
ResNetをKeras(TensorFlow, MXNet)、Chainer、PyTorchで比較してみる


前からディープラーニングのフレームワークの実行速度について気になっていたので、ResNetを題材として比較してみました。今回比較するのはKeras(TensorFlow、MXNet)、Chainer、PyTorchです。ディープラーニングのフレームワーク選びの参考になれば幸いです。今回のコードはgithubにあります。
https://github.com/koshian2/ResNet-MultipleFramework
目次
実験
CIFAR-10をResNetで分類。設定は本家の論文をほぼ踏襲。
| 出力サイズ | 32×32 | 16×16 | 8×8 |
|---|---|---|---|
| レイヤー数 | 1+2n | 2n | 2n |
| フィルター数 | 16 | 32 | 64 |
論文ではnのサイズを3,5,7,9と変えて実験していましたが、それを4つのフレームワークで動かして確かめます。全体のレイヤー数は6n+2で表され、n=9の場合は54層となります。フィルター数が少ないこともあってそこまで時間はかからないです。
結果
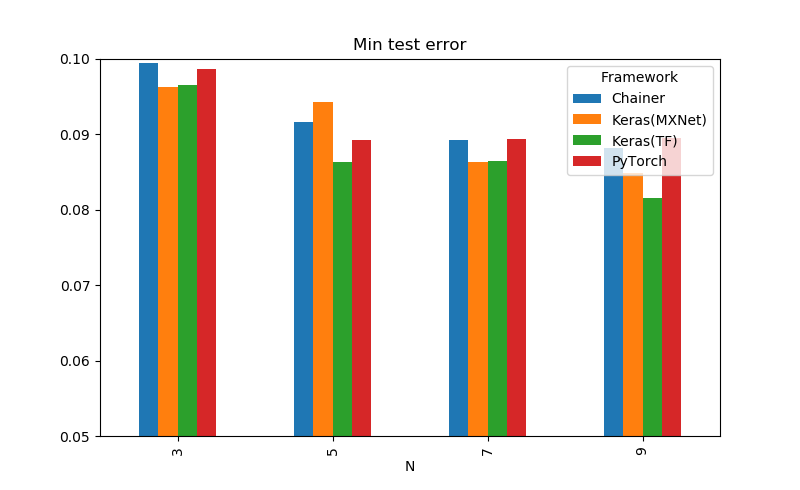
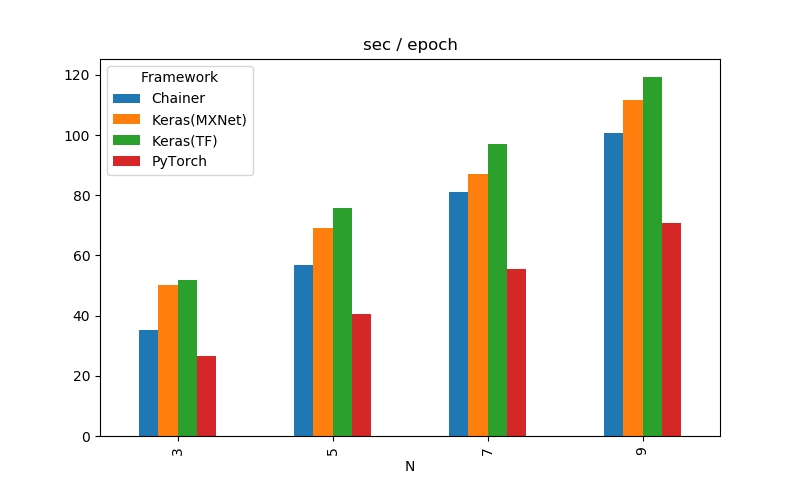
| Framework | N | # Layers | MinTestError | s / epoch |
|---|---|---|---|---|
| Keras(TF) | 3 | 20 | 0.0965 | 51.817 |
| Keras(MXNet) | 3 | 20 | 0.0963 | 50.207 |
| Chainer | 3 | 20 | 0.0995 | 35.360 |
| PyTorch | 3 | 20 | 0.0986 | 26.602 |
| Keras(TF) | 5 | 32 | 0.0863 | 75.746 |
| Keras(MXNet) | 5 | 32 | 0.0943 | 69.260 |
| Chainer | 5 | 32 | 0.0916 | 56.854 |
| PyTorch | 5 | 32 | 0.0893 | 40.670 |
| Keras(TF) | 7 | 44 | 0.0864 | 96.946 |
| Keras(MXNet) | 7 | 44 | 0.0863 | 86.921 |
| Chainer | 7 | 44 | 0.0892 | 80.935 |
| PyTorch | 7 | 44 | 0.0894 | 55.465 |
| Keras(TF) | 9 | 56 | 0.0816 | 119.361 |
| Keras(MXNet) | 9 | 56 | 0.0848 | 111.772 |
| Chainer | 9 | 56 | 0.0882 | 100.730 |
| PyTorch | 9 | 56 | 0.0895 | 70.834 |
PyTorchが頭一つ抜けて速い、TensorFlowのKerasとchainerが精度面では安定してそうです。速度はほぼこれで確定、精度は1回だけなのでガチャ運次第なところがあってなんともいえないです。
補足
だいたい本家の論文を踏襲しているものの、一部異なります。
ネットワークの構成
- ResudialBlockの構成が本家ではなく、pre-act ResNetと同じ
- ダウンサンプリングは本家同様Poolingではなくstride=2のConv2Dを使っているが、その際にカーネルサイズは1×1の畳み込みとしている
学習関係
- 学習の長さが本家より短縮して100epochで終わり。本家は64000周回(だいたい180epoch)
- 本家と同様にモメンタムありSGDを使っている。モメンタムの値は0.9。ただし初期学習率は本家が0.1だが、今回は0.01としている。なぜなら0.1にすると発散してしまったため。
- 学習率は本家同様、全体の50%で1/10、全体の75%でさらに1/10にしている
- 各条件とも1回のみ試行
データ関係
- フレームワーク間で処理を統一するために、チャンネルごとの標準化はなし(今振り返るとできたかもしれない)
- DataAugmentationはいつもの(左右4ピクセルpadding+32×32のランダムクロップ)
学習環境
- Google ColabのGPUを使用。Tesla K80
- PyTorchのみDataLoaderを4並列化、cuDNNのベンチマークモードをON(これが効いてる)
- MXNetではCUDA8.0、ChainerではCuPy8.0をインストール。MXNetのCUDA9.0を使おうとするとエラー出てしまった。
- ライブラリのバージョンは以下の通り
| Library | Version |
|---|---|
| TensorFlow | 1.10.1 |
| Keras | 2.1.6 |
| mxnet-cu80 | 1.2.1 |
| Keras-mxnet | 2.2.2 |
| Chainer | 4.4.0 |
| cupy-cuda80 | 4.4.0 |
| PyTorch | 0.4.1 |
| Torchvision | 0.2.1 |
さて、フレームワークごとに結果を細かく見ていきましょう。
Keras(TensorFlowバックエンド)
どうもいつもお世話になっています。速度面では最遅となっていまいましたが、それを引き換えにしても有り余る書きやすさと保守のしやすさが売り。日本企業が作っているChainerが公式の日本語ドキュメントがないのに、なぜか外国人が作っているKerasが公式日本語ドキュメントあるという不思議な事態。公式の日本語ドキュメントがほしい人は、日本語ドキュメント作る気のない日本企業にだまされないでKeras使いましょう(一応Chianerには日本語ドキュメントありますが、有志が作ったものです)。
あとデフォルトで出してくるプログレスバーが結構かっこよくてディープラーニング始めたばっかりの人は「ディープラーニングやってるすげええ」感が味わえるのが売り。こういう細かいところが嬉しい。結構ポイント抑えていててこの表示使いやすい。
そして肝心の結果です。
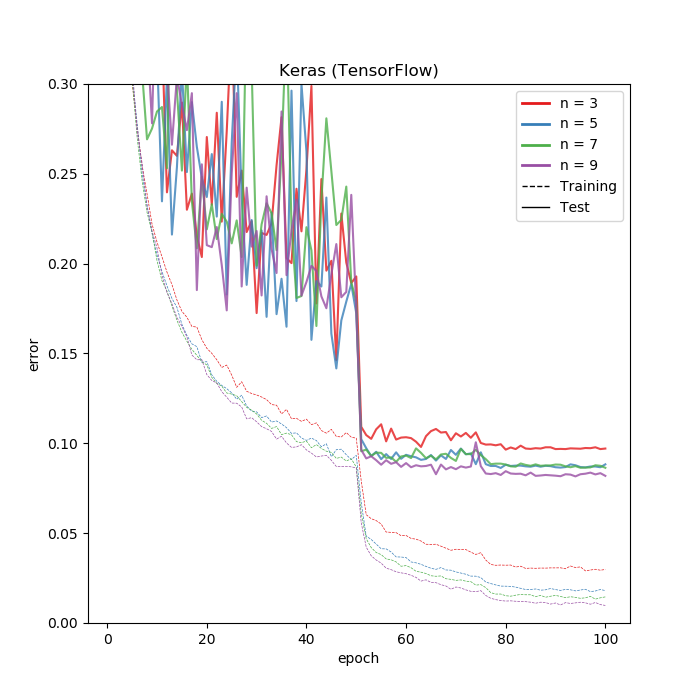
KerasはWeightDecay(正則化)をレイヤー単位に入れるので、他のフレームワークよりももしかしたら正則化が強く働いているのかもしれません。Kerasの結果だけよく見えるのはおそらくこれが理由だと思われます。他のフレームワークは大抵オプティマイザーにWeightDecayを入れるのでKerasだけ特殊かもしれません。
逆に言えば他のフレームワークでチューニングしたハイパーパラメータをKerasに導入するときは、WeightDecayのみ気をつける必要がありそうです。ドロップアウトやDataAugumentationなどは特に問題ないと思います。
Keras(MXNetバックエンド)
Amazonが開発を進めているMXNetバックエンドのKeras。TensorFlowの遅さをカバーするための切り札(?)として開発が進められています。書き方はTensorFlowがバックエンドのときとほとんど同じで、KerasAPIは共通なので全くと言っていいほど一緒です。
「ほとんど」と言ったのはTensorFlowバックエンドがデフォルトでchannels_lastであるのに対して、MXNetバックエンドはchannels_firstのみになります。そのため、Convレイヤーでdata_formatを指定したり、BatchNormでaxisを明示的に指定したり、めんどくさく普段気にしない所に留意する必要があります。
今回の結果ではTensorFlowバックエンドよりも、気持ち(1割未満)速い程度でしたが、AWSLabの主催者発表によると、「P3.8X Large」インスタンスでResNet50-CIFAR10をすると、TFよりも1.6倍近く速くなるそうです。今回エラーがあってCUDA9.0ではなくCUDA8.0を使ったのと、Google ColabがTesla K80という比較的旧式のGPUであるのが大きいかもしれませんが、おそらく最新鋭のGPUを使っているであろうAWSの石油王専用インスタンスを使うと、ちゃんと効果が出るそうです。石油王の方はぜひ確かめてください。
結果は以下の通りです。
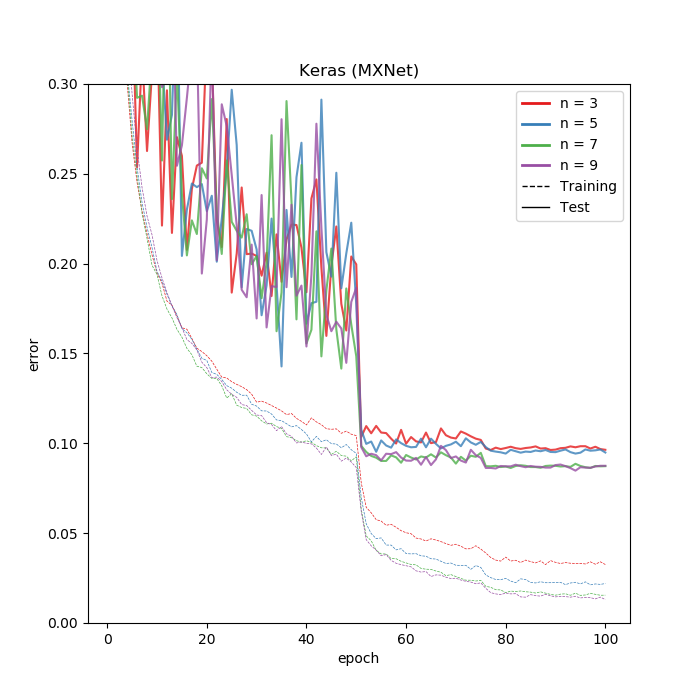
TensorFlowバックエンドのほうが若干訓練、テストとも良さそうに見えますが、1回きりなので正直誤差と言えなくもないです。
もっと明らかにMXNetのほうが速くなる例を見つけられれば楽しいと思います。まだ公式のKerasにマージされていないので開発中と見るべきでしょう。これからに期待です。今の所は特に理由なければTensorFlowバックエンドで、興味があればMXNetバックエンドを使ってみてもいいと思います。
追記:Google ColabのTPU対応により、TensorFlow、KerasがColab最速となりました。詳しくはこちらをご覧ください。
Chainer
さて、KerasがDefine-and-runであったのに対し、ここからのChainerとPyTorchはDefine-by-runになります。Define-and-runは定義した時点でモデルがガッチリと固まってしまうため、条件分岐して動的にレイヤーを追加することが比較的難しくなります。実際、Kerasでモデル構造に限らず動的な分岐を作ろうと思ったら、テンソル演算やらないといけないのでちょっと辛くなるorできることが狭まるような気配はあります。ただこれは結構マニアックなことなので、普通にディープラーニングエンジョイするだけならまず考える必要はありません。Chainerはそんなエンジョイ勢とは裏腹のとても硬派なフレームワークです。
どのぐらい硬派かというと、日本企業が作っているのに「日本語ドキュメントは甘え。英語マニュアルを熟読すべし」という玄人○向リスペクトスタイルです。Chainerのロゴの真ん中にサングラス男入れても違和感ないと思います。しかもその英語ドキュメントも、あまりサンプルコードが載ってなくて(PyTorchはほんといっぱい載っています)なかなか硬派な仕様です。PFNの人は自分とはIQが200ぐらい違う天才ばっかりなので、多分天才の人はあれで理解できるのかなと思います。Define-by-runのフレームワークを今回はじめて使いましたが、IQ2ぐらいの自分はPyTorchよりもChainerのほうがはるかに理解に時間かかりました。
そのため、githubからえろい人が作ったモデルをコピペ写経してくるのが一番習得に速い気がします。写経は古事記の時代から続く日本の素晴らしい伝統なので、ぜひ仏教の修行にあやかり徳を積みましょう。DataAugmentationもChianer側でほとんど用意してくれないので写経にはうってつけですね。
さて真面目な話に戻すと、Chainerの訓練部分はtrianerをextendして書くことで簡潔に書けるようにしてあるのですが、これが少し特殊な書き方なので慣れが必要です。訓練のプログレス表示に残り時間推定してくれるのがいいですね。
では結果です。
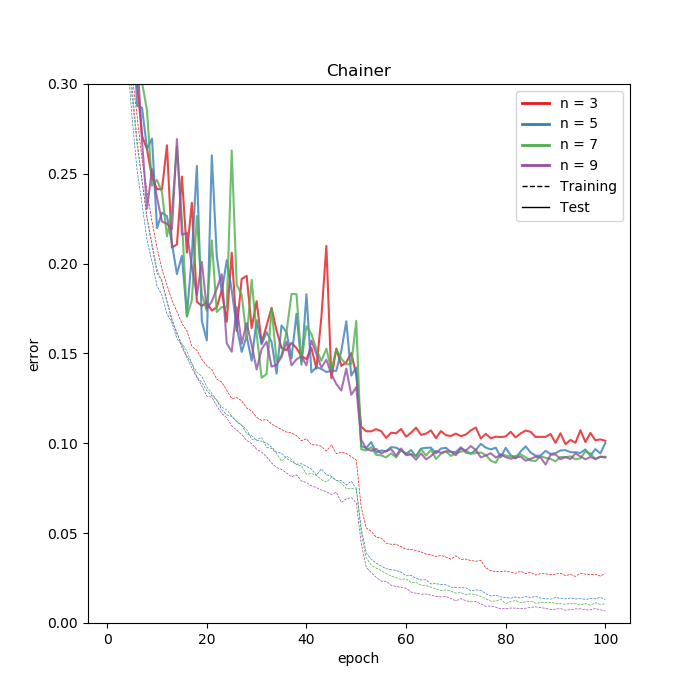
学習率を落とす前までは、Kerasよりもかなり安定して学習が進んでいますね。振れ幅が少ないです。最終的なテストエラーを見ると、数値が同じでも若干PyTorchよりもオーバーフィッティングしているように見えます。偶然かもしれませんし、理由はよくわかりません。
時間のほうはN=3のときはPyTorch並に速かったものの、モデルが深くなるにつれKerasより若干速いぐらいに落ち着いてしまいました。速さについてはColabの環境ではかなり中途半端な結果になってしまいました。
PyTorch
去年あたりから彗星のごとく現れた期待のエース。新しい研究がどんどん実装されて最短で試せるのが売りらしい(でも研究で一番多いのって多分生のTensorFlowだよね?)。Chainerと同じDefine-by-runであるものの、書き方によってはKerasに近い書き方もできていい感じに分かりづらいところをラップしてくれています。ただtrainとvalidationの関数は、自分で書かないといけないので最初は戸惑うかもしれません。そこは写経力を活用すると、なるほどーとなります。
公式チュートリアルが英語ながらものすごくしっかりしていてわかりやすいです。「arXivの論文100本斬りしてやるぜヒャッハー!」なんて息巻いているディープラーニングモヒカンにとっては多分朝飯前だと思います。ドキュメントにもサンプルコードありますし、自分で試しながらやりやすく理解しやすいです。StackOverFlowライクのコミュニティーもあって、ハマったらググると大抵これが出てきます。英語のStackOverFlowや、Githubのissue読める人ならなんてこともないと思います。
TensorとNumpy配列の行き来が簡単で(torch.from_numpyですぐテンソル化できる)、細かい処理を自分で実装するときに便利なんじゃないかなと思います。ここはKerasよりも全然直感的な感じはします。
自分がColabで実験した限りでは最速のフレームワークとなりました。訓練時間はKerasの6割程度。10時間が9時間程度になってもうーんという感じですが、10時間が6時間になったらさすがに目を見張るものがあります。もっと速くなればいいなー。
さて結果です。
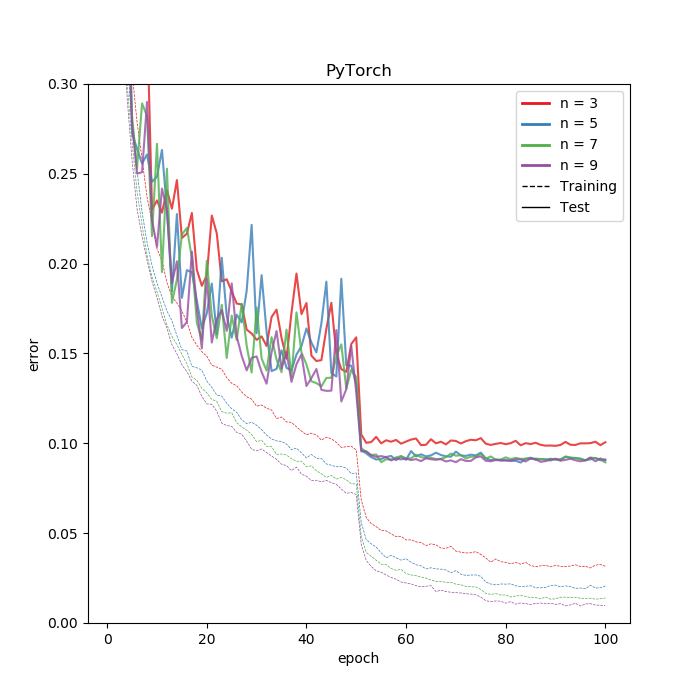
Chainerとほとんど似ているものの悪くはなさそう。Kerasがレイヤー単位でWeightDecayかけるのに対して、PyTorchがオプティマイザーに対してかけるので、おそらく正則化のスケールが変わると思われます。したがって、PyTorchでやるときはKerasより気持ちWeightDecayの正則化を強めにかけたほうがいい結果が出るはずです。これはWeightDecay限定の話なので、DropoutやShake-shakeを使う場合はまた変わるのではないかと思います。
まとめ
ResNetの実験を通じてKeras(TensorFlow、MXNet)、Chianer、PyTorchの4つのフレームワークを見てきましたが、Google Colabでの最速はPyTorchとなりました。これを踏まえてフレームワーク選びを考えると自分は次のように考えます。
追記:ColabのTPU対応により、最速の座をKerasとTensorFlowに明け渡すことになりました。PyTorchのTPU対応が待たれます。
初心者にはKeras(TensorFlow)がおすすめ
なんといっても書きやすいし(コードの行数が少なくて済む)、とりあえず動くレベルのもの作るのはプログラミング初心者でもできます。生のTensorFlowを勧めている本やサイトもありますが、あれは初めて自動車を運転をする人がMTから入るようなものなので、背景の理論の理解と同時にやろうとするとハングアップしてしまうと思います。自動車が動けばいいならATでいいですよね。
Kerasは便利な反面、初めての人がディープラーニングの理論を理解していないで使うとブラックボックス化してしまいがちなので、書きやすい代償として理論的な部分を理解するように努力してください。理論的な部分は他のフレームワーク行ったときでも使えますので。もし理論的な部分を理解したければ生のTensorFlowではなくNumpyベースで書いてみるといいかもしれません。多層パーセプトロンぐらいなら普通に書けます(遅いけど)。
追記:ColabのTPU対応により、実は初心者でも上級者でもKerasではないかという説が出てきました。ただTPU版はまだ若干バグあるので(例えばLearningRateSchedulerがTPUだと動かない)、安定化が待たれます。
Kerasが物足りなくなってきたらPyTorchがおすすめ
だんだんKerasに慣れてくると、速度面や拡張面で不満が出てくるかもしれません。特にモデルをいくつも訓練してると速度面での改善が欲しくなります。そんなときはPyTorchがおすすめです。なんと言っても速いし、Define-by-runなのでモデルのカスタマイズの幅が広がります。
ただ初心者がいきなりPyTorchで入ってしまうのは、やるなとは言いませんがあまりおすすめしません。Kerasよりもマニュアルで書く部分が多いので最初だと混乱してしまうと思います。今回やったResNetの場合だと、コードの行数はKeras<Chainer<PyTorchでした。
以上です。皆様のフレームワーク選びの参考になれば幸いです。
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー