
OpenAIの新しいEmbeddingAPIをlivedoorニュースコーパスで試す


OpenAIの新しいEmbedding APIを試してみました。Embedding APIをテキスト分類のバックボーンとして使用し、ロジスティック回帰を行います。Livedoorニュースコーパスにおいて、V3モデルの一貫した有効性が示せました。
目次
概要
- OpenAIの新しいEmbedding APIが発表された
- これの効果をNLPでよく使われる分類データセット「livedoorニュースコーパス」で実験した
- 具体的には、各種のEmbedding APIで文章全体のEmbeddingをとり、ロジスティック回帰を行い分類精度を比較する
- その結果、ロジスティック回帰のバックボーンにおいても、V3モデルが一貫してV2より精度が出ることがわかった
Embeddings
データを(この場合はテキストデータ)を何らかの数値表現に落とし込むモデル。Embedding自体はChatGPTの登場前からあった。
Word2Vecはその例。Word2Vecは単語単位のEmbeddingで、文章単位ならSentence Embedding、複数の文章をまたいだ全体のEmbeddingといろんなスコープでEmbeddingを考えられる。従来はそれぞれ別のモデルを使っていたが、OpenAIのEmbedding APIは全てに対応している。

https://openai.com/blog/new-embedding-models-and-api-updates
重要なのは、Embeddingは数値表現なので、その末尾に何らかの線形回帰モデル(例:ロジスティック回帰)を入れれば、分類モデルを手軽に(CPUでも余裕で)訓練できるということ。これは、マルチモーダルの場合はCLIPにおけるAdapterと同じ考え方。
Livedoorニュースコーパス
古くからNLPで使われている日本語データセット。
https://www.rondhuit.com/download.html
livedoorニュースからとられたデータセットで、以下の異なるソースから取られている。分類アノテーションとして付与されているのは、これらのニュースカテゴリ(例:トピックニュース、Sports News)。すべてのニュースが1つのカテゴリに属している。
- トピックニュース
- Sports Watch
- ITライフハック
- 家電チャンネル
- MOVIE ENTER
- 独女通信
- エスマックス
- livedoor HOMME
- Peachy
すなわち、分類問題として解くのは、ニュースの本文をインプットとして、そのニュース記事が属するニュースカテゴリ(トピックニュース、Sports News)を予測する問題。
データ構造
各ニュースは1つのテキストファイルからなる。例えば、「ldcc-20140209/text/sports-watch/sports-watch-4597641.txt」では、
http://news.livedoor.com/article/detail/4597641/
2010-02-10T10:50:00+0900
【Sports Watch】秋山成勲、メールで吉田に対戦迫った!?
今月8日、都内ホテルでは、総合格闘家・吉田秀彦の引退試合興行「ASTRA」の開催が発表された。
バルセロナ五輪柔道金メダリストとしての実績を引っさげ、2002年にプロ総合格闘家に転向。以後、数々の死闘を繰り広げてきた吉田。昨年大晦日のDynamite!!では、石井慧との金メダリスト対決を制し、4月に迎える引退試合の相手には、桜庭和志やまさかの朝青龍といった報道が駆け巡る中、“反骨の柔道王”秋山成勲が吉田にメールで対戦を迫っていたというのだ。
会見翌日の9日に更新された秋山成勲オフィシャルブログでは、「吉田秀彦対秋山成勲」と題し、「常に憧れ目標にしてきた吉田先輩が引退。正直寂しい気持ちはありますが、ほんまにお疲れ様でした!引退試合はもちろん自分とやるでしょ!?」とストレートに書き綴りながらも、「さっき吉田先輩にメールで自分とやるでしょ?的なメールを打って、軽く流されましたが」と、実際に吉田へ対戦を打診をしていたことを明かした。
もちろん、階級が違う上、秋山は米UFCを主戦場にしている現状、対戦することはまずない。それでも、我が道を行き、空気を一切読まない秋山だけに、案外本気に考えていた可能性もなきにしもあらず——。そんなブログの最後には、「ほんまに柔道から格闘技の道を作って頂いたパイオニアだと自分は思い尊敬してます!引退試合頑張ってください!」と吉田にエールを送る秋山であった。
とある。このとき
- 1行目:記事のURL
- 2行目:配信日時
: 3行目:記事タイトル - 4行目以降:本文
である。ここで気をつけないといけないのは、記事タイトルを本文から分離して考えるということである。この例では、記事タイトルに「Sports Watch」と書かれているため、本文を見なくても記事タイトルでニュースカテゴリーがわかってしまう。
問題設定としては、タイトルを入れる/入れないはどちらでも構わないが、今のEmbeddingモデルだったら記事タイトルを入れないで純粋に本文データだけで評価させても十分な精度は出る。そこで、今回はタイトルを入れない難しい方の問題設定で行う。
BERT以外のアプローチ
今まではこの分類をするときはBERTを訓練するのが定番だったが、OpenAIのEmbeddingモデルを使っても(精度は若干落ちる)が同じことはできるのを確認する。
実験
以下の3モデルをEmbeddingのバックボーンとする
text-embedding-ada-002text-embedding-3-smalltext-embedding-3-large
また、訓練データを削り、Few-shotの文脈でも評価する。ここでのFew-shotとは、ChatGPTで言われるIn-context learningのFew-shotではなく、従来の意味のFew-shot。livedoorニュースコーパスではデータ数が多く(7000件以上)、OpenAIの強いモデルがある現在の世界観だとやや過剰気味なので、訓練データを最大1/200まで削り、分類性能を評価する。
livedoorニュースコーパスに対し、8:2で訓練:テスト分割を行い、訓練データは5893件得られた。訓練データに対してデータ数の圧縮を行う(テストは圧縮しない)。例えば、訓練データが7000個あって、1/200まで削るなら、訓練データを200個飛ばしでロードして訓練データは35とする。圧縮比は以下で検証した。
- 200
- 100
- 50
- 25
- 10
- 5
- 2
- 1
1の場合は、訓練データをそのまま使う例。
また、Embeddingモデルが最大8192トークンしか対応していないため、これを超えるトークン数の場合は、元のテキストをトークン数に応じて後ろの文章を切り捨てる処理を行う。
結果
テスト精度比較
テスト精度は以下の通り。
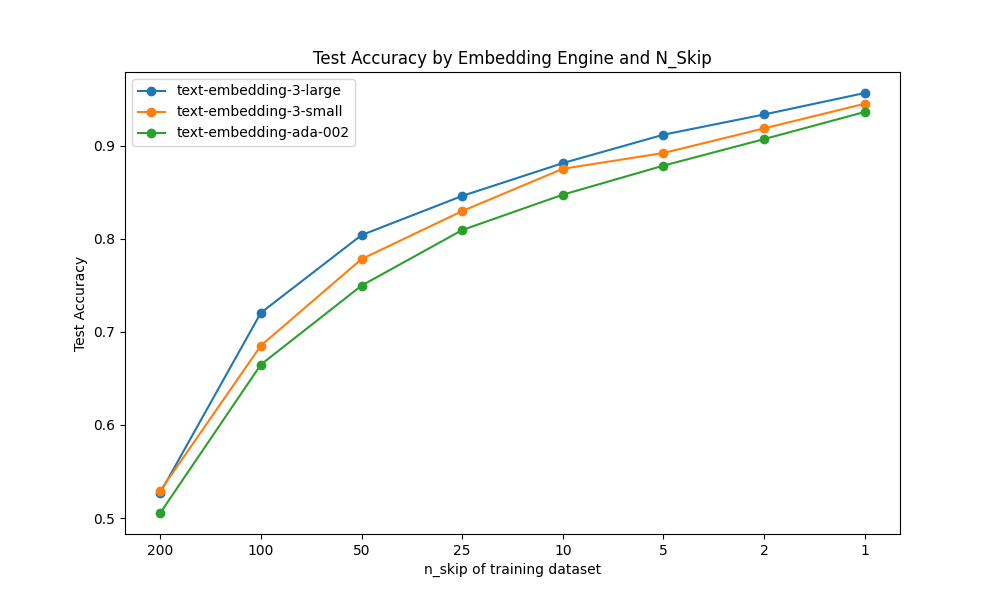
| embeddimg_engine | n_skip | n_train | test_accuracy |
|---|---|---|---|
| text-embedding-ada-002 | 200 | 30 | 50.5% |
| text-embedding-ada-002 | 100 | 59 | 66.5% |
| text-embedding-ada-002 | 50 | 118 | 75.0% |
| text-embedding-ada-002 | 25 | 236 | 80.9% |
| text-embedding-ada-002 | 10 | 590 | 84.7% |
| text-embedding-ada-002 | 5 | 1179 | 87.9% |
| text-embedding-ada-002 | 2 | 2947 | 90.7% |
| text-embedding-ada-002 | 1 | 5893 | 93.6% |
| text-embedding-3-small | 200 | 30 | 52.9% |
| text-embedding-3-small | 100 | 59 | 68.5% |
| text-embedding-3-small | 50 | 118 | 77.8% |
| text-embedding-3-small | 25 | 236 | 83.0% |
| text-embedding-3-small | 10 | 590 | 87.5% |
| text-embedding-3-small | 5 | 1179 | 89.2% |
| text-embedding-3-small | 2 | 2947 | 91.9% |
| text-embedding-3-small | 1 | 5893 | 94.5% |
| text-embedding-3-large | 200 | 30 | 52.7% |
| text-embedding-3-large | 100 | 59 | 72.0% |
| text-embedding-3-large | 50 | 118 | 80.4% |
| text-embedding-3-large | 25 | 236 | 84.6% |
| text-embedding-3-large | 10 | 590 | 88.1% |
| text-embedding-3-large | 5 | 1179 | 91.2% |
| text-embedding-3-large | 2 | 2947 | 93.4% |
| text-embedding-3-large | 1 | 5893 | 95.7% |
全般的に、OpenAIの主張どおりで、text-embedding-3シリーズのほうが精度が高い。全データを使い、text-embedding-3-largeで全データを使うと、テストデータは95.7%まで上昇し、BERTのファインチューニングに匹敵するレベルとなった。
BERTの場合は、以下のような検証報告がある
- https://medium.com/karakuri/bert%E3%82%92%E7%94%A8%E3%81%84%E3%81%9F%E6%97%A5%E6%9C%AC%E8%AA%9E%E6%96%87%E6%9B%B8%E5%88%86%E9%A1%9E%E3%82%BF%E3%82%B9%E3%82%AF%E3%81%AE%E5%AD%A6%E7%BF%92-%E3%83%8F%E3%82%A4%E3%83%91%E3%83%BC%E3%83%91%E3%83%A9%E3%83%A1%E3%83%BC%E3%82%BF%E3%83%81%E3%83%A5%E3%83%BC%E3%83%8B%E3%83%B3%E3%82%B0%E3%81%AE%E5%AE%9F%E8%B7%B5%E4%BE%8B-2fa5e4299b16
- https://github.com/YutaroOgawa/BERT_Japanese_Google_Colaboratory/blob/master/2_BERT_livedoor_news_on_Google_Colaboratory.ipynb
V2からの差分
text-embedding-ada-002(V2-Ada)からの精度差分に注目と以下のようになる。
| n_skip | n_train | V2-Ada→V3-Small | V2-Ada→V3-Large |
|---|---|---|---|
| 200 | 30 | 2.4% | -0.2% |
| 100 | 59 | 2.0% | 3.5% |
| 50 | 118 | 2.8% | 2.6% |
| 25 | 236 | 2.0% | 1.6% |
| 10 | 590 | 2.8% | 0.6% |
| 5 | 1179 | 1.4% | 2.0% |
| 2 | 2947 | 1.2% | 1.5% |
| 1 | 5893 | 0.9% | 1.2% |
基本的にV3シリーズはV2シリーズより数%高い結果となった。V3-Largeでn_skip=200の場合は、V2よりも下がってしまった。この問題は次元の呪いの可能性がある。
デフォルトの次元数はV2-AdaとV3-Smallが1536、V3-Largeが3072であり、3072次元は訓練データ30に対して自由度が高すぎると考えられる。V3のAPIは次元数を変更可能なので、もし精度にこだわる場合は、ここをチューニングしてもいいだろう。
https://platform.openai.com/docs/api-reference/embeddings/create
コード
import glob
import os
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
import json
import openai
import concurrent.futures
import tiktoken
def get_embedding(text, engine):
client = openai.OpenAI()
encoding = tiktoken.encoding_for_model("text-embedding-ada-002") # to avoid error for new model
tokens = encoding.encode(text)
if len(tokens) > 8191:
shrink_ratio = (8191 / len(tokens)) * 0.9
shrink_len = int(len(text) * shrink_ratio)
text = text[:shrink_len]
embedding = client.embeddings.create(input=[text], model=engine)
return embedding.data[0].embedding
def load_dataset(n_skip, embedding_engine="text-embedding-ada-002"):
categories = sorted([x for x in glob.glob("ldcc-20140209/text/*") if os.path.isdir(x)])
all_data = []
for category_ind, category in enumerate(categories):
files = sorted([x for x in glob.glob(category + "/*") if os.path.isfile(x) and "LICENSE" not in x])
for file in files:
with open(file, "r", encoding="utf-8") as fp:
lines = fp.read().replace("\r\n", "\n").split("\n")
item = {
"title": lines[0],
"date": lines[1],
"title": lines[2],
"content": "\n".join(lines[3:]),
"category_name": os.path.basename(category),
"category": category_ind
}
all_data.append(item)
# Get Embedding
with concurrent.futures.ThreadPoolExecutor(max_workers=50) as executor:
all_data = list(executor.map(lambda x: {**x, "embedding": get_embedding(x["content"], embedding_engine)}, all_data))
# Train, Test split
train_data, test_data = train_test_split(all_data, test_size=0.2, random_state=42, shuffle=True)
X_train, y_train = [x["embedding"] for x in train_data], [x["category"] for x in train_data]
X_test, y_test = [x["embedding"] for x in test_data], [x["category"] for x in test_data]
# Skip to reduce train dataset
X_train, y_train = X_train[::n_skip], y_train[::n_skip]
return X_train, y_train, X_test, y_test
def run_test(n_skip, embedding_engine="text-embedding-ada-002"):
X_train, y_train, X_test, y_test = load_dataset(n_skip, embedding_engine=embedding_engine)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Train
model = LogisticRegression(random_state=42, max_iter=1000)
model.fit(X_train, y_train)
# Test
y_pred = model.predict(X_test)
result = {
"n_skip": n_skip,
"embedding_engine": embedding_engine,
"n_train": X_train.shape[0],
"n_test": X_test.shape[0],
"train_accuracy": model.score(X_train, y_train),
"test_accuracy": model.score(X_test, y_test)
}
print(n_skip)
print(embedding_engine)
print("Train Accuracy :", result["train_accuracy"])
print("Test Accuracy :", result["test_accuracy"])
print("n_train :", result["n_train"])
print(X_train.shape)
return result
def main():
skips = [200, 100, 50, 25, 10, 5, 2, 1]
engines = ["text-embedding-ada-002", "text-embedding-3-small", "text-embedding-3-large"]
results = []
for engine in engines:
for skip in skips:
results.append(run_test(skip, embedding_engine=engine))
with open("result.json", "w", encoding="utf-8") as fp:
json.dump(results, fp, indent=4, ensure_ascii=False, separators=(",", ": "))
if __name__ == "__main__":
main()
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー