
画像分類で比較するBatch Norm, Instance Norm, Spectral Normの勾配の大きさ


GANの安定化のために、Batch Normalizationを置き換えるということがしばしば行われます。その置き換え先として、Spectral Norm、Instance Normなどが挙げられます。今回はGANではなく普通の画像分類の問題としてBatch Normを置き換えし、勾配のノルムどのように変わるかを比較します。
目次
はじめに
GANの安定化のためにBatch Normalizationをそのまま使わない、ここを工夫するというのはほとんど定石になりつつあります。最たるものが「Spectral Normalization」で、特異値分解によるリプシッツ定数のコントロールにより、Dのリプシッツ連続性を保証するような制約をおくということを行っています。具体的には、GANのDのBatch NormをSpectral Normで置き換えするという単純かつ明快なものです。このSpectral Normは、GANにおいてImage Netに対する現在のSoTAであるBigGANにおいても広く使われています。
Spectral Normを使わなくてもBatch Normの置き換えをするというケースはあります。例えば、pix2pix HDではNormalizationにInstance Normalizationを使っています。またProgressive GANではLayer Normzalitionを使ったりPixelwise Normalizationを使ったりといろいろ工夫をしています。
今回は、一旦GANから離れて通常の画像分類の問題に戻り、「Normalizationの違いによってレイヤー単位での勾配がどの程度変わるのか」を調べます。具体的には、画像分類のモデルを訓練していって、レイヤー単位の勾配ノルムがどのように変化するのかを調べます。
やること
CIFAR-10の分類モデルを訓練します。以下の2つのモデルを用意します(モデルの詳細はコード参照)。
- 10層モデル
- ResNetライクなモデル(ResNetの論文からCIFARの解像度にあうように適当に変更したものです)
そして各モデルに対し、Normalizationを3種類変更します。すべてPyTorchに組み込まれているものです。
- Batch Normalization
- Instance Normalization
- Spectral Normalization
すべてで6ケースになります。各ケースに対してエポックのはじめにConvレイヤーの勾配ノルムを計算します。具体的には、
def calc_gradients(model, input_x, target_y):
model.zero_grad()
loss_func = torch.nn.CrossEntropyLoss()
loss = loss_func(model(input_x), target_y)
loss.backward()
grads = [p.grad.norm().item() for p in model.parameters() if len(p.size()) == 4]
return grads
このようなコードで計算します。ここでinput_xは入力画像、target_yは本物のラベルです。テストデータすべてに対する勾配ノルムを計算し、ミニバッチ単位で平均します。この平均をエポック単位、ケース単位で比較します。
バッチサイズは128とし、学習率は0.1でモメンタム係数は0.9としました。100エポック訓練し、50エポック目と80エポック目で学習率を1/10にします。また、ResNetライクなモデルに限り、Weight Decay=0.0001を追加しました。
注意
Instance NormのResNetライクなモデルだけ、なぜかうまく行かなかった(ロスがずっと下がらないし初期の勾配がすべて0になってしまう)ので結果を省略します。Batch Normはすべてで訓練が成功しましたが、Spectral NormやInstance Normを画像分類で使う場合は「初期値ガチャ」みたいなものがあるようで、そのガチャに失敗するとずっとロスが下がらないということが観測されました。ここに掲載しているのはうまくいったケースです。
テスト精度推移
テストデータをValidationとしたときの精度推移はこちらです。横軸がエポック、縦軸が精度を表します。
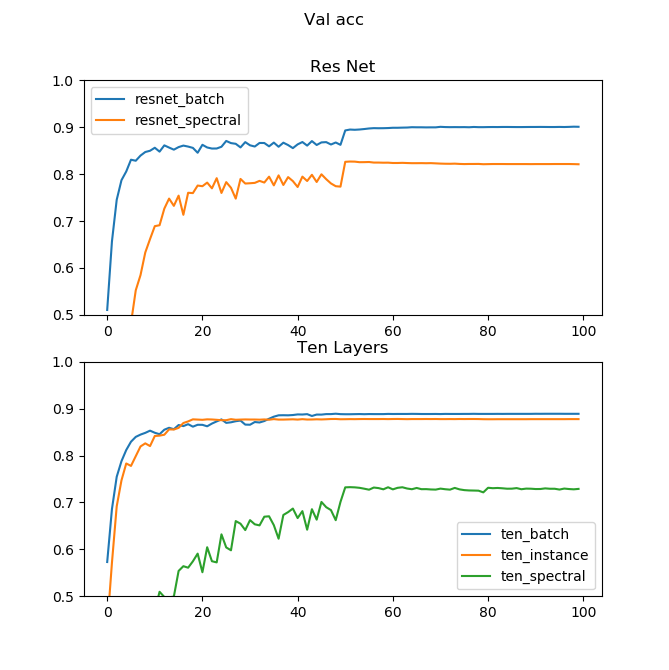
精度を単純に上げたいのなら、従来どおりBatch Normzalitionがやはり有効なようです。Spectral Normは振れ幅が低すぎてロスが下がり切る前に学習率が減衰してしまったのかもしれません。
Normalization別の勾配ノルム
次はモデル-エポック単位で切り出したときの勾配推移です。横軸が層のインデックス(大きい値ほど深い)、縦軸がノルムの値です。
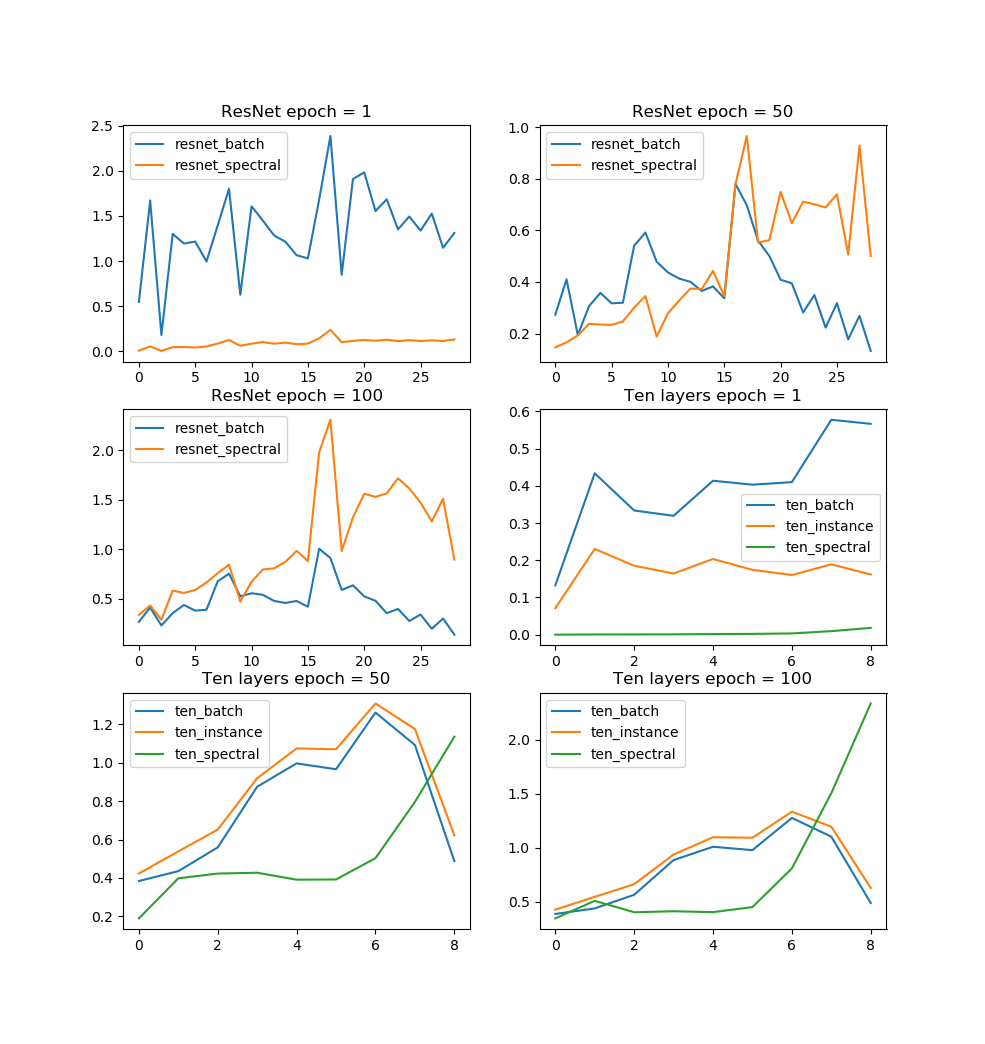
Batch Normは訓練開始時の勾配がひたすら大きいという傾向があります。これはResNet、10層問わず同じです。Batch Normの勾配は訓練が進むほど他のNormalizationよりも低くなりがちになります。
Instance Normは10層モデルだけですが、Batch Normほど訓練開始時の勾配は大きくありません。最終的にはBatch Normと同じように訓練が進んでいきます。
少し変わっているのがSpectral Normです。Spectral Normの訓練開始時の勾配は驚くほど低いです。GANのように失敗が訓練開始時に起きやすいケースでは、Spectral Normは有効でしょう。しかし面白いのがその後で、訓練が進むほどBatch NormやInstance Normの勾配が下がっていくのに対して、Spectral Normはだんだん勾配が大きくなっていきます。特に10層モデルのようなResNetではない(Skip Connectionのない)ケースでは顕著で、層の深さに対して指数関数的に上がっているようにも見えます。Self attention GANやBig GANのように訓練が進むと崩壊するケースがあるのはもしかしたらこういう理由なのかもしれません。ResNetを使えば多少は勾配の発散を軽減できそうなので、GANでのSpectral NormがResNetとセットで使われるのもなんとなく理解できます。
Epoch別の勾配ノルム
次は、モデル-Normalization単位で切り出したときの勾配推移です。横軸が層のインデックス(大きいほど深い層)、縦軸がノルムの値です。
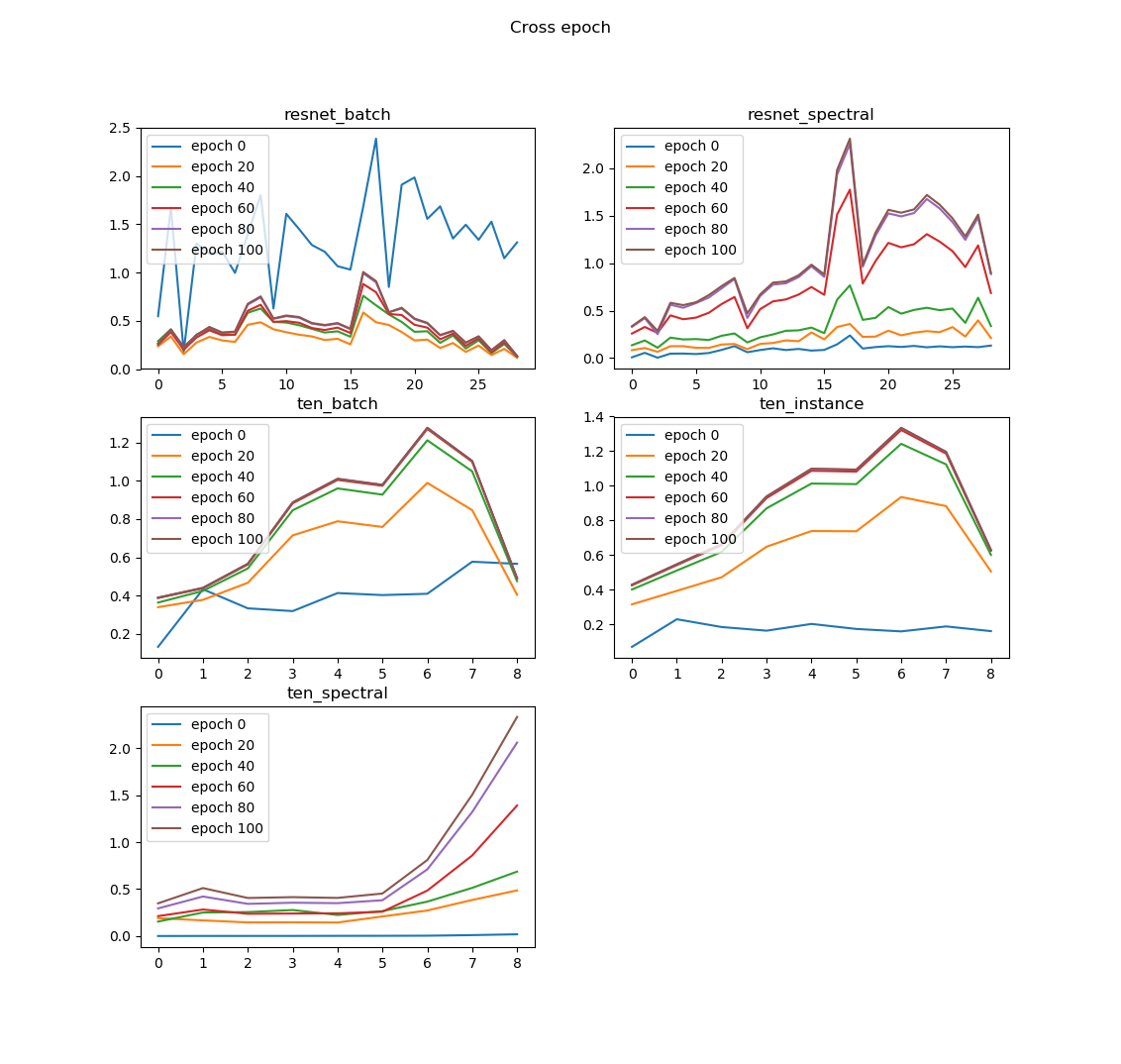
訓練が進むほど勾配が大きくなるのはどのNormalizationでも共通でした(ただしResNetのBatch Normだけ例外)。変わるのはNormalization別の相対的な順位ということでしょうか。
10層モデルの場合、Spectral Normは初期の勾配は低いですが、訓練が進むほど、層の深さに対して指数関数的な勾配構成になります。Batch NormやInstance Normの場合は真ん中の層の勾配が膨らむので、深い層の勾配が膨らむのはあんまりよくないような感じがします(GANでモデルを深くするというのはあんまりよくないという話は聞いた記憶がある)。Spectral Normでも、ResNetにすると深い層の勾配が膨らまなくなるので、ResNetは大事なのでしょう。
しかし、ResNetにするとなぜかBatch Normの初期の勾配が驚くほど高いという不思議なことがおこります。これは10層モデルでは起こりませんでした。確かにこれはこれでよくないのでしょう(Spectral Normが良いと言われる理由はおそらくこれ)。
まとめ
今回の実験をまとめます。
- 訓練開始時の勾配ノルムは、「Batch Norm>Instance Norm>Spectral Norm」だった。特にResNetではBatch Normが初期になぜかとても高い勾配を出すので、これがGANの失敗に寄与しているのだと思われる。この点ではSpectral Normは良い。
- しかし訓練が進んでいくと、Spectral Normの勾配ノルムがBatch Normよりも遥かに高くなるケースがある。ResNetを使わない場合、深い層ほど指数関数的に勾配が増加していくので、Spectral Normを使う場合はResNetを使ったほうがよさそう。GANで訓練がある程度進んだところから急に崩壊するというのは、このSpectral Normの勾配が大きくなりすぎていることによるものなのかもれない。
- Spectral Normは現時点(2019年9月)では非常に有効なGANの安定化手法であるが、もしかするとまだまだ改良の余地があるのかもしれない。
コード
モデル(models.py)
import torch
from torch import nn
import torch.nn.functional as F
import torchvision
from torchvision import transforms
from torch.nn.utils.spectral_norm import spectral_norm
class TenLayersModel(nn.Module):
def __init__(self, normalization):
super().__init__()
self.convs = self.create_model(normalization)
self.linear = nn.Linear(256, 10)
def conv_norm_relu(self, in_ch, out_ch, normalization):
layers = []
if normalization == "spectral":
w = nn.Conv2d(in_ch, out_ch, 3, padding=1)
layers.append(spectral_norm(w))
else:
layers.append(nn.Conv2d(in_ch, out_ch, 3, padding=1))
if normalization == "batch":
layers.append(nn.BatchNorm2d(out_ch))
elif normalization == "instance":
layers.append(nn.InstanceNorm2d(out_ch))
layers.append(nn.ReLU(True))
return layers
def create_model(self, normalization):
layers = []
for in_ch in [3, 64, 64]:
layers += self.conv_norm_relu(in_ch, 64, normalization)
layers.append(nn.AvgPool2d(2))
for in_ch in [64, 128, 128]:
layers += self.conv_norm_relu(in_ch, 128, normalization)
layers.append(nn.AvgPool2d(2))
for in_ch in [128, 256, 256]:
layers += self.conv_norm_relu(in_ch, 256, normalization)
layers.append(nn.AvgPool2d(8))
return nn.Sequential(*layers)
def forward(self, inputs):
x = self.convs(inputs).view(inputs.size(0), -1)
x = self.linear(x)
return x
class ResNetPreactModule(nn.Module):
def __init__(self, in_ch, out_ch, downsampling, normalization):
assert normalization in ["batch", "spectral", "instance"]
super().__init__()
self.conv1 = nn.Conv2d(in_ch, out_ch, 3, padding=1)
self.conv2 = nn.Conv2d(out_ch, out_ch, 3, padding=1)
self.shortcut_conv = nn.Conv2d(in_ch, out_ch, 1) if in_ch != out_ch else None
self.norm1 = self.get_normalization(in_ch, normalization)
self.norm2 = self.get_normalization(out_ch, normalization)
if normalization == "spectral":
self.conv1 = spectral_norm(self.conv1)
self.conv2 = spectral_norm(self.conv2)
self.shortcut_conv = spectral_norm(self.shortcut_conv) if self.shortcut_conv is not None else None
self.downsampling = nn.AvgPool2d(downsampling) if downsampling > 1 else None
def get_normalization(self, ch, normalization):
if normalization == "batch":
return nn.BatchNorm2d(ch)
elif normalization == "instance":
return nn.InstanceNorm2d(ch)
else:
return None
def forward(self, inputs):
# main path
x = self.norm1(inputs) if self.norm1 is not None else inputs
x = F.relu(x)
x = self.conv1(x)
x = self.norm2(x) if self.norm2 is not None else x
x = F.relu(x)
x = self.conv2(x)
# shortcut path
shortcut = self.shortcut_conv(inputs) if self.shortcut_conv is not None else inputs
# downsampling
if self.downsampling is not None:
x = self.downsampling(x)
shortcut = self.downsampling(shortcut)
return x + shortcut
class ResNetLikeModel(nn.Module):
def __init__(self, normalization):
super().__init__()
self.conv = nn.Sequential(
*self.resnet_block(3, 64, 3, normalization),
*self.resnet_block(64, 128, 4, normalization),
*self.resnet_block(128, 256, 6, normalization, enable_downsampling=False),
nn.AvgPool2d(8)
)
if normalization == "batch":
self.last_norm = nn.BatchNorm2d(256)
elif normalization == "instance":
self.last_norm = nn.InstanceNorm2d(256)
else:
self.last_norm = None
self.linear = nn.Linear(256, 10)
def resnet_block(self, in_ch, out_ch, reps, normalization, enable_downsampling=True):
layers = []
for i in range(reps):
current_in = in_ch if i == 0 else out_ch
down = 2 if i == reps-1 and enable_downsampling else 1
layers.append(ResNetPreactModule(current_in, out_ch, down, normalization))
return layers
def forward(self, inputs):
x = self.conv(inputs)
x = self.last_norm(x) if self.last_norm is not None else x
x = x.view(x.size(0), -1)
x = self.linear(x)
return x
勾配計算(compute_gradients.py)
import torch
import torchvision
from models import TenLayersModel, ResNetLikeModel
from torchvision import transforms
from tqdm import tqdm
import numpy as np
import os
import pickle
def load_cifar():
trans = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = torchvision.datasets.CIFAR10(root="./data", train=True, download=True, transform=trans)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True)
testset = torchvision.datasets.CIFAR10(root="./data", train=False, download=True, transform=trans)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False)
return trainloader, testloader
def calc_gradients(model, input_x, target_y):
model.zero_grad()
loss_func = torch.nn.CrossEntropyLoss()
loss = loss_func(model(input_x), target_y)
loss.backward()
grads = [p.grad.norm().item() for p in model.parameters() if len(p.size()) == 4]
return grads
def main(network, normalization):
if network == "ten":
model = TenLayersModel(normalization)
elif network == "resnet":
model = ResNetLikeModel(normalization)
model_name = f"{network}_{normalization}"
output_dir = "snapshot"
if not os.path.exists(output_dir):
os.mkdir(output_dir)
device = "cuda"
batch_size = 128
model.to(device)
model = torch.nn.DataParallel(model)
trainloader, testloader = load_cifar()
log_gradients = []
log_loss = []
log_val_acc = []
weight_decay = 0.0001 if network == "resnet" else 0
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=weight_decay)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[50, 80], gamma=0.1)
criterion = torch.nn.CrossEntropyLoss()
max_val_acc = 0.0
for epoch in tqdm(range(100)):
# gradient check
gradients = []
for X, y in testloader:
if len(X) != 128: continue
X, y = X.to(device), y.to(device)
gradients.append(calc_gradients(model, X, y))
model.zero_grad()
layer_grads = np.mean(np.array(gradients), axis=0) # batch-wise mean
log_gradients.append(layer_grads)
# train
train_loss = 0.0
for i, (X, y) in enumerate(trainloader):
X, y = X.to(device), y.to(device)
optimizer.zero_grad()
y_pred = model(X)
loss = criterion(y_pred, y)
loss.backward()
optimizer.step()
train_loss += loss.item()
log_loss.append(train_loss / (i + 1))
# validation
with torch.no_grad():
correct, total = 0, 0
for X, y in testloader:
X, y = X.to(device), y.to(device)
outputs = model(X)
_, pred = torch.max(outputs.data, 1)
total += y.size(0)
correct += (pred == y).sum().item()
log_val_acc.append(correct / total)
# save model
if max_val_acc < log_val_acc[-1]:
torch.save(model.state_dict(), f"{output_dir}/{model_name}.pytorch")
max_val_acc = log_val_acc[-1]
scheduler.step()
print("Epoch =", epoch, "Loss =", log_loss[-1], "Val_acc =", log_val_acc[-1], "/ ", model_name)
# print(log_gradients[-1])
# save result
with open(f"{output_dir}/log_{model_name}.pkl", "wb") as fp:
result = {"gradient":log_gradients, "loss":log_loss, "val_acc":log_val_acc}
pickle.dump(result, fp)
if __name__ == "__main__":
for model in ["ten", "resnet"]:
for norm in ["batch", "instance", "spectral"]:
main(model, norm)
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー