
Mini-GPT4をDockerで動かしてバッチ処理する


Mini-GPT4というマルチモーダルLLMをDockerを使ってバッチ処理をしてみました。係数を部分的にDockerイメージに組み込んだり、使用するLLMを切り替えられるようにちょっと工夫をしてみました。
目次
はじめに
Mini-GPT4というマルチモーダルなLLMがあります。これは対話型に実行するデモが公開されているのですが、実際はバッチ処理したいことが多いです。これをDockerを使って行っていきます
https://github.com/Vision-CAIR/MiniGPT-4
ディレクトリ構成・リポジトリ
以下のようなディレクトリ構成にします。
+ data
+ input
+ output
+ docker
+ app
- batch.py
+ build_src
- convert_yaml.py
- init_image_encoders.py
- dockder-compose.yaml
- Dockerfile
- download_weights.py
リポジトリは以下にあります。
https://github.com/koshian2/Mini-GPT4-Batch/
dataフォルダ
これはバッチ処理の推論で読み書きされるデータです。Dockerイメージにマウントさせます。
- inputフォルダ
- 画像ファイルを入れます
- outputフォルダ
- 各画像に対し、共通のプロンプトで出力されたテキストファイルが生成されます
dockerフォルダ
Dockerイメージに関するフォルダです。
- appフォルダ
- バッチ処理のメインプログラムです。中にはbatch.pyが入っています
- build_srcフォルダ
- Dockerイメージのビルドに使われるフォルダです。convert_yaml.pyはDockerイメージ内のyamlのコンバートに、init_image_encoders.pyはLLM以外のモデルのダウンロードに使われます
- Mini-GPT4は、Image EncoderとQ-Former、LLMの3つのモデルから構成されます。Image EncoderとQ-FormerはDockerイメージに埋め込み、LLMは外部からマウントさせます。これはLLMの容量が大きすぎてDockerイメージの取り回しが大変になるのを防ぐためです。
- AWSのようなクラウドで実行する場合は、LLMの部分だけS3に外部保存するなどすればよいでしょう
- docker-compose.yaml / Dockerfile
- Dockerイメージを作るためのいつものファイル
- download_weights.py
- ローカル環境にLLMの係数をダウンロードするためのプログラムです。ダウンロードされたLLMの係数はDockerのマウントを使って、Dockerイメージから呼ばれます。
- Mini-GPT4はVicuna 7B/13B, LLaMA-2 7Bの複数のLLMに対応しているのですが、LLMの切り替えはDockerのマウントオプションで切り替えることを想定しています。
注意点
カレントディレクトリを、このリポジトリ内のdockerフォルダとします。DockerはWSL2で動かしています(docker-compose.yamlのローカルパスの指定が若干他と変わるのでご注意ください)
また、LLMの係数の保存は「G:/LLMs」フォルダに保存するものとします。環境によって適宜読み替えてください
使い方
Dockerイメージのビルド
- (WSL上の場合)dockerフォルダに移動します
- Dockerイメージをビルドします
docker-compose build
LLMのダウンロード
LLMの係数だけは別途ローカルからダウンロードします。「download_weights.py」を開きます。以下のコードになっていますが、「local_root_dir」を書き換えると保存先を変えられます
from huggingface_hub import snapshot_download
def main():
local_root_dir = "G://LLMs/"
snapshot_download(repo_id="Vision-CAIR/vicuna", local_dir=local_root_dir+"Vision-CAIR/vicuna", local_dir_use_symlinks=False)
snapshot_download(repo_id="Vision-CAIR/vicuna-7b", local_dir=local_root_dir+"Vision-CAIR/vicuna-7b", local_dir_use_symlinks=False)
# snapshot_download(repo_id="meta-llama/Llama-2-7b-chat", local_dir=local_root_dir+"meta-llama/Llama-2-7b-chat", local_dir_use_symlinks=False)
if __name__ == "__main__":
main()
LLaMA-2だけHuggingfaceのリポジトリへの認証が必要なので、認証が終わっていないとエラーになると思います。ここではVicuna-7Bで動かすことを想定します。
バッチ処理の実行
- 以下のコマンドを実行すると、バッチ処理が走ります
docker-compose up
これはVicuna-7Bを読み込む場合です。LLMの切り替えや設定値の切り替えはdocker-compose.yamlをいじります。
version: '1'
services:
minigpt4:
build: .
image: minigpt4
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]
volumes:
- /mnt/g/LLMs/Vision-CAIR/vicuna-7b:/llm_weights/vicuna
- ./app:/MiniGPT-4/app
- ../data:/MiniGPT-4/data
tty: true
environment:
- EVAL_CONFIG=eval_configs/minigpt4_vicuna_7b_eval.yaml
ports:
- 30485:7860
- volumesはマウントするディレクトリです。
- 1番目はLLMのモデルです。Vicuna-13Bにする場合は、以下のように変えます
- /mnt/g/LLMs/Vision-CAIR/vicuna:/llm_weights/vicuna
- LLaMA-2も同様です。詳しくはbuild_src/convert_yaml.pyを読んでください
- 2番目はバッチ処理で実行するコードのマウントディレクトリです。ローカル環境からコードを編集できるようにマウントさせています
- 3番目はバッチ処理で推論するためのデータのディレクトリです
- 1番目はLLMのモデルです。Vicuna-13Bにする場合は、以下のように変えます
- environmentは設定値の環境変数です
- 今のところ推論の際のconfigファイルの指定のみEVAL_CONFIGで定義しています。Vicuna-13Bに変える場合は、以下のように変えます
- eval_configs/minigpt4_vicuna_13b_eval.yaml
- 今のところ推論の際のconfigファイルの指定のみEVAL_CONFIGで定義しています。Vicuna-13Bに変える場合は、以下のように変えます
プロンプトを変えたい場合
今は共通して「Discribe this image」というプロンプトですが、app/batch.pyのprompt変数をいじってください。
(ここを環境変数で管理すればよかったね…)
結果
バッチ処理
以下のようなInputディレクトリに対し、
以下のように返ってきました。
設定ファイルはMiniGPT4のデフォルトを使いました。量子化ビットやトークン数、ビームサーチのパラメーターを変えればもっとパフォーマンス・チューニングできると思います。Vicuna-7B、デフォルトの設定でGPU使用量は11~12GBぐらいでした(量子化効いている)
単体サンプル
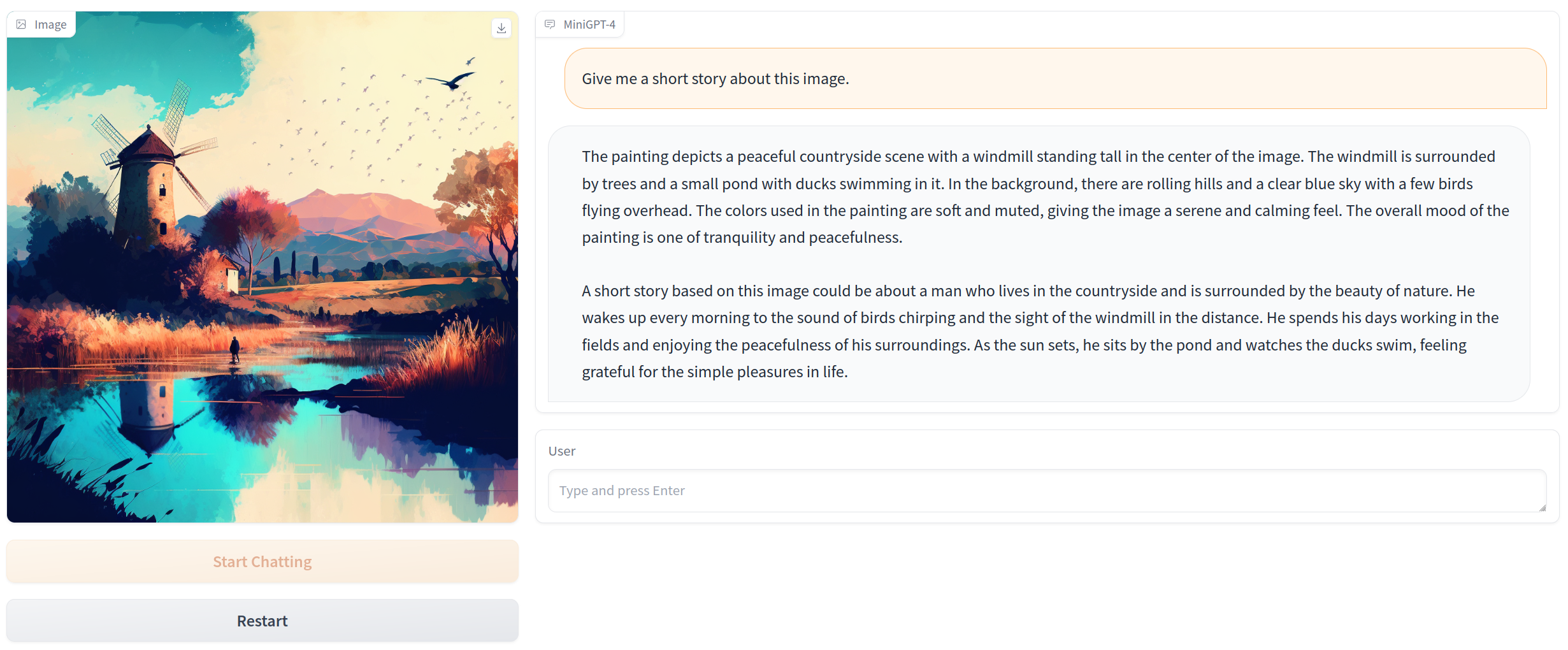
このシュールな画像に対し「Discribe this image」とすると、

The image shows a person wearing a Star Wars stormtrooper outfit standing on a street corner, holding a sandwich in one hand and a lightsaber in the other. The person is standing on a street corner with buildings in the background. The image is taken from a low angle, looking up at the person from the street. The person is wearing a black and white stormtrooper suit with a helmet, a white belt, and a long white cape. The person is holding a sandwich in one hand and a lightsaber in the other. The lightsaber has a blue blade and a silver hilt. The image is taken from a low angle, looking up at the person from the street. The person is standing on a street corner with buildings in the background. The person is wearing a black and white stormtrooper suit with a helmet, a white belt, and a long white cape. The person is holding a sandwich in one hand and a lightsaber in the other. The lightsaber has a blue blade and a silver hilt.
という結果に。ストームトルーパーが何なのかはわかってるらしい。
その他発見
- Mini-GPT4はImage EncoderにEVAのViT-Gを使っているらしい。画像側は結構いいモデル使っていた(でかいけど)
- 論文リポジトリあるあるだけど、一個一個のモデルがでかいため普段よりも取り回しが大変。transformersみたいなお手軽ライブラリに統合されるだけでもかなり使い勝手良くなりそう(StableDiffusionのdiffusers統合がそうだったように)
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー