエストがまばらだと、ローエンドのGPUにシフトすることでコストを削減。ミックスすることできめ細やかなスケーリングが可能
- レイテンシーSLO:目標のSLOが厳しい場合はハイエンドGPU、厳しくない場合はローエンドGPUでコスト削減できる。
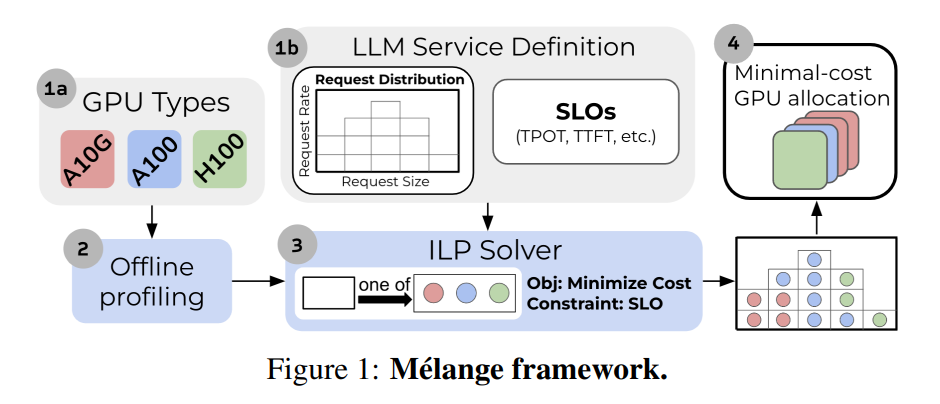
コスト効率指標
1ドルあたりのトークン数がKPI。これを実験的に計測する。
入出力のトークン数を変化させた場合(横軸)、ローエンドのGPU(A10G)基準で、ハイエンドのGPU(A100)はリクエストあたりのトークン数が多い場合にアドバンテージ。逆にトークン数が少ない場合はローエンドのほうがアドバンテージ
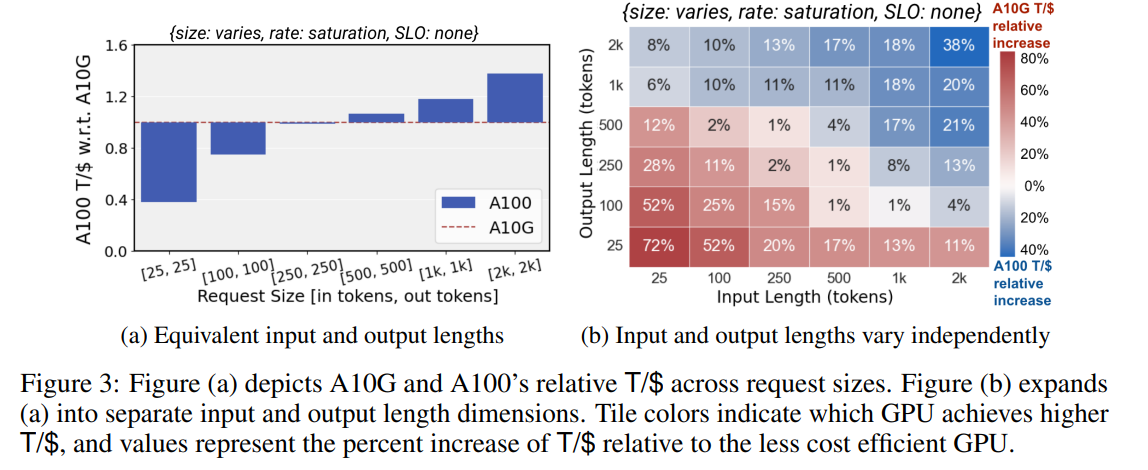
左:最良のGPU÷2番目に良いGPU、右:最良のGPU÷最悪のGPU
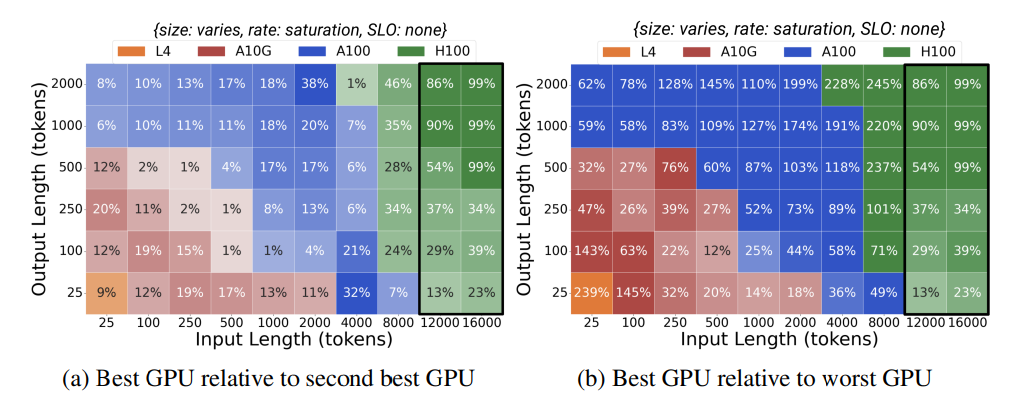
SLO(Service Level Objective)の指標
Time Per Output Token(TPOT)をSLOの指標とする。指定したTPOTを満たすという条件でGPUを選択
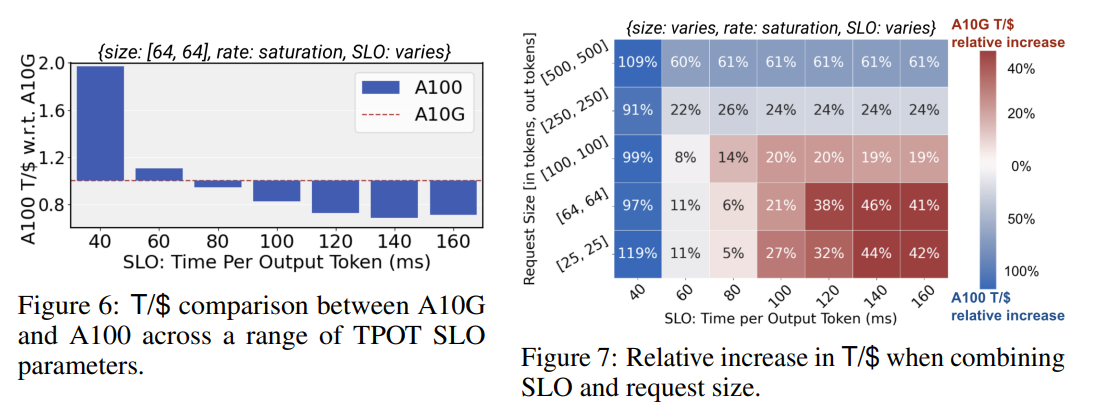
SLOを厳しく取るほど、ハイエンドなGPUが要求される
リクエストレート
アイドル時間が長い(リクエスト数が少ない)場合は、ローエンドのGPUのほうが良い
コスト効率の良いGPUの選択
GPUの割当タスクをビンパッキング問題として定式化し、最小のコストを計算。ILPソルバーを解く
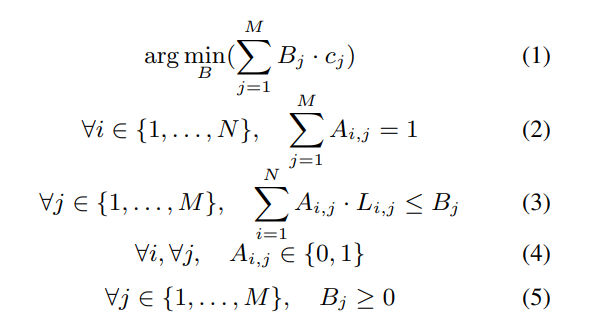
実験
- 普通に一種のオンデマンドインスタンスを使う場合と、Melange(ILPによる最適化でのミックスGPU)の場合でのコスト比較を行う。
- Chatbot Arena、PubMedデータデータセットをミックスして計測
- 2種類のTPOT SLOを設定してシミュレート。これは実用的なUXを満たすことを保証するため
- 40ms : 迅速な応答が必要なサービス
- 120ms:そこまで迅速な応答は必要ないが、人間の平均読書速度を上回る
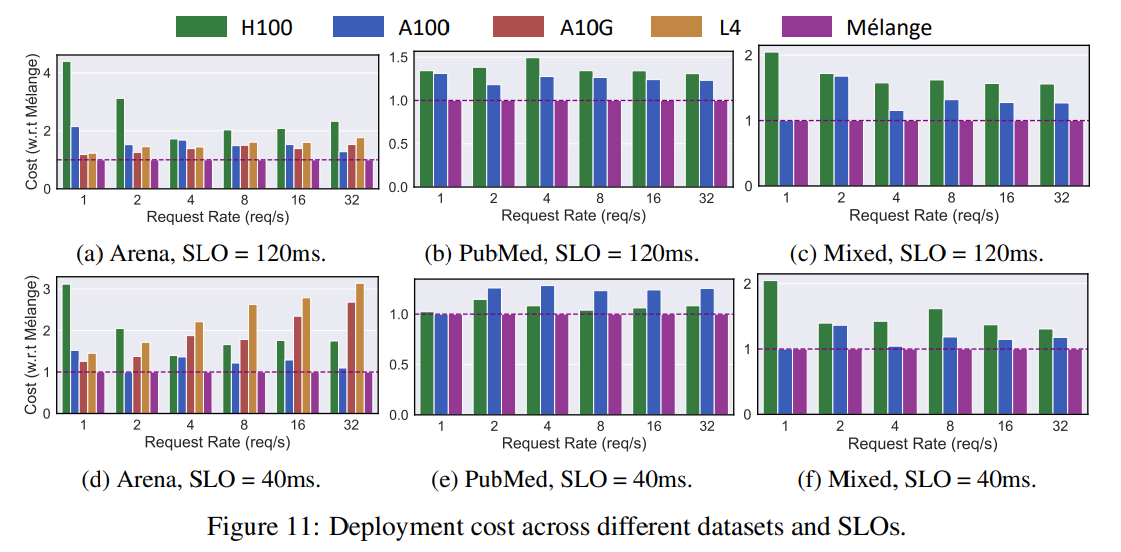
→最適化することで、コストが最大77%減った
所感
- TPOTを使ってUXを定量化したのが面白い。最初のトークン数に対する「どのGPUが最良ですが」は結構面白い
- 一個割と大きなズルをしてるのでは疑惑があって、出力トークン数は既知ではないのに、あたかも既知のように最適化のパラメーターとして使っている点。単なるデータ分析としてなら既知でも構わないが、推論システムの最適化パラメーターに組み込むのは厳しいのではないか。
- 着想は結構面白いがどこか物足りない印象の論文。アカデミックの人なせいかクラウドに対する理解が浅い。検証も単品のGPUでやっており、キューなど考えていなく総合的なシステムのレイテンシーのテストではない。
- そもそも複数GPUインスタンスのクラスタを組める段階で、結構リクエストがきているから、最初の疑問提起であった「70BモデルをホストするのにミニマムでA100-80Gが2枚必要でめっちゃ高い」に対するダイレクトな解ではなく、解こうとしている問題と手法がずれてしまっているのではないか
- Under reviewのままで、1年経ってもどっかに通ってる感じではない
- 割当GPUを最適化するのではなく、そもそも70Bモデルを使わないがこの問題に対する解なのかもしれない
- ここを実験的にやっても当たり前な印象が強いので、もっと理論的なアプローチのほうが有益そう
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー