
PDFMinerを並列化して読み込みを高速化する


PDFMinerというMITライセンスで利用できる、PythonベースのPDFパーサーを並列化する方法を紹介します。このライブラリ、パースが遅いというデメリットがあるのですが、並列化が効果的な場合もあります。
目次
はじめに
PDFMinerというPythonベースのPDF読み取りライブラリがあります。MITライセンスで利用できて大変便利なのですが、遅いというデメリットがあります。
https://github.com/pdfminer/pdfminer.six
PyMuPDFを使うと圧倒的に早くなるのですが、AGPLライセンスというデメリットがあります。特にAGPLでも気にしなくていいという場合は、普通にPyMuPDFを使うのがいいと思います。
https://pymupdf.readthedocs.io/en/latest/
今回はPDFMinerを使いつつ、並列化の力技でゴリ押しして高速化する方法です。Pythonベースでなくていいなら(別途バックエンド建てる)なら他言語のライブラリを使うなども普通に考えられるでしょう。
並列化の考え方
PDFファイルのまま並列化して読み込むと競合してエラーになってしまうので、メモリにマッピングして並列処理させます。
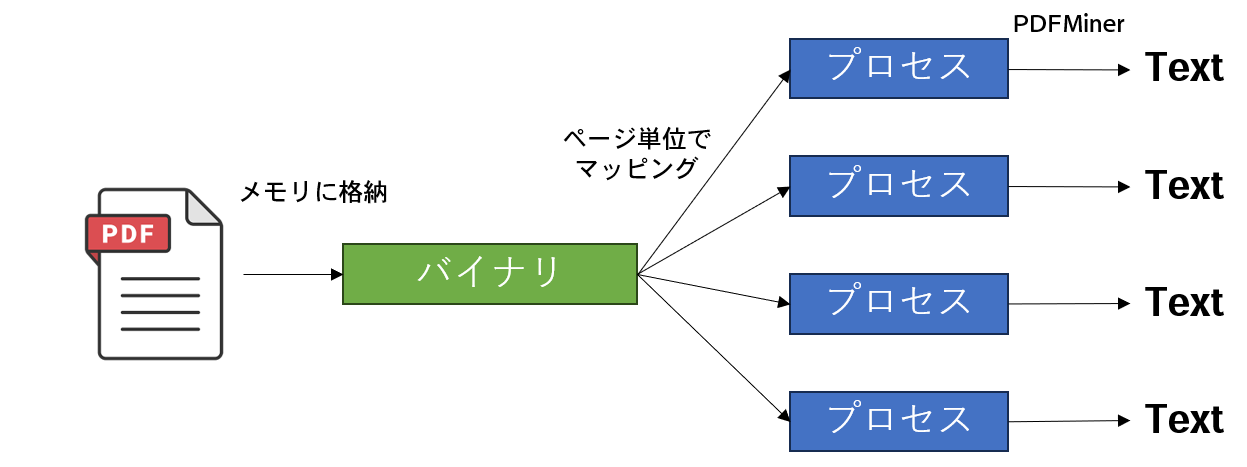
PDFMinerでページ単位で読み込む方法は、公式コードにかかれています。
https://pdfminersix.readthedocs.io/en/latest/tutorial/composable.html
並列化コード
結果はこちらになります。以下のファイルで実験しました
- 経済産業省の「通商白書2023」全文 333P
- トヨタ自動車有価証券報告書 2023年3月期 241P
import io
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfinterp import resolve1
import concurrent.futures
import time
def get_page_text(binary: bytes, page_num: int):
with io.BytesIO(binary) as file_buf:
with io.StringIO() as output_string:
rsrcmgr = PDFResourceManager()
device = TextConverter(rsrcmgr, output_string, laparams=LAParams())
interpreter = PDFPageInterpreter(rsrcmgr, device)
page = list(PDFPage.get_pages(file_buf, pagenos=[page_num]))[0]
interpreter.process_page(page)
return output_string.getvalue()
def parse_pdf(filename: str, max_worker=8):
with open(filename, 'rb') as in_file:
binary = in_file.read()
parser = PDFParser(in_file)
doc = PDFDocument(parser)
max_pages = resolve1(doc.catalog['Pages'])['Count']
# Multi Process Mapping
buf_iterator = [binary for i in range(max_pages)]
page_iterator = list(range(0, max_pages))
with concurrent.futures.ProcessPoolExecutor(max_workers=max_worker) as executor:
result = list(executor.map(get_page_text, buf_iterator, page_iterator))
return result
def main():
start_time = time.time()
parse_pdf(filename="zentai.pdf", max_worker=16)
print(time.time() - start_time)
if __name__ == "__main__":
main()
Corei9-9900KのCPUで実験した結果です(8コア16スレッド)。PDFMinerのバージョンは20221105です。
| 並列化なし | 8プロセス並列 | 16プロセス並列 | |
|---|---|---|---|
| 通商白書2023(333P) | 68.33 | 39.45 | 30.94 |
| トヨタ自動車有価証券報告書 2023年3月期(241P) | 34.27 | 84.94 | 71.70 |
通商白書の場合は順当に高速化しましたが、有価証券報告書の場合は逆に遅くなりました。早くなるケースもあれば遅くなるケースもあるそうです。
これだけが方法じゃないと思いますが、PDFMiner縛りでいきたい!というときの力技としてはありではないでしょうか。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー