
「Patches Are All You Need?」のからくりを読み解く

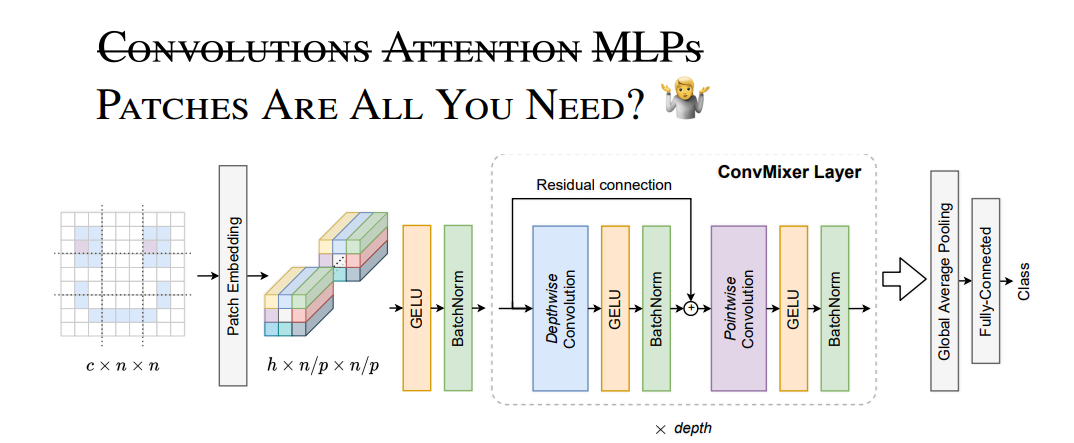
ICLR2022のレビューとして投稿された「Patches Are All You Need?」という論文が気になったので読んでみて、少し試してみました。画像の高周波の成分の活用や、スループットと精度のトレードオフが見えてくる興味深い論文でした。
目次
論文の概要
Transformerっぽいモデルを従来のConvolutionを使って再現したところ、Transfomerベースのモデルよりも精度も計算効率も良かった。
Patches Are All You Need?
https://openreview.net/forum?id=TVHS5Y4dNvM
※図はこちらの論文からの引用です
パラメーター数 vs 精度の比較
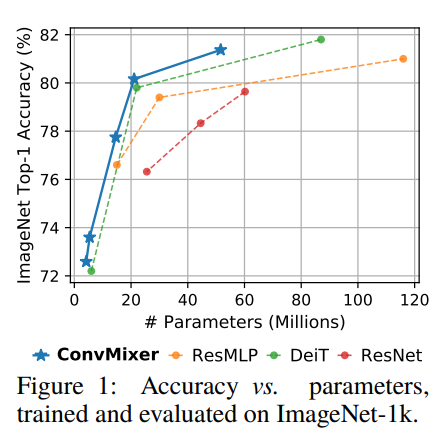
ConvMixerがこの論文、ResMLPは、DeiTはそれぞれ既存の研究でTransfomerからの発想を受けて作られたもの。ResNetは非Transfomerで従来のConvolutionベースのCNNです。
モデルの発想
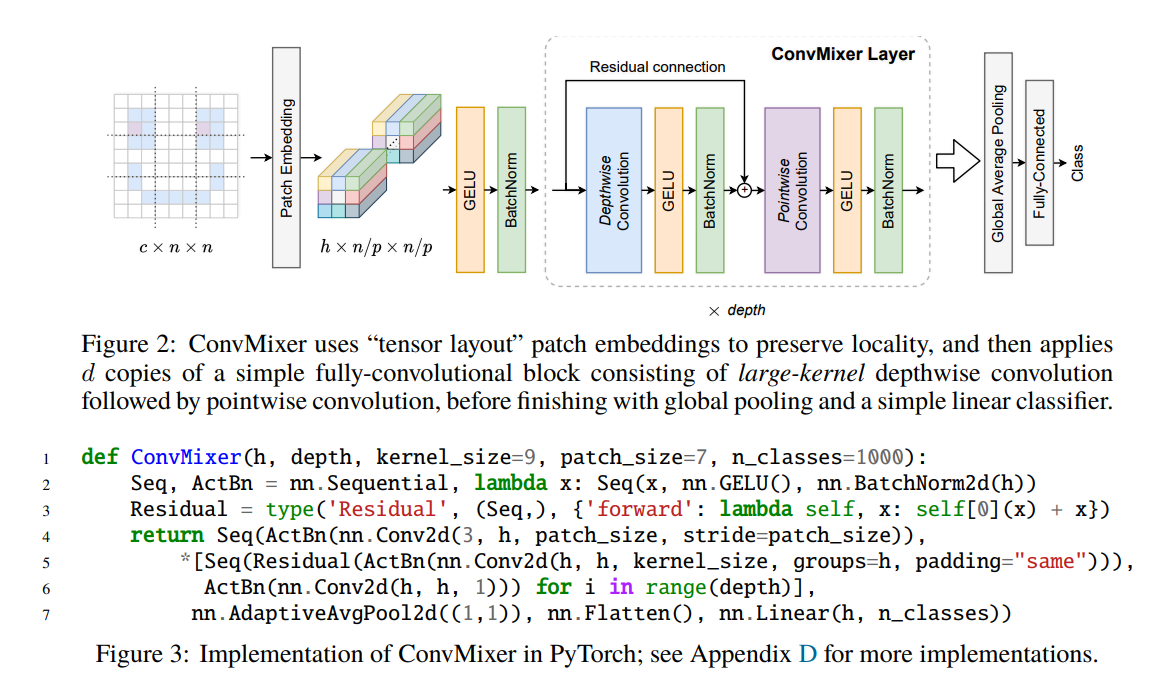
最初にパッチを取ってあとはResNet-likeなことをするというもの。最初にパッチを取るのがTransfomerっぽいです。
最初はテンソルをReshape等してパッチを作るのかなと思ったのですが(そこに技術的なキモがあるのかと思った)、どうもそれは違ったようです。ただ単に大きなStrideとカーネルでConv2Dを取ることをパッチと呼んでいました。図の中の
nn.Conv2d(3, h, patch_size, stride=patch_size)
と書かれている部分がパッチの生成です。これだけ見ると従来のCNNと変わらないんじゃと思うかもしれませんが、その続きが変わっています。
Residual(ActBn(nn.Conv2d(h, h, kernel_size, groups=h, padding="same")))
と書かれている部分ですね。よくあるCNNはgroupsを指定しないので、Group Convを全部のレイヤーにおいて使っているのが特徴です。Group convをすることで、TransfomerのMulti Head Attentionっぽいことをしようという発想だと思います。
さらに興味深いのがCNNでありがちな、ダウンサンプリングがないという点です。CNNでは中間層に適宜Poolingや、StrideのあるConvをはさみますが、そういったものがそういったものがないのが特徴です。Transfomerだと当たり前なのかもしれませんが、従来のCNNから見たら変わっているなーという印象を受けます。
要点
この通りの特徴をまとめると以下の通りでしょうか。
- 最初の層で大きめのカーネルとストライドでConv2Dを取るのをパッチと呼んでいる
- Group Conv中心のConv2Dを多用する
- 最初の層以外でダウンサンプリングをしない
コードを見てみる
この論文はレビュー段階でコードが公開されています。
https://github.com/tmp-iclr/convmixer
モデルはconvmixer.pyにあります。モデルがめちゃくちゃ簡単なのが良いです。
import torch.nn as nn
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x):
return self.fn(x) + x
def ConvMixer(dim, depth, kernel_size=9, patch_size=7, n_classes=1000):
return nn.Sequential(
nn.Conv2d(3, dim, kernel_size=patch_size, stride=patch_size),
nn.GELU(),
nn.BatchNorm2d(dim),
*[nn.Sequential(
Residual(nn.Sequential(
nn.Conv2d(dim, dim, kernel_size, groups=dim, padding="same"),
nn.GELU(),
nn.BatchNorm2d(dim)
)),
nn.Conv2d(dim, dim, kernel_size=1),
nn.GELU(),
nn.BatchNorm2d(dim)
) for i in range(depth)],
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),
nn.Linear(dim, n_classes)
)
https://github.com/tmp-iclr/convmixer/blob/main/convmixer.py
論文ではCIFAR-10の検証もしていました。
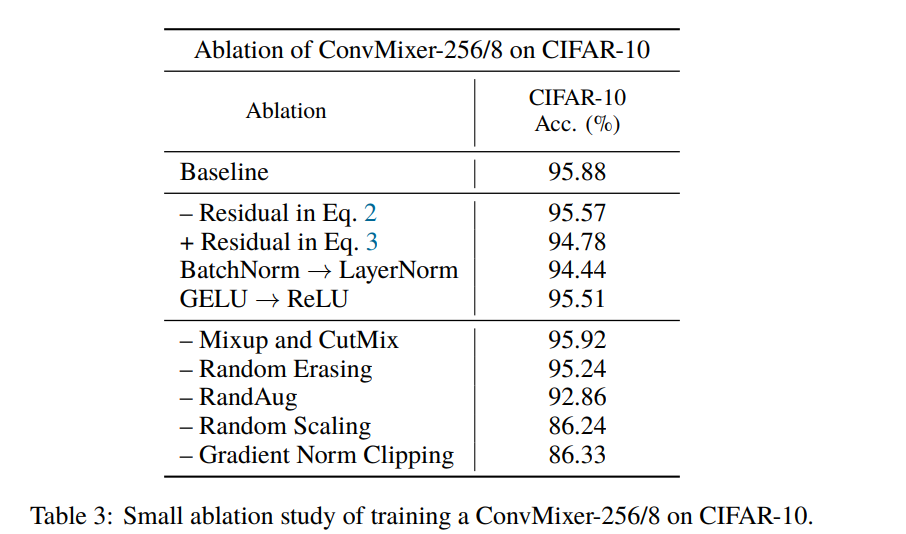
ベースラインで95.88%出ているの高いなと思いますが、Mixup+CutMix+Random Easing+Rand Aug+Random ScalingというData Augmentationゴリゴリに押しているのがベースラインです。ここで使っているのがConvMixer-256/8というものなのでtorchinfoで見てみましょう。
from torchinfo import summary
if __name__ == "__main__":
model = ConvMixer(256, 8, kernel_size=9, patch_size=1, n_classes=10)
summary(model, (128, 3, 32, 32))
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
Sequential -- --
├─Conv2d: 1-1 [128, 256, 32, 32] 1,024
├─GELU: 1-2 [128, 256, 32, 32] --
├─BatchNorm2d: 1-3 [128, 256, 32, 32] 512
├─Sequential: 1-4 [128, 256, 32, 32] --
│ └─Residual: 2-1 [128, 256, 32, 32] --
│ │ └─Sequential: 3-1 [128, 256, 32, 32] 21,504
│ └─Conv2d: 2-2 [128, 256, 32, 32] 65,792
│ └─GELU: 2-3 [128, 256, 32, 32] --
│ └─BatchNorm2d: 2-4 [128, 256, 32, 32] 512
├─Sequential: 1-5 [128, 256, 32, 32] --
│ └─Residual: 2-5 [128, 256, 32, 32] --
│ │ └─Sequential: 3-2 [128, 256, 32, 32] 21,504
│ └─Conv2d: 2-6 [128, 256, 32, 32] 65,792
│ └─GELU: 2-7 [128, 256, 32, 32] --
│ └─BatchNorm2d: 2-8 [128, 256, 32, 32] 512
├─Sequential: 1-6 [128, 256, 32, 32] --
│ └─Residual: 2-9 [128, 256, 32, 32] --
│ │ └─Sequential: 3-3 [128, 256, 32, 32] 21,504
│ └─Conv2d: 2-10 [128, 256, 32, 32] 65,792
│ └─GELU: 2-11 [128, 256, 32, 32] --
│ └─BatchNorm2d: 2-12 [128, 256, 32, 32] 512
├─Sequential: 1-7 [128, 256, 32, 32] --
│ └─Residual: 2-13 [128, 256, 32, 32] --
│ │ └─Sequential: 3-4 [128, 256, 32, 32] 21,504
│ └─Conv2d: 2-14 [128, 256, 32, 32] 65,792
│ └─GELU: 2-15 [128, 256, 32, 32] --
│ └─BatchNorm2d: 2-16 [128, 256, 32, 32] 512
├─Sequential: 1-8 [128, 256, 32, 32] --
│ └─Residual: 2-17 [128, 256, 32, 32] --
│ │ └─Sequential: 3-5 [128, 256, 32, 32] 21,504
│ └─Conv2d: 2-18 [128, 256, 32, 32] 65,792
│ └─GELU: 2-19 [128, 256, 32, 32] --
│ └─BatchNorm2d: 2-20 [128, 256, 32, 32] 512
├─Sequential: 1-9 [128, 256, 32, 32] --
│ └─Residual: 2-21 [128, 256, 32, 32] --
│ │ └─Sequential: 3-6 [128, 256, 32, 32] 21,504
│ └─Conv2d: 2-22 [128, 256, 32, 32] 65,792
│ └─GELU: 2-23 [128, 256, 32, 32] --
│ └─BatchNorm2d: 2-24 [128, 256, 32, 32] 512
├─Sequential: 1-10 [128, 256, 32, 32] --
│ └─Residual: 2-25 [128, 256, 32, 32] --
│ │ └─Sequential: 3-7 [128, 256, 32, 32] 21,504
│ └─Conv2d: 2-26 [128, 256, 32, 32] 65,792
│ └─GELU: 2-27 [128, 256, 32, 32] --
│ └─BatchNorm2d: 2-28 [128, 256, 32, 32] 512
├─Sequential: 1-11 [128, 256, 32, 32] --
│ └─Residual: 2-29 [128, 256, 32, 32] --
│ │ └─Sequential: 3-8 [128, 256, 32, 32] 21,504
│ └─Conv2d: 2-30 [128, 256, 32, 32] 65,792
│ └─GELU: 2-31 [128, 256, 32, 32] --
│ └─BatchNorm2d: 2-32 [128, 256, 32, 32] 512
├─AdaptiveAvgPool2d: 1-12 [128, 256, 1, 1] --
├─Flatten: 1-13 [128, 256] --
├─Linear: 1-14 [128, 10] 2,570
==========================================================================================
Total params: 706,570
Trainable params: 706,570
Non-trainable params: 0
Total mult-adds (G): 91.14
==========================================================================================
Input size (MB): 1.57
Forward/backward pass size (MB): 9126.82
Params size (MB): 2.83
Estimated Total Size (MB): 9131.21
==========================================================================================
パラメーターは論文のAppendixから取りました。CIFAR-10ではパッチサイズを1にするのが良いそうです。見ての通り、縦横解像度が32のレイヤーがずらーっと並んでいるのが見て取れます。
「こんな大きな解像度でConvを取ったら、いくらGroup Convを使っているとはいえ、計算量やばいだろうな」と思いたくなります。事実、Mult-addsが91.14GやForward/backward passのサイズが9126.82MBは、この深さのCIFAR-10のモデルにしては大きいです。これはどういったことがおきるかというと、
- mult-addsが多い→Convolutionの計算量が多い→1エポックあたりの訓練や推論の時間がかかる(スループットの低下)
- メモリ消費量が多い→GPUがOut of memoryになりがち(要求GPUのスペックの上昇)
事実自分のGPUでCIFAR-10を訓練したところ、バッチサイズ64で1エポック158秒もかかりました。バッチサイズ128だとOOMになってしまいました。普通のCNNだとこんなに時間もメモリもいらないんですけどね。
このモデルが精度出るっていうのは理解できます。なぜかというと、CNNのPoolingはローパスフィルターなので、それを入れないということは、ローパスフィルターで捨ててしまっている画像の高周波の成分を活用できているということです。Transfomer前のCNN、特に生成モデルでは「高周波の成分が復元できないよね」ということは言われていました。音声合成のモデルにも似たような問題はあるそうです。つまり、ダウンサンプリングを極力しない:高周波の成分を活かすことで、計算量やメモリとトレードオフで精度を取るというのがこの論文のからくりだと思います。
パラメーター数だけではモデルを評価できない
コンピュータービジョンの論文だと、縦軸に精度を取って横軸にパラメーター数を取るとり、モデルの良し悪しを評価するというグラフをよく目にします。この論文でも最初の図がそうでした。
しかし、この評価は必ずしも正確ではないです。なぜかというと、ダウンサンプリングをしなくて、解像度が高い状態でチャンネル数を少なくしてConvを取れば、パラメーター数を少なくして精度を上げることができるからです(ある意味チート?)。このケースではMult-addsが非常に大きくなるが、パラメーター数は少なくなります。したがって、本当に計算量と精度のトレードオフを評価したければ、パラメーター数vs精度の他に、スループットやMult-addsやメモリ消費量vs精度のグラフを取るべきです。
ただ、この論文ではスループットについて言及しているのが良いです。良いところだけではなくて悪いところも書いている論文というのは個人的には好きです。
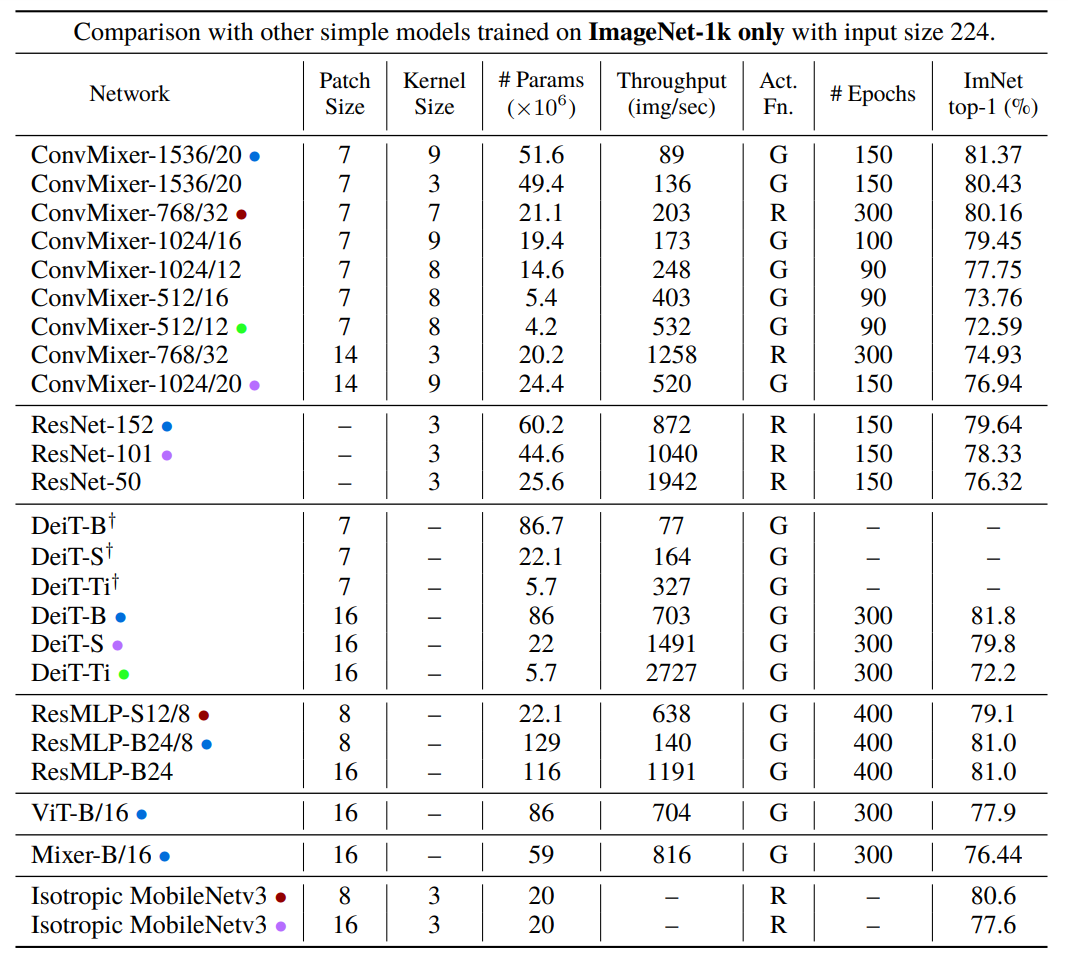
これはImageNetでの比較ですが、「Throughput」というところに注目しましょう。この値は高いほうが良いです。古臭そうなResNetでもスループットで見れば、Transfomerベースのモデルよりも優秀です。スループットの高いTransfomerのモデルは精度が犠牲になっていることが多いです。
Transfomerの論文をあまり呼んだことないのでなんとも言えませんが、もしかして、今流行っているTransfomerって、特に画像では単にスループットを犠牲にして精度を上げているだけだったりするのでしょうか。高周波の成分の活用や、パッチを取るとの発想は面白いので、ここらへんが最適化できていったら面白いかなと思いました。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー