
論文まとめ:MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation


- タイトル:MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation
- 著者:Omer Bar-Tal, Lior Yariv, Yaron Lipman, Tali Dekel(ワイツマン科学研究所)
- 論文URL:https://arxiv.org/abs/2302.08113
- プロジェクトページ:https://multidiffusion.github.io/
- HuggingFace Demo:https://huggingface.co/spaces/weizmannscience/MultiDiffusion
- Diffuserドキュメント:https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/panorama
目次
ざっくりいうと
- 訓練済み拡散モデルから複数の画像を生成し、追加訓練なしでシームレスなパノラマ画像を生成するための研究
- Denoising時の潜在特徴量をハックし、パノラマ画像の生成だけでなく領域指定した画像生成にも応用可能
- 領域指定した画像生成では、Stable DiffusionのInpaintingより高いIoUを実現

概要
- 現在の拡散モデルに対する制御可能性
- 1から訓練するかファインチューニング:計算コスト重すぎ
- 事前学習されたモデルの再利用:←この研究のアプローチ
- 複数クロップ推論回してそれをつなぎ合わせたい
「各クロップは異なるノイズ除去の方向に引っ張られるかもしれないが、我々のフレームワークは統一されたノイズ除去ステップをもたらし、それ故、高品質でシームレスな画像を生成することに注意されたい」←これがやりたいこと
手法
お気持ち
訓練済みの拡散モデルを使って、複数のパッチ単位のサンプリングから、共通の1枚のパノラマ画像を生成するようなモデルΨを考えたい。ここで追加の訓練はしない。
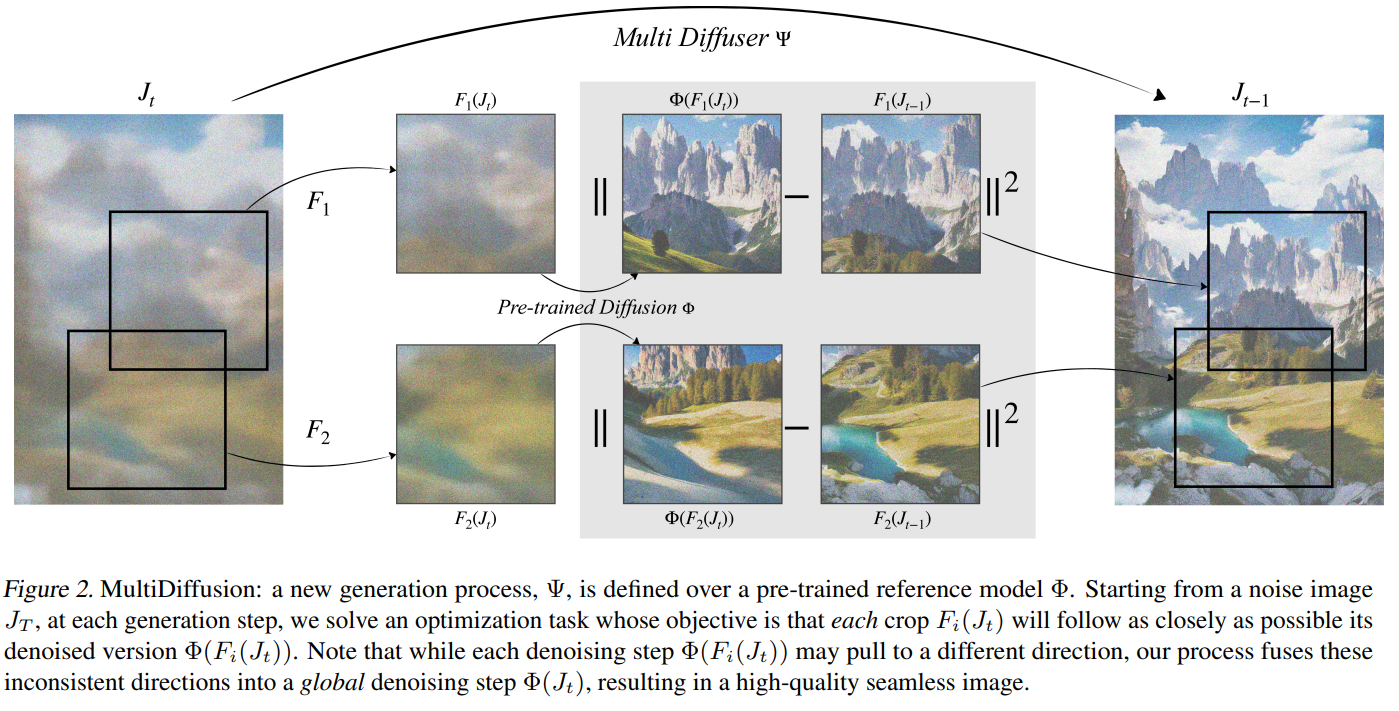
- 各クロップから独立にDiffusionをとると、ノイズ→出力画像のマッピングが違う
- 各ステップにおけるマッピングは、アプリケーションベースであってパッチ間(1, …, n)で共通であってほしい

各ステップにおける特徴量のマッピングについて、最小二乗法のアプローチで最適化できる。
パノラマ生成
パノラマ生成の例は、最適化の結果を閉じた数式で表現できる。パッチ単位のlatentを重み付き平均取っただけ。

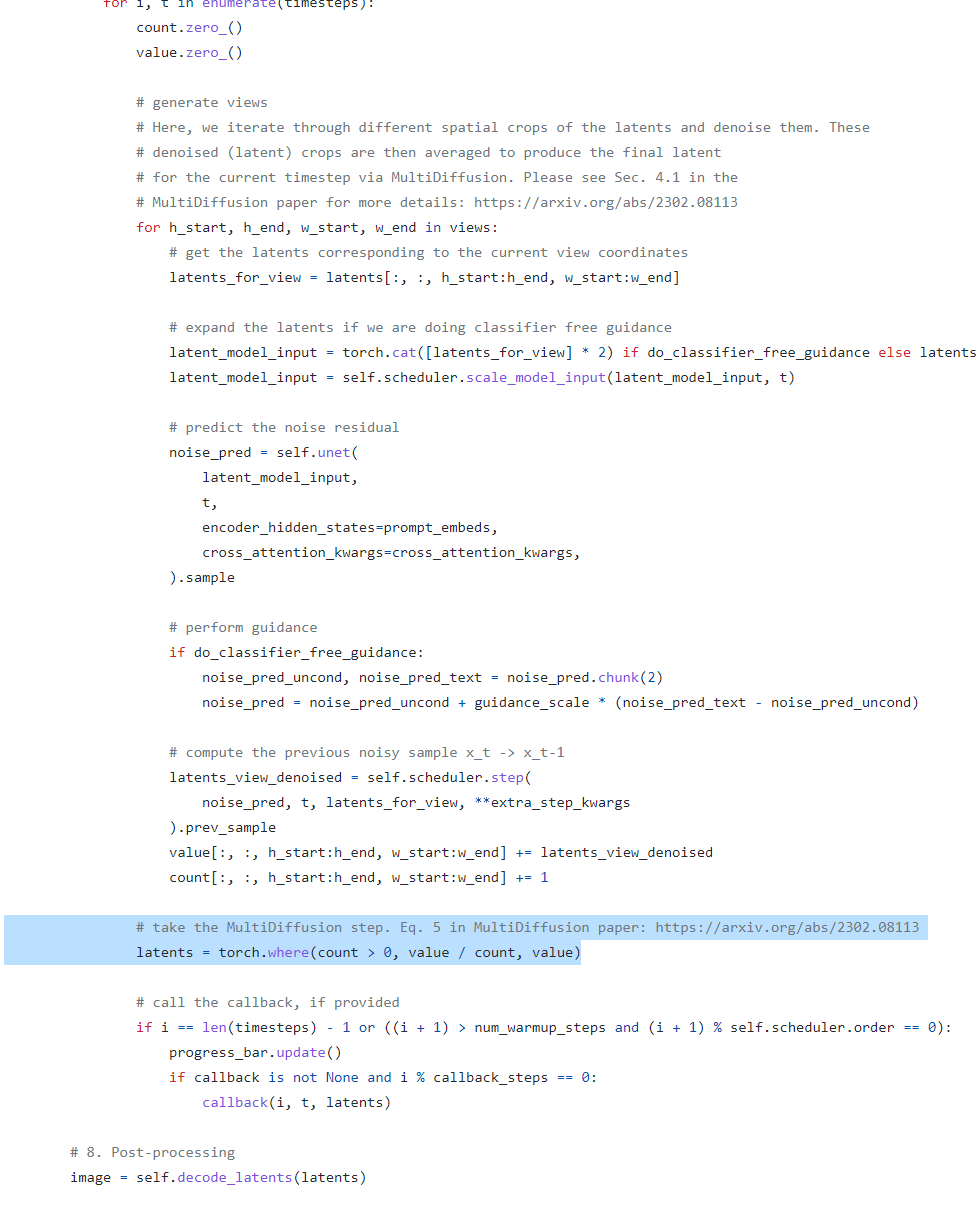
Multi Diffuserの部分はコードを読むとわかる。Denoiseされたlatentを、空間方向に重み付き平均とってるだけ(ハイライトされた部分以外は普通のSDと同じ)
結果は公式サイトより。

領域を指定した生成
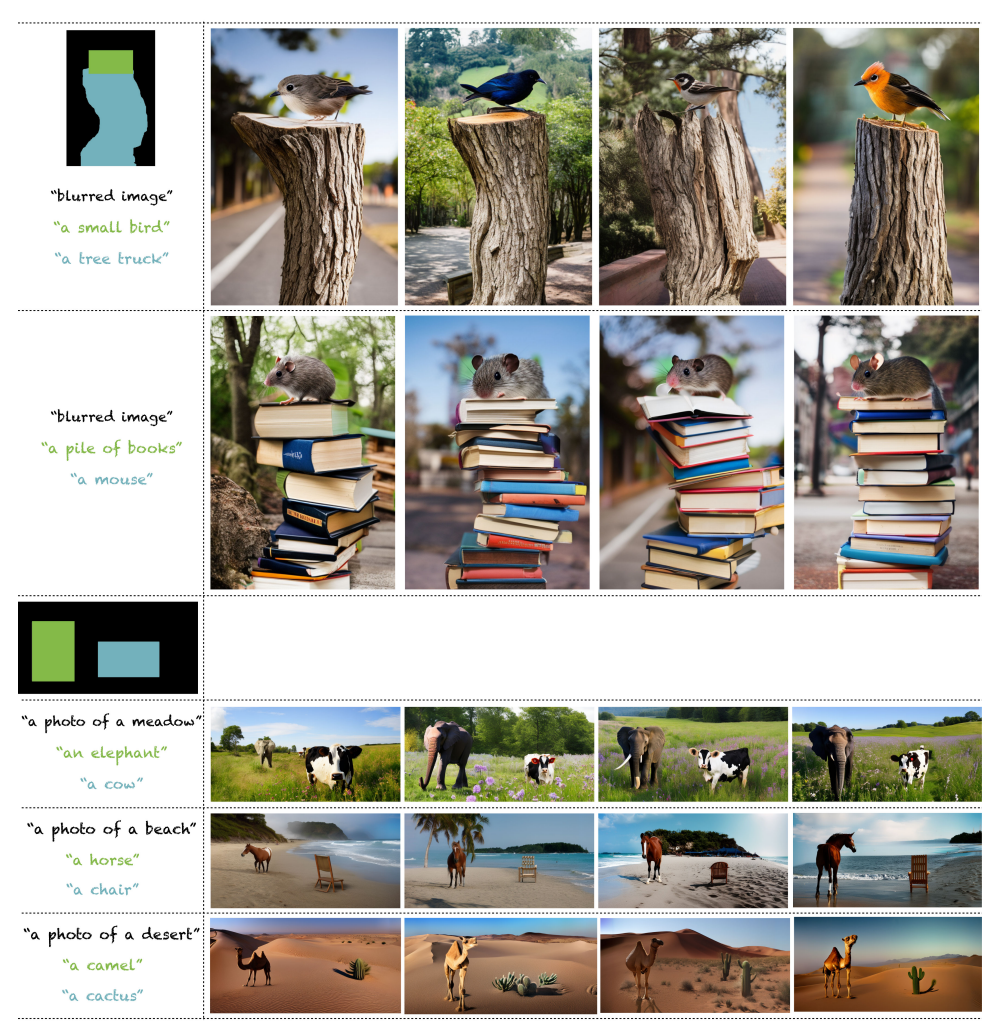
パノラマ生成の場合は、latentの各タイムステップの平均だったが、これとは別に空間方向のマスキングも可能。これを論文では「ブートストラップ」と呼んでいる。ブートストラップを活用することで、領域を指定した生成がより高性能になる。

定量評価
パノラマ生成では、Stable DiffusionのInpainting(SI)と比べて大幅にFIDが下がり、自然な画像となっている。

CLIP-Aestheticsは、Laion-5Bデータセットで特に審美性の優れた画像のサブセットがあるのでそれ関係(何らかの審美性スコアを吐いてくれるモデルがあるのかも?)
領域を指定した生成では、生成画像をMask2Formerというセグメンテーションモデルにかけ、元のマスクとのIoUを比較

ブートストラップがあることで、IoUが大きく上昇
応用
マスクは厳密なセグメンテーションマスクでなくても、Bounding Boxのようなラフなマスクでも対応している。

ただ、Bounding Boxのサイズにきっちり一致するようなオブジェクトが生成されるわけではなさそう(サボテンの例がそう)

所感
- 応用的にはとても面白いが、パノラマ生成で潜在空間の平均や補間を取るのはGANの時代から行われており、ブートストラップのようなネットワーク内のマスキングもGAN時代のInpaintingで行われていたため、研究としての新規性 is どこ?
- 論文の数式が複雑だったらさぞかし難しいことやっているのかと思ったら、ただの重み付き平均とマスクで拍子抜けした感
- パノラマ生成がDiffuserでざっくり使えるのがいい。領域指定生成も対応されるといいな(3/2時点 ブートストラップがそこまで難しい処理ではないので、自分でハックしちゃうとか)
- パノラマ生成は、解像度分拡散ステップを回すだけあって重い
- LoRAと組み合わせてパノラマ生成できたら面白そう
- こんな研究もある Collage Diffusion
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー