
論文まとめ:An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion


- タイトル:An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
- 著者:Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, Daniel Cohen-Or
- 所属:テルアビブ大学、NVIDIA
- 論文リンク:https://arxiv.org/abs/2208.01618
- プロジェクトページ:https://textual-inversion.github.io/
ざっくり言うと
- 事前訓練された拡散生成モデルを使い、人間による言語記述なく、与えられた参照画像に対応する疑似単語「S*」を埋め込み空間上で探索し、画像生成に活用するための研究。
- 「S*」は人間が直接記述しないこと、DALL-E2のようなCLIP空間上の計算を直接行わないことで、細部がより表現できるようになった
- 「App icon of S*」とプロンプトで概念を踏襲することが可能で、画像生成のほか、スタイル変換、生成モデルのバイアス除去など下流アプリへの応用が期待できる
目次
お気持ち

- 矢印から左:事前学習済みtext-to-imageモデルの埋め込み空間から、特定の概念を表す新たな疑似単語を発見する
- 矢印右:疑似単語、新しい文章に合成することができ、ターゲットを新しいシーンに配置したり、スタイルや構成を変えたり、新しい製品に組み込める
著者たちのやりたいこと
- 特定の固有概念の画像を生成したり、その外観を変更したり、新しい役割や新しいシーンを構成したい
- 例:飼い猫を絵画にしたり、お気に入りのおもちゃから新しい商品を想像したり
- オブジェクトやスタイルなど、ユーザが提供したコンセプトの画像のみを用いて、凍結されたテキストから画像へのモデルの埋め込み空間において、新しい「言葉」によってそれを表現することを学習する
- ユニークで多様な概念を捉えるためには、単一の単語埋め込みで十分
導入
タイタニックの例
- タイタニックの有名なシーン「“…draw me like one of your French girls”」
- そのスタイルと構図がジャックの過去の作品の一部と一致すること、そして最後に「私」という一言で、この絵が特定の、ユニークな対象を描くものであることをローズは示しているのである。ローズ自身である。ローズは、このような広範かつ具体的なコンセプトを推論し、新しい作品に生命を吹き込むジャックの能力に信頼を寄せているのです。
これはまでの大規模なテキスト画像合成モデル
- ユーザーは未知の構図で新しいシーンを合成し、無数のスタイルで鮮明な画像を生成することができる。
- しかし、ユーザーがテキストによって対象を記述できる場合のみに制約された
- ローズの例のように、具体的な記述を伴いような要求に答えられなかった
大まかな流れ
事前に学習されたテキスト画像モデルのテキスト埋め込み空間から新しい単語を見つけることを提案。「テキスト反転」と呼んでいるが、やっていることはGAN反転に近い。
- 入力文字列がトークンの集合に変換
- 各トークンを埋め込みベクトルに置き換え、これらのベクトルをText Transformerに供給
- 目標は、新しい具体的な概念を表す新しい埋め込みベクトルを見つけること
関連研究
- Text-guided synthesis
- GANの文脈から広く研究されていた
- 近年の自己回帰モデルや拡散モデルにより素晴らしい結果が得られるようになった
- 条件付きモデルを訓練するのではなく、事前訓練されたジェネレーターの潜在空間を探索するものもある。CLIPなどが使われる
- 画像生成だけでなく、画像編集や、Domain Adaptation、動画合成や、3Dオブジェクトのテクスチャ合成に応用されている
- 本研究のアプローチ:ゼロから新しいモデルを訓練するのではなく、固定モデルの語彙を拡張
- 拡散モデルによる逆変換
- 拡散モデルは、ノイズ除去を連鎖的に行ってため、モデル構造上反転が可能
- しかし、このプロセスでは、画像の内容が大きく変化する傾向がある
- DDIM(Song et al., 2020)では、サンプリングプロセスを閉形式で反転させ、与えられた実画像を生成する潜在的ノイズマップを抽出できることを実証
- DALL-E 2 (Ramesh et al., 2022)では、DDIMをベースに画像編集を実証しているが、モデルの条件付けがCLIPベースに依存しているため、適用できないケースがある
- 既存の研究が、与えられた画像をモデルの潜在空間に変換するのに対し、この手法はユーザから提供された概念を変換する。さらに、この概念をモデルの語彙の新しい擬似単語として表現することで、より一般的で直感的な編集を可能にした
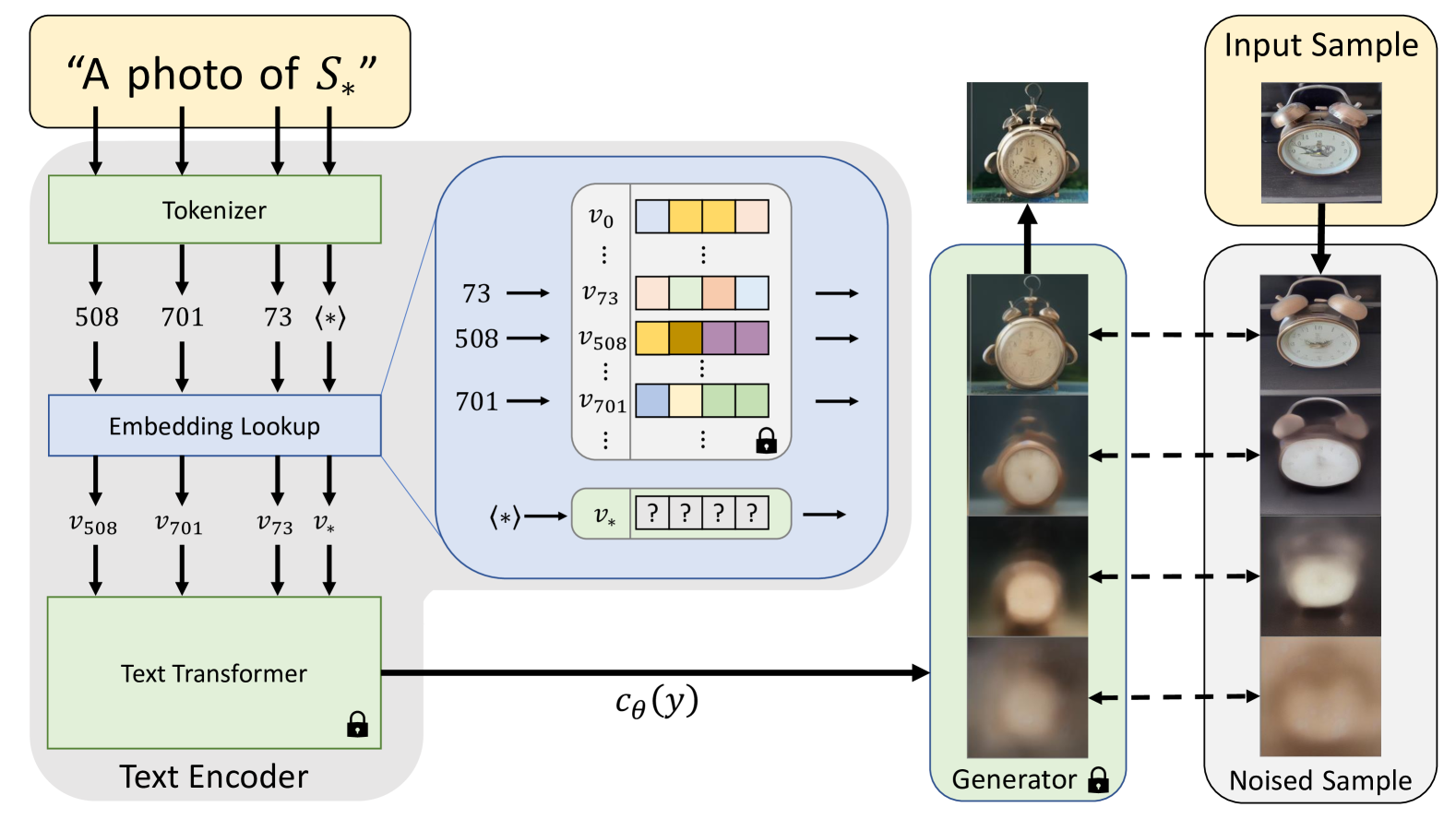
手法
目標:視覚的なタスクである生成を導くことができる擬似単語を見つけること
潜在拡散モデル
潜在拡散モデル(LDM)にノイズ除去確率拡散モデル(DDPM)を導入して、オートエンコーダーにする。LDMロスを定義する

Textual Inversion
「A photo of S」のような「S」ってどうやって求めるの? → 潜在変数から間接的に求める
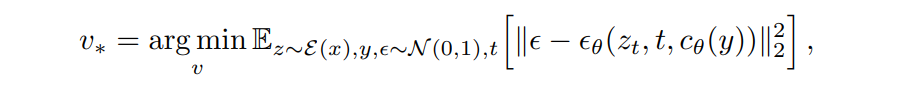
式はロス関数と同じ。結局はロスを最小化するような潜在表現を見つけているだけ。訓練時のプロンプトはCLIPのプロンプトをランダムで使った。
結果
画像のバリエーション

- DALLE-2
- 画像を提供することで、細部が限定された有名な物体(例:アラジンのランプ)については、より魅力的なサンプルを再現できる
- CLIPが見たことがないような個人的な物(マグカップ、ティーポット)の細部は、まだ苦労している
- 本手法
- 細かいディテールを、たった1単語の埋め込みで捉えることに成功していると主張
Text-Guided Synthesis
「S*」とは擬似単語はモデルが活用できる意味的な概念をカプセル化
- 先行研究のPALAVRA (Cohen et al., 2022)との比較。本研究これと似ている
- PALAVRAはオブジェクトセットをCLIPのテキスト埋め込み空間にエンコードし、対比学習と周期的整合性目標の混合を用いる
- 本研究はVQGAN-CLIP (Crowson et al., 2022) とCLIP-Guided Diffusion (Crowson, 2021) を活用し新しい画像を合成
- 大きな違いはCLIPを直接的に使っているか、CLIPを使って訓練されたモデルを使っているか

- PALAVRAによって生成された画像は、典型的にターゲットプロンプトからの要素(例:ビーチ、月)を含むが、それらは正確に概念を捕らえることができず、かなりの視覚的破損がある。
- これはPALAVRAが識別的な目標で訓練されたため、当然と言えば当然
- PALAVRAをよりよくしたい場合、モデルは2つの典型的な概念を区別するのに十分な情報(例:マグカップが白黒で文字らしき記号があること)だけを符号化する必要がある
- さらに、PALAVRAの単語発見プロセスのように、自然画像多様体上の出力にマッピング可能な埋め込みベクトルを含む埋め込み空間の領域に留まる必要がない(Text Transformerで別の多様体に持ってきて良い)。
- CLIPベースのモデルは新しいものを作成するための計算量が高価
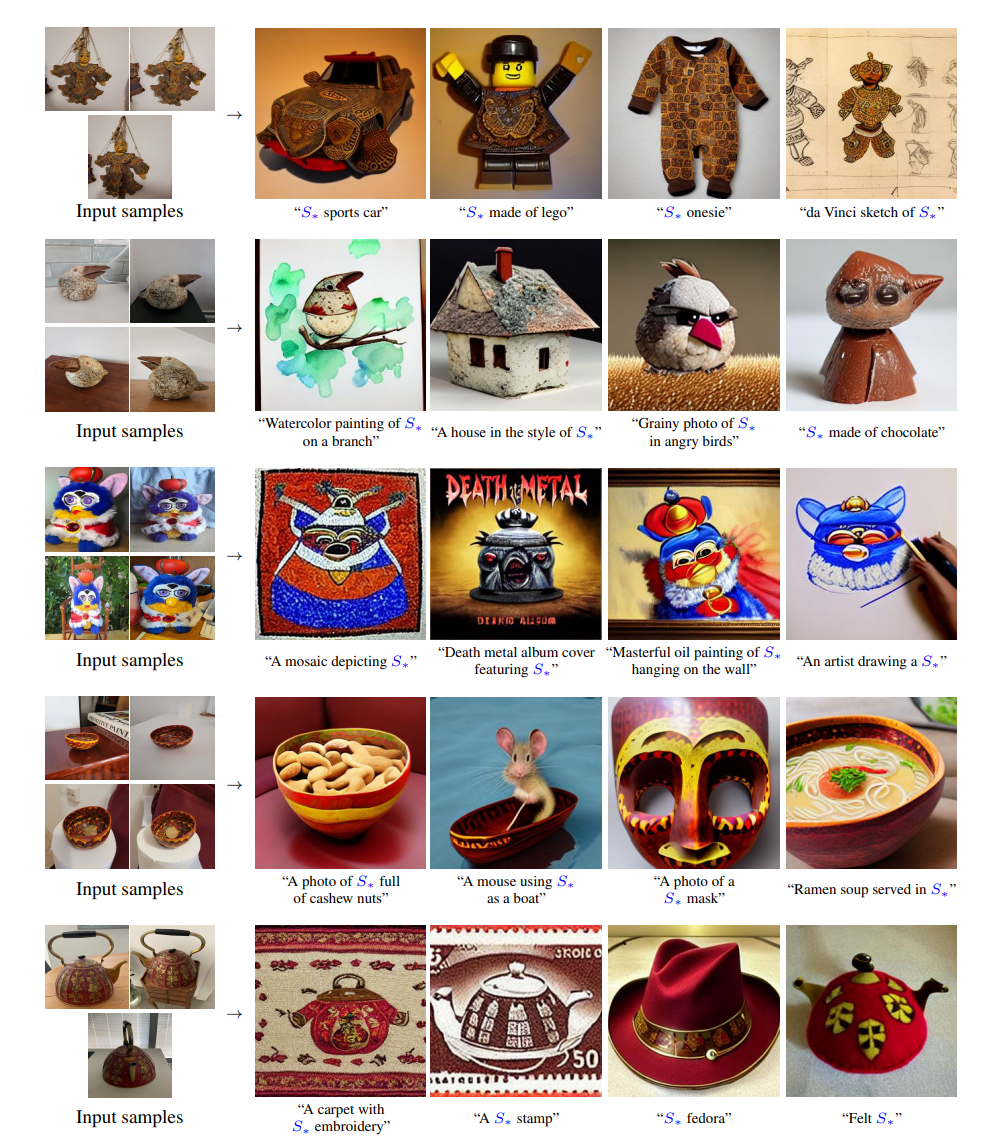
スタイル変換 / コンセプトの合成
入力画像を参照画像とし、「The streets of Paris in the style of S∗」「Adorable corgi in the style of S∗」のようにプロンプトで指定して生成可能。
この応用として、2種類の画像群$S_{style}, S_{clock}$にから、疑似単語を2つとして「Photo of $S_{clock}$in the style of $S_{style}$」という合成も可能。
※権利の関係で画像は省略
バイアスの除去
インターネットの画像から学習されたモデルは、元のバイアスを継承していることが多い。少数の別の画像を入力画像とすれば、バイアスを解消した画像を生成できる。

定量評価
GAN反転の研究のように、歪みと編集可能性のトレードオフがある。しかし、この研究では、GAN反転で一般的に用いられる解決策の多くは、役に立たないか、積極的に有害であることが明らかになった
評価指標
生成された画像のバリエーションの評価
- CLIP空間での類似度を測定することで意味的な距離を考慮
- 生成画像と概念別学習画像との、CLIP空間でのコサイン類似度の平均値を再構成スコアとした
テキストプロンプトを用いた編集能力の評価
- DDIMステップで画像を生成し、サンプルの平均CLIP空間埋め込み量を計算
- プレースホルダーを省略したテキストプロンプトのCLIP空間埋め込みとのコサイン類似度を計算する(例:”A photo of on the moon”)
- スコアが高いほど、編集能力が高く、プロンプト自体に忠実であることを示す
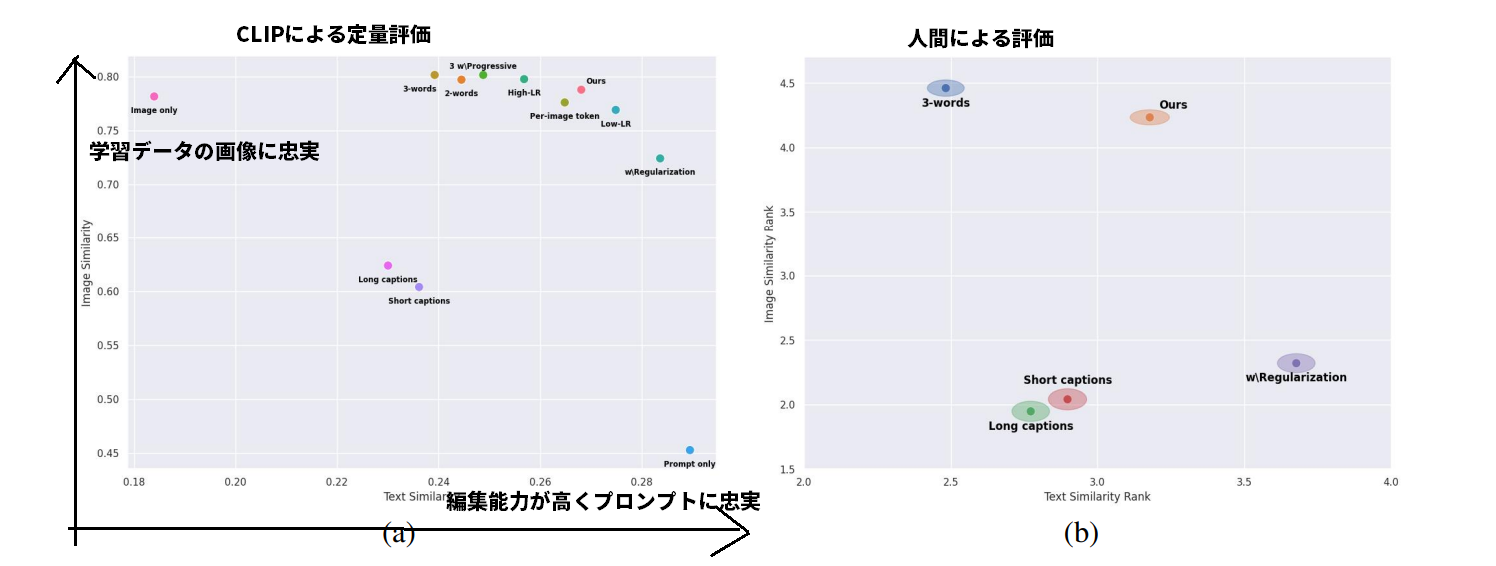
学習率を変えるだけで、単一埋め込みモデルをこの曲線に沿って移動させられ、トレードオフをユーザがある程度制御できる。
限界
- 本手法は自由度が高い反面、正確な形状の学習は困難
- 本手法では、1つの概念を学習するのに2時間程度かかり、最適化時間が長くなる
社会への影響
著作権の問題。mimicで話題になった問題の解決案を示していて、個人的には面白い。
最後に、芸術的なスタイルを学習する能力は、著作権侵害に悪用される可能性がある。アーティストに対価を支払う代わりに、ユーザーが無断でアーティストの画像を学習し、似たようなスタイルの画像を生成することが可能である。現在でも、生成されたアートワークの識別は容易ですが、将来的には、このような侵害の発見や法的な追求が困難になる可能性があります。しかし、このような欠点は、アーティストが独自のスタイルをライセンスする能力や、新しい作品の初期プロトタイプを迅速に作成する能力など、これらのツールが提供できる新しい機会によって相殺されることを期待しています。
私たちは、このアプローチが将来のパーソナライズド生成のための道を開くことを期待しています。これらは、芸術的なインスピレーションを与えることから製品デザインに至るまで、多くの下流アプリケーションの核となる可能性があります。
まとめと感想
- Stable Diffusionのファインチューニングの文脈で紹介されることの多い論文だが、この論文の真の目的は「与えられた画像に隠された埋め込み表現の獲得し、擬似言語としてプロンプトで使う」こと。誤解されていることが多い論文かもしれない
- 単純な生成モデルだけでなく、スタイルや場所を変えて別のものに転移するのが面白い。遅さはスタイル変換が高速化したようにそのうち解決しそう
- インターネット上のデータのバイアスを補正できるというのは「なるほど」と思った
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー