
MultiDiffusionを試す(パノラマ生成、空間コントロール)


パノラマ生成、空間コントロールできるMultiDiffusionを試してみました。空間コントロールでは、マスク設定し、領域ごとにプロンプトを指定することでレイアウトをある程度定義することも可能です。LoRAも併用できますが、あまり相性は良くないことがわかりました。
目次
はじめに
以前紹介したMultiDiffusionの空間コントロールができるようになったので、パノラマ生成と一緒に試していきたいと思います。
MultiDiffusionには2つのモードがあります。
- パノラマ生成
- 空間コントロール
パノラマ生成
公式サイトからの引用です。

このように複数の画像を横につなげて生成するのがパノラマ生成です。「a photo of mountain range at twilight」という共通のプロンプトから生成するもので、ユーザーの写真をつなげたものではありません。このようにフォトリアリスティックな合成ができます。
パノラマ生成はDiffusersで対応されており、StableDiffusionPanoramaPipelineで簡単にできます。
空間コントロール
論文ではSpatial Controlと呼ばれているものです。論文からの図の引用です。
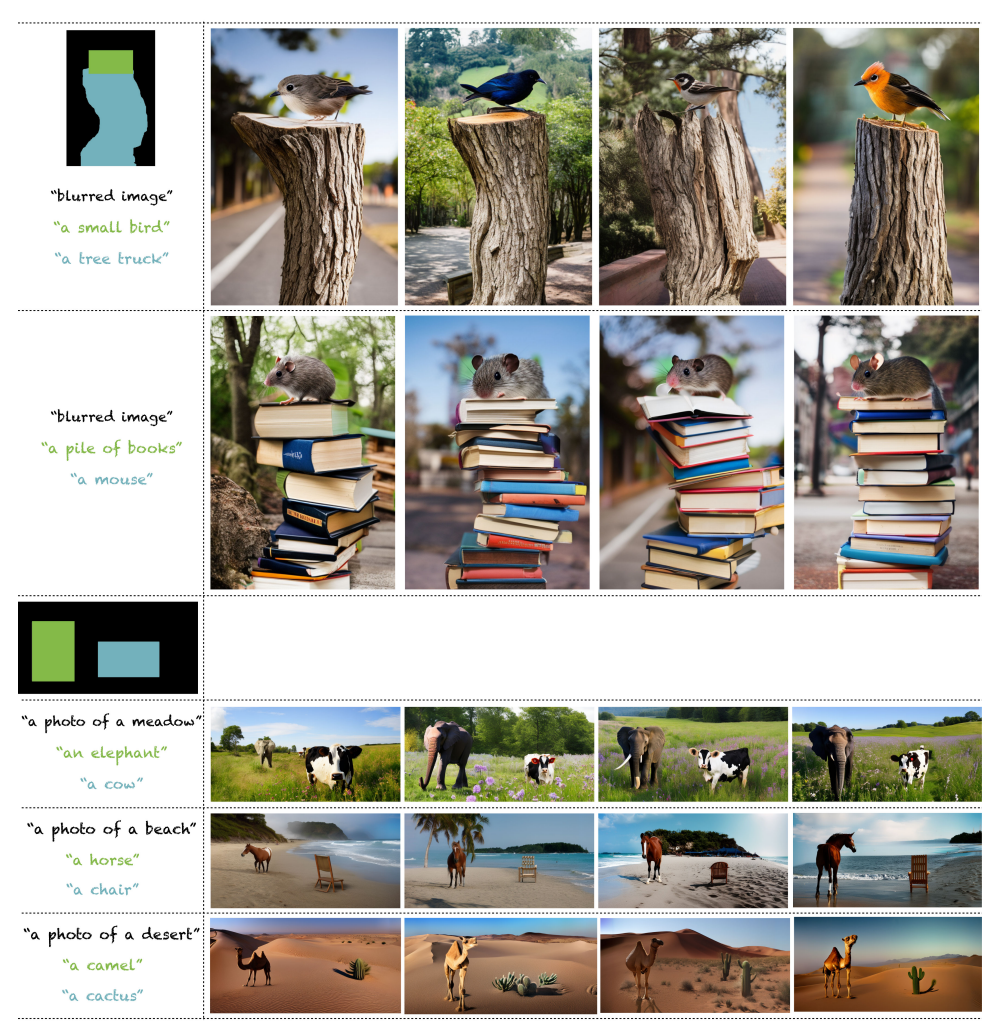
「ここに何を配置して」というマスクを与えて、その情報をもとに生成していくものです。マスクは複数枚配置可能で、マスクごとに異なるプロンプトを設定可能です。
空間コントロールは2023/3/30現地点のDiffusers(ver:0.14.0)では対応していません。Huggingfaceにサンプルがあるので、こちらのコードをベースに実行します。
パノラマ生成
まずは普通にStable Diffusionで
論文に紹介されている例で生成してみます。
import torch
from diffusers import StableDiffusionPanoramaPipeline, EulerDiscreteScheduler
model_ckpt = "stabilityai/stable-diffusion-2-1-base"
scheduler = EulerDiscreteScheduler.from_pretrained(model_ckpt, subfolder="scheduler")
pipe = StableDiffusionPanoramaPipeline.from_pretrained(model_ckpt, scheduler=scheduler, torch_dtype=torch.float16)
pipe = pipe.to("cuda:1") # GPU IDで変えてね
prompt = "cartoon panorama of spring summer beautiful nature"
image = pipe(prompt, width=3072).images[0]
image.save("panorama.jpg", quality=92)
プロンプト:「cartoon panorama of spring summer beautiful nature」

プロンプト:「A photo of a marshland with a river winding through it」

SchedulerはDDIMSchedulerとEulerDiscreteSchedulerはできましたが、UniPCMultistepSchedulerでは真っ黒な画像が生成されできませんでした。
Anything V4に変える
MultiDiffusionはあくまでStable DiffusionのText2Imageをベースにしているだけなので、任意のDiffusionモデルに差し替えることが可能です。例えばAnything V4に変えてみましょう。
プロンプト:「cartoon landscape of spring summer beautiful nature」

つなぎ目部分で若干空間的な歪みが出ていますがきれいですね。ちなみに、「landscape」を元のように「panorama」とすると、360度カメラのような歪みが出てしまいました。

プロンプト:「A photo of the wetland」

ちなみにAnything V4の場合は苦手な単語があるようで、「wetland」を「marshland」に置き換えるとかなり微妙な出力になりました。訓練データにあまりないのかもしれません。
あとAnything V4ってなぜかくすんだ出力する場合がありますよね
パノラマ生成+LoRA
LoRA導入
パノラマ生成の中身はただのStable Diffusionなので、LoRAを入れてみましょう。私が宗谷丘陵で取ってきた120枚程度の写真を訓練素材としてLoRAを作ります。ベースはSD2.1-baseです。
純粋なLoRAのText2Imageの生成結果は以下のようになります。

これ自体はまあまあうまく行っているように見えます。プロンプトは「a photo of sks」です。
LoRA+パノラマ
導入の方法はこれまで通りpipelineに噛ませます
pipe = StableDiffusionPanoramaPipeline.from_pretrained(model_ckpt, scheduler=scheduler, torch_dtype=torch.float16)
if pipe.safety_checker is not None:
pipe.safety_checker = lambda images, **kwargs: (images, False)
pipe.unet.load_attn_procs("weights/souya_weights.bin") # ここを追加
pipe = pipe.to("cuda:1")
パノラマ生成:「a photo of sks」

うーんそうなるよなあ…。という出力です。多分LoRAみたいに出力を限定して、潜在空間が離散的になってしまうのと相性悪いのかもしれません。
プロンプトを若干変えて「a photo of sks, panorama」としてみます。

繋がりはよくなりましたが「どこだここ?」という出力になってしまいましたね(元のコンテクストを無視している)。あくまで私の直感ですが、パノラマ生成とLoRAは多分相性あんまり良くないんじゃないかと思います。
空間コントロール
最近公開されたHuggingFaceのSpaceをもとに進めます。こちらにあるコードをもとに作ります。
マスクの定義方法
ここが若干ハマったのですが、マスクはレイヤー別に白黒で作ります。例えば、犬と猫を空間上に位置を指定して配置したいとします。この場合、犬のマスク画像と、猫のマスク画像を別々に作ります。
そして各マスク画像は、白をTrue、黒をFalseとします。例えば、以下のようなマスクがあったとき

このとき白の部分に目的のオブジェクトが配置されます。
ここでは3枚のマスク画像を作りました。

空間コントロールのコード
from transformers import CLIPTextModel, CLIPTokenizer, logging
from diffusers import AutoencoderKL, UNet2DConditionModel, DDIMScheduler
# # suppress partial model loading warning
logging.set_verbosity_error()
import torch
import torch.nn as nn
import torchvision.transforms as T
import argparse
import numpy as np
from PIL import Image
from typing import List
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
# torch.backends.cudnn.deterministic = True
# torch.backends.cudnn.benchmark = True
def get_views(panorama_height, panorama_width, window_size=64, stride=8):
panorama_height /= 8
panorama_width /= 8
num_blocks_height = (panorama_height - window_size) // stride + 1
num_blocks_width = (panorama_width - window_size) // stride + 1
total_num_blocks = int(num_blocks_height * num_blocks_width)
views = []
for i in range(total_num_blocks):
h_start = int((i // num_blocks_width) * stride)
h_end = h_start + window_size
w_start = int((i % num_blocks_width) * stride)
w_end = w_start + window_size
views.append((h_start, h_end, w_start, w_end))
return views
class MultiDiffusion(nn.Module):
def __init__(self, device, sd_version='2.1', hf_key=None):
super().__init__()
self.device = device
self.sd_version = sd_version
print(f'[INFO] loading stable diffusion...')
if hf_key is not None:
print(f'[INFO] using hugging face custom model key: {hf_key}')
model_key = hf_key
elif self.sd_version == '2.1':
model_key = "stabilityai/stable-diffusion-2-1-base"
elif self.sd_version == '2.0':
model_key = "stabilityai/stable-diffusion-2-base"
elif self.sd_version == '1.5':
model_key = "runwayml/stable-diffusion-v1-5"
elif self.sd_version == 'anything_v4':
model_key = "andite/anything-v4.0"
else:
model_key = self.sd_version #For custom models or fine-tunes, allow people to use arbitrary versions
#raise ValueError(f'Stable-diffusion version {self.sd_version} not supported.')
# Create model
self.vae = AutoencoderKL.from_pretrained(model_key, subfolder="vae").to(self.device)
self.tokenizer = CLIPTokenizer.from_pretrained(model_key, subfolder="tokenizer")
self.text_encoder = CLIPTextModel.from_pretrained(model_key, subfolder="text_encoder").to(self.device)
self.unet = UNet2DConditionModel.from_pretrained(model_key, subfolder="unet").to(self.device)
self.scheduler = DDIMScheduler.from_pretrained(model_key, subfolder="scheduler")
print(f'[INFO] loaded stable diffusion!')
@torch.no_grad()
def get_random_background(self, n_samples):
# sample random background with a constant rgb value
backgrounds = torch.rand(n_samples, 3, device=self.device)[:, :, None, None].repeat(1, 1, 512, 512)
return torch.cat([self.encode_imgs(bg.unsqueeze(0)) for bg in backgrounds])
@torch.no_grad()
def get_text_embeds(self, prompt, negative_prompt):
# Tokenize text and get embeddings
text_input = self.tokenizer(prompt, padding='max_length', max_length=self.tokenizer.model_max_length,
truncation=True, return_tensors='pt')
text_embeddings = self.text_encoder(text_input.input_ids.to(self.device))[0]
# Do the same for unconditional embeddings
uncond_input = self.tokenizer(negative_prompt, padding='max_length', max_length=self.tokenizer.model_max_length,
return_tensors='pt')
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
# Cat for final embeddings
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
return text_embeddings
@torch.no_grad()
def encode_imgs(self, imgs):
imgs = 2 * imgs - 1
posterior = self.vae.encode(imgs).latent_dist
latents = posterior.sample() * 0.18215
return latents
@torch.no_grad()
def decode_latents(self, latents):
latents = 1 / 0.18215 * latents
imgs = self.vae.decode(latents).sample
imgs = (imgs / 2 + 0.5).clamp(0, 1)
return imgs
@torch.no_grad()
def generate(self, masks, prompts, negative_prompts='', height=512, width=2048, num_inference_steps=50,
guidance_scale=7.5, bootstrapping=20):
# get bootstrapping backgrounds
# can move this outside of the function to speed up generation. i.e., calculate in init
bootstrapping_backgrounds = self.get_random_background(bootstrapping)
# Prompts -> text embeds
text_embeds = self.get_text_embeds(prompts, negative_prompts) # [2 * len(prompts), 77, 768]
# Define panorama grid and get views
latent = torch.randn((1, self.unet.in_channels, height // 8, width // 8), device=self.device)
noise = latent.clone().repeat(len(prompts) - 1, 1, 1, 1)
views = get_views(height, width)
count = torch.zeros_like(latent)
value = torch.zeros_like(latent)
self.scheduler.set_timesteps(num_inference_steps)
with torch.autocast('cuda'):
for i, t in enumerate(self.scheduler.timesteps):
count.zero_()
value.zero_()
for h_start, h_end, w_start, w_end in views:
masks_view = masks[:, :, h_start:h_end, w_start:w_end]
latent_view = latent[:, :, h_start:h_end, w_start:w_end].repeat(len(prompts), 1, 1, 1)
if i < bootstrapping:
bg = bootstrapping_backgrounds[torch.randint(0, bootstrapping, (len(prompts) - 1,))]
bg = self.scheduler.add_noise(bg, noise[:, :, h_start:h_end, w_start:w_end], t)
latent_view[1:] = latent_view[1:] * masks_view[1:] + bg * (1 - masks_view[1:])
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
latent_model_input = torch.cat([latent_view] * 2)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeds)['sample']
# perform guidance
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the denoising step with the reference model
latents_view_denoised = self.scheduler.step(noise_pred, t, latent_view)['prev_sample']
value[:, :, h_start:h_end, w_start:w_end] += (latents_view_denoised * masks_view).sum(dim=0,
keepdims=True)
count[:, :, h_start:h_end, w_start:w_end] += masks_view.sum(dim=0, keepdims=True)
# take the MultiDiffusion step
latent = torch.where(count > 0, value / count, value)
# Img latents -> imgs
imgs = self.decode_latents(latent) # [1, 3, 512, 512]
img = T.ToPILImage()(imgs[0].cpu())
return img
def preprocess_mask(mask_path, h, w, device):
mask = np.array(Image.open(mask_path).convert("L"))
mask = mask.astype(np.float32) / 255.0
mask = mask[None, None]
mask[mask < 0.5] = 0
mask[mask >= 0.5] = 1
mask = torch.from_numpy(mask).to(device)
mask = torch.nn.functional.interpolate(mask, size=(h, w), mode='nearest')
return mask
def main(mask_paths: List[str],
bg_prompt: str,
fg_prompts: List[str],
bg_negative: str = "artifacts, blurry, smooth texture, bad quality, distortions, unrealistic, distorted image",
fg_negative: str = "low quality",
sd_version: str = "2.1",
width: int = 512, height: int = 512,
seed: int = 0, bootstrapping: int = 20, steps: int=50,
device_name: str="cuda:0"):
seed_everything(seed)
device = torch.device(device_name)
sd = MultiDiffusion(device, sd_version)
prompts = [bg_prompt] + fg_prompts
neg_prompts = [bg_negative] + [fg_negative for i in range(len(fg_prompts))]
fg_masks = torch.cat([preprocess_mask(mask_path, height // 8, width // 8, device_name) for mask_path in mask_paths])
bg_mask = 1 - torch.sum(fg_masks, dim=0, keepdim=True)
bg_mask[bg_mask < 0] = 0
masks = torch.cat([bg_mask, fg_masks])
image = sd.generate(masks, prompts, neg_prompts, height, width, steps, bootstrapping=bootstrapping)
# save image
image.save('result.jpg', quality=92)
if __name__ == '__main__':
main(["masks/mask_1.png", "masks/mask_2.png"],
"ocean, beach",
["palm tree", "moon"], device_name="cuda:1", seed=0)
これを実行すると以下のようになります。ちなみにAnything V4対応は私が入れました。

なんかちょっとヤシの木の生え方がおかしいですが、ヤシの木と満月の両方が描画できました。
ちなみに解像度を横に広げると以下のようになります(横解像度2048)

ブートストラップとか入っているせいでしょうが、MultiDiffusionはパノラマ出力させたほうが面白い気がします。ハイコンテクストになりやすいのでしょうか。
インスタンスを追加
3つ目のインスタンスを追加します。左下に座っているテディベア(A sitting teddy bear)を追加します。
if __name__ == '__main__':
main(["masks/mask_1.png", "masks/mask_2.png", "masks/mask_3.png"],
"ocean, beach, night",
["palm tree", "full moon", "a sitting teddy bear"], device_name="cuda:1", seed=0, width=512)
512解像度だと、テディベア以外にもヤシの木の本数が変わったり、月の大きさが変わっていますね。

2048解像度だとそこまで変わっていないように見えます。ブートストラップが効いているのでしょうか?

Anything V4です。これはプロンプトで指定していないので、結構な頻度で女の子が登場するので、プロンプトとシードを調整しました。

if __name__ == '__main__':
main(["masks/mask_1.png", "masks/mask_2.png", "masks/mask_3.png"],
"backdrop, ocean, beach, night",
["palm tree", "full moon", "a sitting teddy bear"], device_name="cuda:1", seed=1, width=2048, sd_version="anything_v4", fg_negative="person, lowquality")
Fine-tuningされたモデルのせいか、パノラマ生成するとジオメトリ的な違和感が若干ありますね。個々のパッチはきれい!
所感
- パノラマ生成
- LoRAはぱっと見相性悪そう
- 潜在空間がなめらかなモデルが向いているので、AdapterよりもInversionみたいな形で写真に対応する潜在変数を求めるほうがいいかもしれない
- ユーザーに画像与えてImage2Imageみたいなことしたいなら流石にもっと単純なモデルでいいかも…?
- 空間コントロール
- 背景をText2Imageではなく、Inpaintingの要領で写真に設定したい(ここが一番ほしい。GLIGENはできた)
- コピペしただけなので自分の実装が悪いだけなのかもしれないが、低解像度でインスタンス追加したときの挙動が安定しない
- (Diffuser対応はほしいなあ…)
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー