
論文まとめ:SAM 2: Segment Anything in Images and Videos


- タイトル:SAM 2: Segment Anything in Images and Videos
- 著者:Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, Christoph Feichtenhofer(Meta AI)
- 論文URL:https://arxiv.org/abs/2408.00714
- GitHub:https://github.com/facebookresearch/segment-anything (Apache 2.0)
- デモ:https://sam2.metademolab.com/demo
目次
ざっくりいうと
- 画像と動画の両方でプロンプトを用いてあらゆる対象物をセグメンテーションできるモデル「SAM 2」。過去の情報を活用するストリーミングメモリー機構を導入。
- 新たに大規模な動画セグメンテーションデータセット「SA-V」を構築し、モデルの性能評価と公平性評価を行った。
- 評価の結果、SAM 2は既存の手法よりも高精度かつ高速であり、画像セグメンテーション能力も向上。
論文要約:Gemini1.5 Pro
SAM 2: Segment Anything in Images and Videos
https://arxiv.org/abs/2408.00714
・この論文において解決したい課題は何?
画像と動画両方において、プロンプトを用いてあらゆる対象物をセグメンテーションできる基盤モデルを開発すること。
・先行研究だとどういう点が課題だった?
既存の動画セグメンテーションモデルやデータセットは、「動画内のあらゆるものをセグメントする」能力が不足しており、アノテーションは特定のオブジェクトクラスに偏っている。また、インタラクティブな動画セグメンテーション手法は、トラッカーの性能に依存したり、モデルの誤りを修正する際に再アノテーションが必要となるなど、柔軟性に欠ける。
・先行研究と比較したとき、提案手法の独自性や貢献は何?
- 画像と動画の両方に対応する統合モデル SAM 2 を提案。
- 過去の予測とプロンプト情報を記憶するストリーミングメモリー機構を導入し、動画全体にわたるセグメンテーションとインタラクティブな修正を効率的に実現。
- 大規模な動画セグメンテーションデータセット SA-V を構築。
・提案手法の手法を初心者でもわかるように詳細に説明して
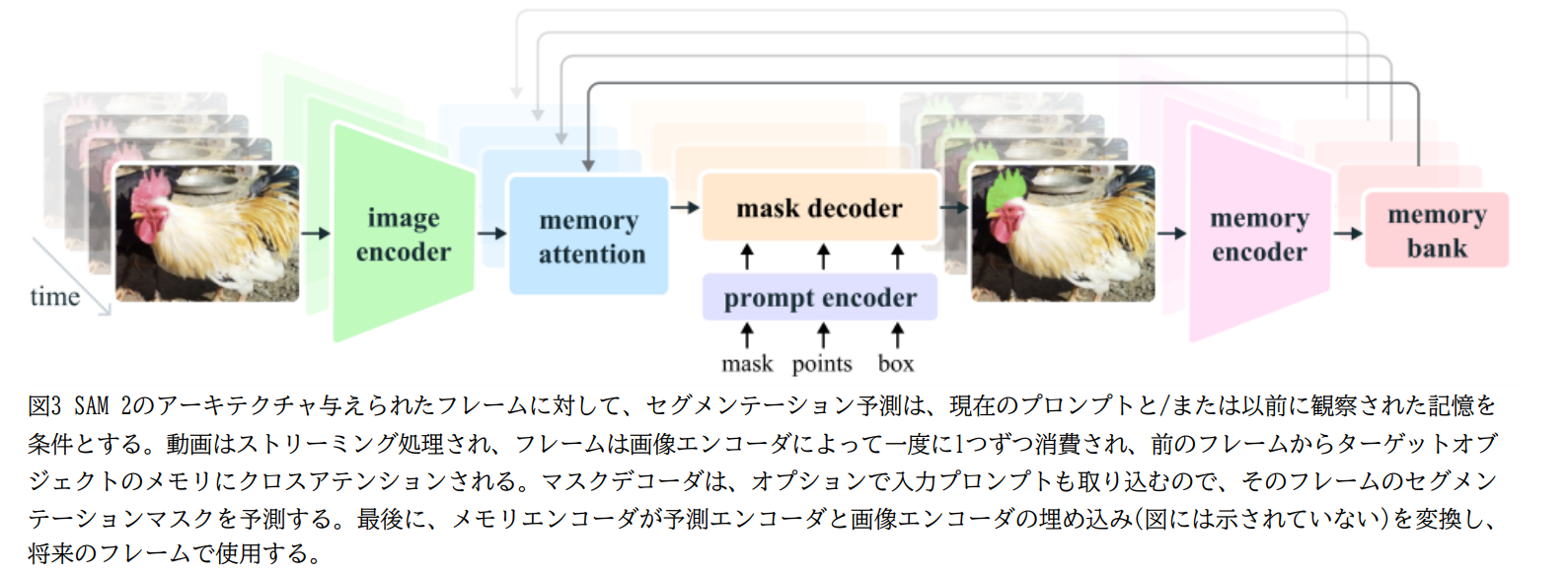
SAM 2 は、画像エンコーダー、メモリーアテンション、プロンプトエンコーダー、マスクデコーダー、メモリーエンコーダー、メモリーバンクで構成される。まず、画像エンコーダーが各フレームの特徴量を抽出する。メモリーアテンションは、過去のフレームの特徴量と予測、および新しいプロンプトに基づいて、現在のフレームの特徴量を調整する。プロンプトエンコーダーは、クリック、ボックス、マスクなどのプロンプトを処理し、マスクデコーダーは調整された特徴量とプロンプトからセグメンテーションマスクを予測する。メモリーエンコーダーは予測されたマスクとフレーム特徴量からメモリーを生成し、メモリーバンクに保存する。これにより、SAM 2 は動画全体にわたってオブジェクトを追跡し、過去の情報を活用してセグメンテーションを改善できる。
・提案手法の有効性をどのように定量・定性評価した?
- 9つの動画データセットを用いたインタラクティブな評価では、SAM 2 は既存手法より少ない操作回数で高精度なセグメンテーションを実現。
- 17の動画データセットを用いた従来の半教師ありVOS評価でも、SAM 2 は既存手法を凌駕。
- 37の画像データセットを用いた評価では、SAM 2 は SAM よりも高精度かつ高速なセグメンテーションを実現。
- SA-V データセットにおける公平性評価では、性別や年齢による性能差は最小限であることを確認。
・この論文における限界は?
- ショット変化や長時間のオクルージョン、類似した外観を持つオブジェクトの追跡が困難。
- 複数のオブジェクト追跡時にオブジェクト間の相互作用を考慮していない。
- データエンジンのアノテーション検証に人手が必要。
・次に読むべき論文は?
- Segment Anything (SAM) (Kirillov et al., 2023): SAM 2 の基礎となる画像セグメンテーションモデルについて詳しく知りたい場合。
- XMem++ (Bekuzarov et al., 2023) and Cutie (Cheng et al., 2023a): SAM 2 と比較された、最先端の動画オブジェクトセグメンテーションモデルについて理解を深めたい場合。
コード: https://github.com/facebookresearch/segment-anything-2
SAM1の違い
基本的に画像のみ。SAM2では動画に対応したのが大きな違い。画像に対するセグメンテーション能力も向上し、高速化を達成。
https://github.com/facebookresearch/segment-anything
- SAM2で追加されたSA-VデータセットをCC by 4.0で公開
- SAM1のデータセット(SA-1B)は研究利用のみ
→テーマ:画像オンリーのSAM1を動画領域への一般化する
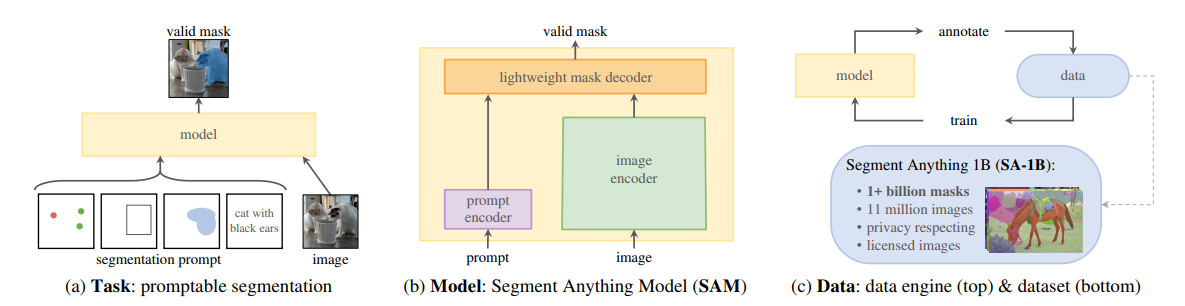
上がSAM1、下がSAM2
モデル詳細
- SAM2のデコーダーのフレーム埋込は、画像エンコーダーから直接ではなく、過去の予測やプロンプトのフレームの記憶を条件づけ。メモリバンクを使用
- 画像エンコーダー:過去の記憶に対して無条件のトークンを得るため。ストリーミングで一度だけ画像の特徴を取得。MAEで訓練されたHieraを使用
- プロンプトエンコーダー・マスクデコーダー:SAM1と同じ。インタラクティブセグメンテーションの使用で想定。プロンプトとフレームを双方向に更新
- デコーダーの設計:SAM1と同じ
- メモリバンク:直近N個のフレームをメモリに持つFIFOキュー
データセットの作成
- SAM1と同時に大規模な動画セグメンテーションデータを作成
- SAM1はアノテーションとモデルの訓練を同時交互に回し、だんだん人間の関与を減らしていく(Data Engineと呼ばれた)
SAM2のData Engine
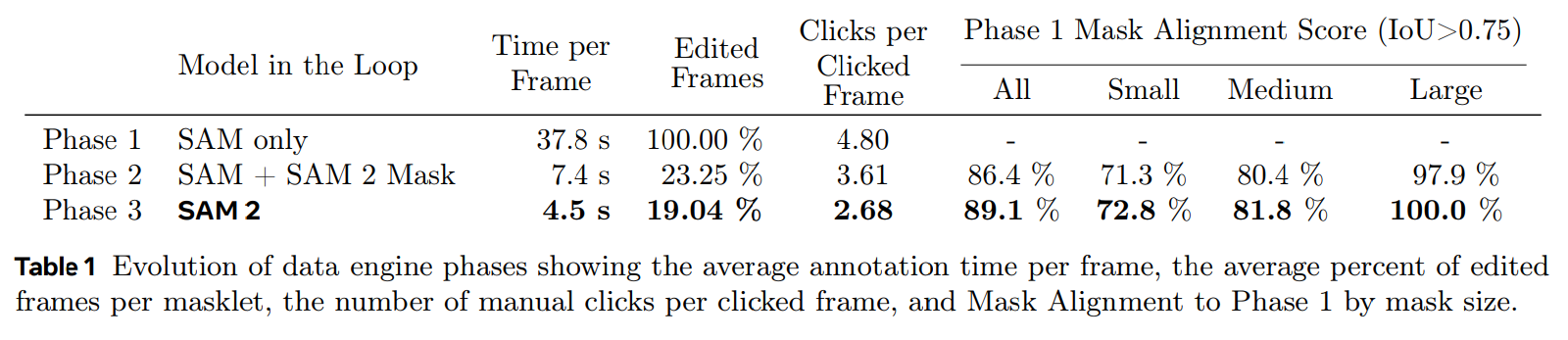
- フェーズ1:フレームごとのSAMをベースに人間がアノテーション。フレームあたりのアノテーション時間は平均37.8秒
- フェーズ2:SAM+SAM2のマスク。フェーズ1に対して時間の要素を伝播させて事前アノテーションの精度を上げ、ニ繧繝が修正。アノテーション時間は1フレームあたり平均7.4秒と5.1倍高速化
- フェーズ3:ポイントやマスクなど様々なタイプのプロンプトを受け入れるフルスペックのSAM2。人間は時々絞り込みのためのクリックを行うだけでいい。人間の関与はあるものの、アノテーションは1フレームあたり平均4.5秒に改善
-
アノテーションの高水準性を担保するために、マスクレット(マスクの候補)に対し品質保証のステップを追加。マスクレットに対し「満足」か「不満足か」(全フレームに対し、ターゲットのオブジェクトをトラッキングできているかどうか)の選別を行う
- これをベースにマスクレットの自動生成を行う。これは人間のアノテーションは、顕著なオブジェクトに重みをおくため、多様性を確保するために自動生成のものを追加している。
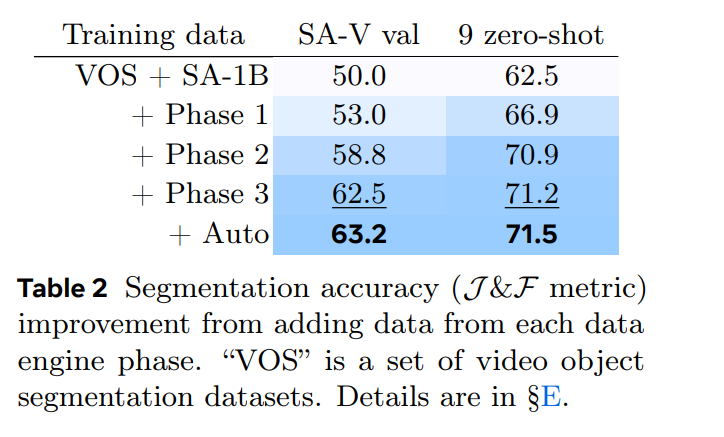
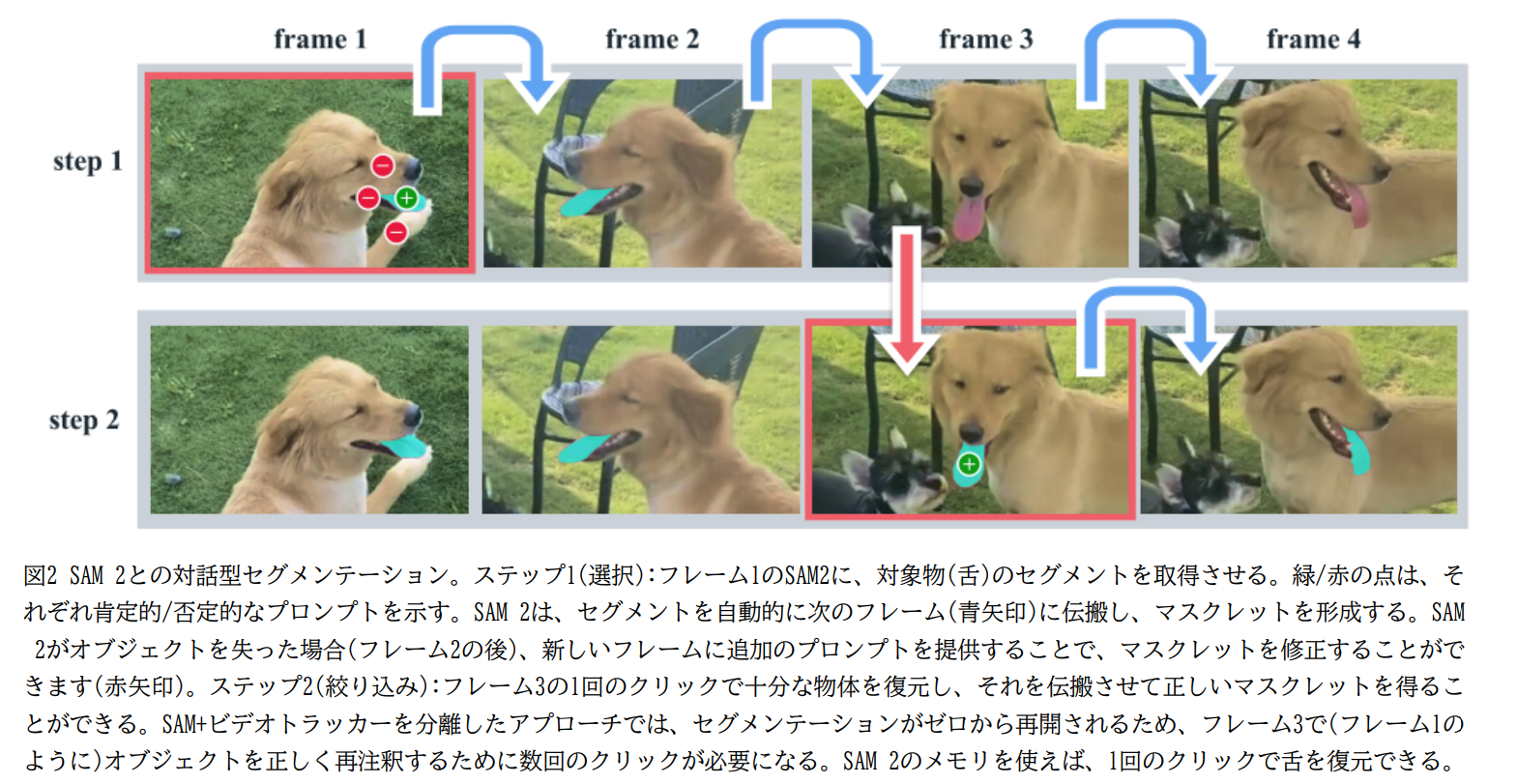
定量/定性評価
静止画の場合のSAM1との比較。Hieraが効いて純粋に速く強くなっている

動画の場合の比較。SAM1+他手法より強い

動画の定性比較。オクルージョンに強い

所感
つっよw SAM1の時点でも衝撃的だったのにさらにやばくなった
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー