
CLIPに対していろいろ条件を変えてLoRAを訓練してみた(PyTorch Lightning)


CLIPに対してLoRAを適用して、いろいろ条件を変えて画像分類モデルを訓練した。Few-shotやパラメーター数に対しては従来のファインチューニングと同じだが、rとαとバランスを考慮する必要がある。LoRAだとゼロショット性を維持できるため、In-domainとOut-of-domainのトレードオフを示すことができた。
目次
やること
PyTorch Lightningでいろいろ条件を変えて、CLIPのLoRAを訓練してみる。
- モデル:
openai/clip-vit-base-patch32 - データセット:FGVCAircraft
OpenAIのCLIP ViT-B/32にLoRAを適用し、画像分類の精度を比較。
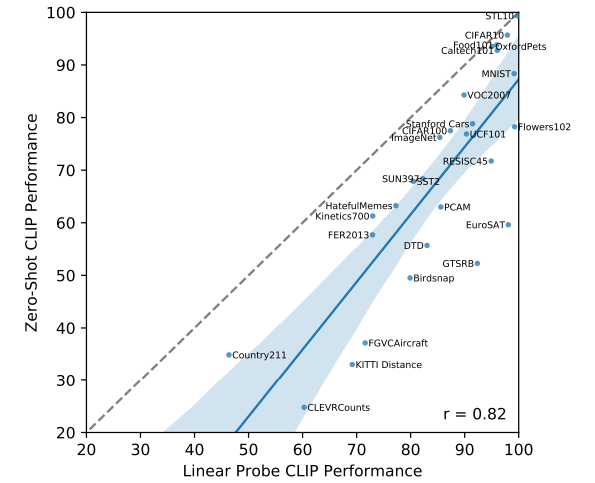
オリジナルのCLIPより。FGVCAircraftはCLIPだともともと精度が出にくいデータセット。ただし、これは実験で使うモデルより大きめのモデルの設定でかつプロンプトエンジニアリングをしているので、実験で出てくるゼロショット性能はより低い。
実験条件
- Few-shot性能
- 訓練データを減らしたときにどの程度精度が変わるのか
- 訓練データを本来のサイズより「100, 50, 20, 10, 5, 2, 1分の1」とする。1分の1は本来のサイズと同じ
- 訓練データが多いほどLoRAの精度は上がるはず
- LoRAのパラメーターサイズを変える
- r=αの比率を伴ったまま、rとαの値を変える
- rはパラメーター数に効き、αはパラメーター数には直接関係ない。αはスケーリング値に寄与し、LoRAの効きの強さをコントロールする。
- 「α/r」の値がLoRAにおけるスケーリングで、この比率を維持する。参考情報
- r=αを「8、16、32、64」と変化させる。この値が大きいほどパラメーターのサイズが大きくなる
- 訓練中のrとαの比率を変えて、LoRAの効きの強さを変える
- rとαの比率を変えると、スケーリング値を変えられるので、訓練結果が変わるかもしれない
- r=64で固定し、αを「16、32、64、128、256」と変える
- LoRAを適用する場所を変える
- CLIPのモデル全体ではなく、Text Modelのみ、Vision Modelのみといったかけかたをする
- LoRAは基本的にAttentionにかけるが、
k_proj, v_proj, q_proj, out_projのみといった書け方をする
- 推論時のαを変える
- Stable DiffusionのLoRAは推論時の強さをコントロールすることで、絵柄の汎用性と特化性をコントロールするという実運用が広く行われている。これがCLIPでも通用するのかを調べる
- 具体的には、r=64, α=64で訓練したモデルに対し、推論時のみαの値を変える
- 推論時のαを変えて、In-domain(AirCraft)のデータセット、Out-of-domainのデータセットに対する精度を評価する。Out-of-domainのデータセットとして、Flowes102データセットを使用。
PyTorch lightningでの実装
LoRAのかける場所を変える際の訓練コードはこちら
import os
import torch
from torch import nn
from torchvision import datasets
import pytorch_lightning as pl
from torch.utils.data import DataLoader, Subset
from peft import LoraConfig, get_peft_model
from transformers import CLIPModel, CLIPProcessor
import torchmetrics
from pytorch_lightning.callbacks import ModelCheckpoint
from pytorch_lightning.loggers import CSVLogger
import numpy as np
from weakref import proxy
class AircraftDataModule(pl.LightningDataModule):
def __init__(self, batch_size=32, subset_ratio=1, data_dir="data"):
super().__init__()
self.batch_size = batch_size
self.subset_ratio = subset_ratio
self.data_dir = data_dir
self.processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
def clip_transform(self, image):
return self.processor(images=image, return_tensors="pt").pixel_values.squeeze(0)
def setup(self, stage=None):
np.random.seed(42)
self.aircraft_train = datasets.FGVCAircraft(root=self.data_dir, download=True, split="train", transform=self.clip_transform)
self.aircraft_train = Subset(self.aircraft_train,
np.random.choice(len(self.aircraft_train), int(len(self.aircraft_train) // self.subset_ratio), replace=False))
self.aircraft_val = datasets.FGVCAircraft(root=self.data_dir, download=True, split="val", transform=self.clip_transform)
class_name_path = os.path.join(self.data_dir, "fgvc-aircraft-2013b", "data", "variants.txt")
with open(class_name_path, "r") as fp:
self.class_names = [line.strip() for line in fp.read().splitlines()]
def train_dataloader(self):
return DataLoader(self.aircraft_train, batch_size=self.batch_size, shuffle=True, num_workers=2)
def val_dataloader(self):
return DataLoader(self.aircraft_val, batch_size=self.batch_size, num_workers=2)
def print_trainable_parameters(model):
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param:.2f}"
)
# CLIPにLoRAを適用するためのクラス
class CLIPWithLoRA(pl.LightningModule):
def __init__(self, aircraft_data_module, r, alpha, target_modules, learning_rate=1e-4):
super().__init__()
self.aircraft_data_module = aircraft_data_module
self.learning_rate = learning_rate
self.target_modules = target_modules
self.clip = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
self.processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
self.r = r
self.alpha = alpha
# loss metric
self.criterion = nn.CrossEntropyLoss()
self.train_accuracy = torchmetrics.Accuracy("multiclass", num_classes=len(self.aircraft_data_module.class_names))
self.val_accuracy = torchmetrics.Accuracy("multiclass", num_classes=len(self.aircraft_data_module.class_names))
# LoRAレイヤーの適用
self.apply_lora()
def apply_lora(self):
config = LoraConfig(
r=self.r,
lora_alpha=self.alpha,
target_modules=self.target_modules,
lora_dropout=0.1,
bias="none",
modules_to_save=["classifier"],
)
self.lora_model = get_peft_model(self.clip, config)
def forward(self, inputs):
return self.lora_model(**inputs)
def training_step(self, batch, batch_idx):
text_inputs = self.processor(text=self.aircraft_data_module.class_names, return_tensors="pt", padding=True)
text_inputs = {k: v.to(self.device) for k, v in text_inputs.items()} # move inputs to device
inputs = {**text_inputs, "pixel_values": batch[0]}
outputs = self.forward(inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
loss = self.criterion(logits_per_image, batch[1])
self.log('train_loss', loss, on_step=True, on_epoch=True, prog_bar=True, logger=True)
self.train_accuracy.update(logits_per_image, batch[1])
self.log('train_acc', self.train_accuracy, on_step=True, on_epoch=True, prog_bar=True, logger=True)
return loss
def validation_step(self, batch, batch_idx):
text_inputs = self.processor(text=self.aircraft_data_module.class_names, return_tensors="pt", padding=True)
text_inputs = {k: v.to(self.device) for k, v in text_inputs.items()} # move inputs to device
inputs = {**text_inputs, "pixel_values": batch[0]}
outputs = self.forward(inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
self.val_accuracy.update(logits_per_image, batch[1])
self.log('val_acc', self.val_accuracy, on_step=True, on_epoch=True, prog_bar=True, logger=True)
def on_validation_epoch_end(self):
# 各エポックの終わりに検証精度をリセット
self.val_accuracy.reset()
def on_train_epoch_end(self):
# 各エポックの終わりに訓練精度をリセット
self.train_accuracy.reset()
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=self.learning_rate)
def train_dataloader(self):
return self.aircraft_data_module.train_dataloader()
def val_dataloader(self):
return self.aircraft_data_module.val_dataloader()
class LoRACheckpoint(ModelCheckpoint):
def _save_checkpoint(self, trainer: pl.Trainer, filepath: str) -> None:
# trainer.save_checkpoint(filepath, self.save_weights_only)
trainer.lightning_module.lora_model.save_pretrained(filepath) # 保存するモデルのパスを指定
self._last_global_step_saved = trainer.global_step
self._last_checkpoint_saved = filepath
# notify loggers
if trainer.is_global_zero:
for logger in trainer.loggers:
logger.after_save_checkpoint(proxy(self))
def run_train(target_modules, cnt):
# # ["k_proj", "v_proj", "q_proj", "out_proj"]
aircraft_data_module = AircraftDataModule(batch_size=64, subset_ratio=1)
aircraft_data_module.setup()
model = CLIPWithLoRA(aircraft_data_module, 64, 64, target_modules, learning_rate=1e-4)
csv_logger = CSVLogger(save_dir="log_positions", name=f"lora_{cnt}")
print_trainable_parameters(model.lora_model)
checkpoint_callback = LoRACheckpoint(
monitor='val_acc', # モニターするメトリクス
filename='model-{epoch:02d}-{val_acc:.2f}',
save_top_k=1, # 保存するトップkモデルの数
mode='max', # 'max'は検証精度が最大のときに保存
)
trainer = pl.Trainer(
max_epochs=20,
accelerator="gpu",
devices=[1],
callbacks=[checkpoint_callback],
logger=csv_logger
)
trainer.fit(model)
def main():
conditions = [
r"text_model.*(?:out_proj)$",
r"text_model.*(?:k_proj|v_proj)$",
r"text_model.*(?:k_proj|v_proj|q_proj)$",
r"text_model.*(?:k_proj|v_proj|q_proj|out_proj)$",
r"vision_model.*(?:out_proj)$",
r"vision_model.*(?:k_proj|v_proj)$",
r"vision_model.*(?:k_proj|v_proj|q_proj)$",
r"vision_model.*(?:k_proj|v_proj|q_proj|out_proj)$",
r".*(?:k_proj|v_proj|q_proj|out_proj)$"
]
for cnt, cond in enumerate(conditions):
print("Conditions : ", cond)
run_train(cond, cnt)
if __name__ == "__main__":
main()
基本的には通常のPyTorch Lightningと書き方は一緒。モデルの読み込み、保存周りを独自に定義する必要がある。保存は、既存のチェックポイントの保存のコールバックをオーバーライドすると良い。
結果
Few-shot性能
Train Split数が少ない(使うデータ数が多い)ほうが、精度の高い結果になった。これは従来のファインチューニングと同じ。
| Train Split | Val Accuracy |
|---|---|
| 100 | 19.32% |
| 50 | 19.74% |
| 20 | 24.96% |
| 10 | 27.48% |
| 5 | 32.01% |
| 2 | 43.38% |
| 1 | 53.71% |
LoRAのRの値を変える
Rの値が大きい(LoRAのモデルパラメーターが多い)ほうが、精度が高い結果となった。これも従来のファインチューニングと同じ。
| R Value | Val Accuracy |
|---|---|
| 8 | 48.60% |
| 16 | 49.56% |
| 32 | 51.19% |
| 64 | 53.71% |
- スケーリングを同一にするため、Rとαは同時に変動させる。R=16ではα=16、R=32ではα=32
LoRAのRとαの比率を変える
αを大きくするほど精度が良くなった。
| α Value | Val Accuracy |
|---|---|
| 16 | 50.14% |
| 32 | 50.47% |
| 64 | 53.71% |
| 128 | 55.57% |
| 256 | 56.35% |
- Rは64で固定
なお、rが固定でαを変えた場合の、パラメーター数は変化がない。
# データセット分割, r, αの順
1 64 256
trainable params: 7864320 || all params: 159141633 || trainable%: 4.94
1 64 128
trainable params: 7864320 || all params: 159141633 || trainable%: 4.94
1 64 64
trainable params: 7864320 || all params: 159141633 || trainable%: 4.94
1 64 32
trainable params: 7864320 || all params: 159141633 || trainable%: 4.94
1 64 16
trainable params: 7864320 || all params: 159141633 || trainable%: 4.94
LoRAの訓練中は、「α/r」でスケーリングされるので、αが大きい=訓練中のLoRAの効きが強いことを示す。少し強めにかけてあげたほうが対象のデータセットに対する精度は良くなるそうだ。
今回、学習率が1e-4とやや低めだったので、学習率をもう少し高めにするとこの結果は変わるのかもしれない。
LoRAのかける場所を変える
peftのライブラリでは、LoRAをつける場所を正規表現で指定可能(参考)。r”text_model.*(?:k_proj|v_proj|q_proj)$”,は、Text Model内のk_proj, v_proj, q_projのいずれかに対してLoRAを適用するもの。
結果は明瞭で、Text ModelとVision Modelの両方にかけたほうが精度が良かった。このケースでは単体だったら、Text ModelよりVision Modelのほうが効きが良い。
| LoRA Position | Val Accuracy | Trainable params | Trainable% |
|---|---|---|---|
| r”text_model.*(?:out_proj)$” | 41.70% | 786,432 | 0.52 |
| r”text_model.*(?:k_proj|v_proj)$” | 42.36% | 1,572,864 | 1.03 |
| r”text_model.*(?:k_proj|v_proj|q_proj)$” | 42.06% | 2,359,296 | 1.54 |
| r”text_model.*(?:k_proj|v_proj|q_proj|out_proj)$” | 43.62% | 3,145,728 | 2.04 |
| r”vision_model.*(?:out_proj)$” | 44.10% | 1,179,648 | 0.77 |
| r”vision_model.*(?:k_proj|v_proj)$” | 46.29% | 2,359,296 | 1.54 |
| r”vision_model.*(?:k_proj|v_proj|q_proj)$” | 44.73% | 3,538,944 | 2.29 |
| r”vision_model.*(?:k_proj|v_proj|q_proj|out_proj)$” | 46.44% | 4,718,592 | 3.02 |
| r”.*(?:k_proj|v_proj|q_proj|out_proj)$” | 52.78% | 7,864,320 | 4.94 |
- r=α=64で固定
この精度向上は結局パラメーター数で説明できるのだが、両者にかけたほうが効きが良いというのはわかりやすい結果。
推論時のαを変えて分布外のデータセットで推論する
このLoRAを使った手法の良い点は、ゼロショット性を維持しつつ、特定のドメインのデータに特化できる点。その例として、訓練データに使ったFGVCAircraft(In-domainデータ)と、訓練データでは全く使っていないFlowers102(Out-of-domainデータ)の精度を比較する。
- α=0のケース:LoRAが全く効いていない。ゼロショットのCLIPと同じ
- αを大きくする:LoRAの効きが強くなっていく。訓練時のαと同じのときが最もIn-domainの性能が良くなる。
- αをあまりに大きくする:LoRAの効きが強すぎて精度が急速に悪化する。これはStable DiffusionでLoRAを強くかけすぎると画像が崩壊するのと同じアナロジーで考えられる。
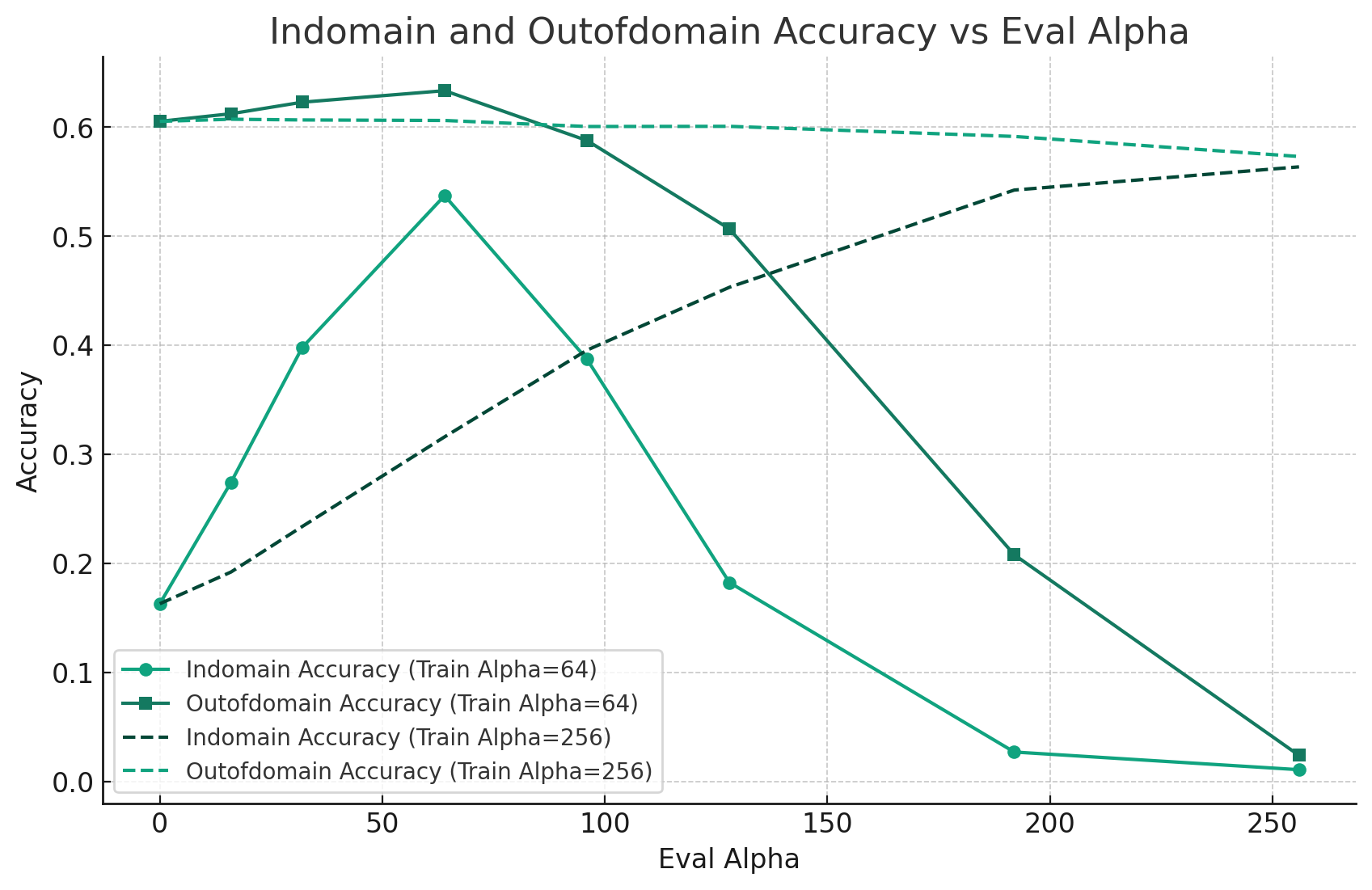
| Train Alpha | Eval Alpha | Indomain_Accuracy | Outofdomain_Accuracy |
|---|---|---|---|
| 64 | 0 | 16.29% | 60.51% |
| 64 | 16 | 27.42% | 61.21% |
| 64 | 32 | 39.78% | 62.27% |
| 64 | 64 | 53.71% | 63.33% |
| 64 | 96 | 38.70% | 58.76% |
| 64 | 128 | 18.24% | 50.66% |
| 64 | 192 | 2.70% | 20.78% |
| 64 | 256 | 1.08% | 2.39% |
| 256 | 0 | 16.29% | 60.51% |
| 256 | 16 | 19.20% | 60.71% |
| 256 | 32 | 23.37% | 60.64% |
| 256 | 64 | 31.59% | 60.60% |
| 256 | 96 | 39.54% | 60.04% |
| 256 | 128 | 45.30% | 60.06% |
| 256 | 192 | 54.22% | 59.13% |
| 256 | 256 | 56.35% | 57.29% |
- r=64で固定
興味深いのは、訓練時のα(Train Alpha)が64の場合は、仮に推論時のAlphaを上げたとしてもOut-of-domainの精度がやや増加するという点。これは研究でもときどき報告されているが、AirCraftのデータから有用な特徴を学習した結果、他タスクの精度が上がったというものであると考えられる。
一方でこの現象は、訓練時のαが256の場合(r=64、α=256)は観測できずに、Out-of-domainの精度がIn-domainの精度とトレードオフになるというわかりやすい結果になった。この理由は推測ではあるが、αが低いほうがきめ細やかな訓練がされて、潜在空間が滑らかになるのではないかと考えられる。αを上げてしまえば、未学習にはなりにくくなり、In-domainの精度の精度は上がるのだが、荒っぽい訓練になり、潜在空間の滑らかさが失われるのではないかと思われる。αを上げてLoRAを強くかけて訓練すれば良いというものでもなさそうだ。
推論時にαを変えてロードするには?
PEFTでは用意されていないので、保存済み係数のディレクトリを一時ファイルにコピーし、JSONを書き換えてロードする。
from transformers import CLIPModel, CLIPProcessor
from peft import PeftModel
import tempfile
import shutil
import glob
import os
import json
def load_peft_model(model, alpha=16):
original_path = "./logs/lora_aircraft_1_64_256/version_0/checkpoints/model-epoch=15-val_acc=0.56.ckpt"
with tempfile.TemporaryDirectory() as tmp_dir:
# copy the original checkpoint to the temporary directory
all_files = glob.glob(f"{original_path}/*")
for file in all_files:
shutil.copy2(file, tmp_dir+"/"+os.path.basename(file))
# replace config
with open(f"{tmp_dir}/adapter_config.json", "r") as f:
config = json.load(f)
config["lora_alpha"] = alpha
with open(f"{tmp_dir}/adapter_config.json", "w") as f:
json.dump(config, f, indent=2, separators=(',', ': '), ensure_ascii=False)
model = PeftModel.from_pretrained(model, tmp_dir)
return model
結論
- Few-shot性能
- 従来のファインチューニングと同じで、LoRAでも精度とデータ数が比例
- LoRAのパラメーター数(rを増やす)
- 従来のファインチューニングと同じで、パラメーター数と精度が連動
- rとαの比率を変える(r:αの比率を変える)
- αを大きくしたほうが、訓練中のLoRAの効きが強くなり学習速度は速くなると思われるが、Out-of-domainでの精度が犠牲になったり代償はある
- LoRAを適用する場所を変える
- できるだけ複数のレイヤー、複数のモデルにかけたほうが精度が上がる
- 推論時のαを変える
- 推論時のαを変えることで、Stable Diffusionのように、In-domainとOut-of-domainの精度のトレードオフができる。学習時のαが極端に高くないと、トレードオフにならずに、LoRAを適用したとしてもOut-of-domainの精度が少し上がることがある
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー