
TensorFlow2.0でDistribute Trainingしたときにfitと訓練ループで精度が違ってハマった話


TensorFlowでDistribute Training(複数GPUやTPUでの訓練)をしたときに、Keras APIのfit()でのValidation精度と、訓練ループを書いたときの精度でかなり(1~2%)違うという状況に遭遇しました。特定の文を忘れただけだったのですが、解決に1日かかったのでメモとしておいておきます。
目次
環境
TensorFlow 2.0.0
Google Colab TPUランタイム
Kerasのfit()の場合のコード
CIFAR-10です。こちらの記事のコードとほとんど同じです。
import tensorflow as tf
import os
# tpu用
# 詳細 https://www.tensorflow.org/guide/distributed_training#tpustrategy
tpu_grpc_url = "grpc://" + os.environ["COLAB_TPU_ADDR"]
tpu_cluster_resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu_grpc_url)
tf.config.experimental_connect_to_cluster(tpu_cluster_resolver) # TF2.0の場合、ここを追加
tf.tpu.experimental.initialize_tpu_system(tpu_cluster_resolver) # TF2.0の場合、今後experimentialが取れる可能性がある
strategy = tf.distribute.experimental.TPUStrategy(tpu_cluster_resolver) # ここも同様
import tensorflow.keras.layers as layers
import numpy as np
import pickle
class Model(layers.Layer):
def __init__(self):
super().__init__()
self.block1 = self.conv_bn_relu(64, 3)
self.block2 = self.conv_bn_relu(128, 3)
self.block3 = self.conv_bn_relu(256, 3)
self.last = tf.keras.Sequential([
layers.GlobalAveragePooling2D(),
layers.Dense(10, activation="softmax")
])
def conv_bn_relu(self, ch, reps):
l = []
for i in range(reps):
l.append(layers.Conv2D(ch, 3, padding="same"))
l.append(layers.BatchNormalization())
l.append(layers.ReLU())
return tf.keras.Sequential(l)
def __call__(self, inputs, training=None):
x = tf.nn.avg_pool2d(self.block1(inputs, training=training), 2, 2, "VALID")
x = tf.nn.avg_pool2d(self.block2(x, training=training), 2, 2, "VALID")
x = self.block3(x, training=training)
x = self.last(x)
return x
def data_augmentation(image):
x = tf.cast(image, tf.float32) / 255.0 # uint8 -> float32
x = tf.image.random_flip_left_right(x) # horizontal flip
x = tf.pad(x, tf.constant([[2, 2], [2, 2], [0, 0]]), "REFLECT") # pad 2 (outsize:36x36)
# 黒い領域を作らないようにReflect padとしている(KerasのImageDataGeneratorと同じ)
x = tf.image.random_crop(x, size=[32, 32, 3]) # random crop (outsize:32xx32)
return x
def create_model():
inputs = layers.Input((32, 32, 3))
x = Model()(inputs)
return tf.keras.models.Model(inputs, x)
def load_dataset(batch_size):
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar10.load_data()
trainset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
trainset = trainset.map(
lambda image, label: (data_augmentation(image), tf.cast(label, tf.float32))
).shuffle(buffer_size=1024).repeat().batch(batch_size).prefetch(
buffer_size=tf.data.experimental.AUTOTUNE
)
testset = tf.data.Dataset.from_tensor_slices((X_test, y_test))
testset = testset.map(
lambda image, label: (tf.cast(image, tf.float32) / 255.0, tf.cast(label, tf.float32))
).batch(batch_size).prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
return trainset, testset
def lr_scheduler(epoch):
if epoch <= 60: return 0.1
elif epoch <= 85: return 0.01
else: return 0.001
def main():
batch_size = 128
trainset, testset = load_dataset(batch_size)
with strategy.scope():
model = create_model()
loss = tf.keras.losses.SparseCategoricalCrossentropy()
acc = tf.keras.metrics.SparseCategoricalAccuracy()
optim = tf.keras.optimizers.SGD(0.1, momentum=0.9)
# callback
scheduler = tf.keras.callbacks.LearningRateScheduler(lr_scheduler)
hist = tf.keras.callbacks.History()
# train
model.compile(optimizer=optim, loss=loss, metrics=[acc])
model.fit(trainset, validation_data=testset, epochs=100, steps_per_epoch=50000 // batch_size,
callbacks=[scheduler, hist])
history = hist.history
with open("history_fit.dat", "wb") as fp:
pickle.dump(history, fp)
if __name__ == "__main__":
main()
fit()に「validation_data=」で入れたときの、Validation精度は間違っていません。
fitでのValidation精度と、訓練ループでValidation精度を計測したときの精度が微妙に異なることはありますが、それでも0.05%ぐらいの微小な差です(1%も2%も誤差は出ない)。
KerasのfitでのValidation精度は92.5%となりました(93%以上出ることもある)。
カスタム訓練ループ(間違った例)
これは誤った例です。どこが誤っているのか探してみてださい。自分はこの間違い見つけるのに1日かかりました。
import tensorflow as tf
import os
# tpu用
# 詳細 https://www.tensorflow.org/guide/distributed_training#tpustrategy
tpu_grpc_url = "grpc://" + os.environ["COLAB_TPU_ADDR"]
tpu_cluster_resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu_grpc_url)
tf.config.experimental_connect_to_cluster(tpu_cluster_resolver) # TF2.0の場合、ここを追加
tf.tpu.experimental.initialize_tpu_system(tpu_cluster_resolver) # TF2.0の場合、今後experimentialが取れる可能性がある
strategy = tf.distribute.experimental.TPUStrategy(tpu_cluster_resolver) # ここも同様
from tensorflow.keras import layers
import pickle
class Model(layers.Layer):
def __init__(self):
super().__init__()
self.block1 = self.conv_bn_relu(64, 3)
self.block2 = self.conv_bn_relu(128, 3)
self.block3 = self.conv_bn_relu(256, 3)
self.last = tf.keras.Sequential([
layers.GlobalAveragePooling2D(),
layers.Dense(10, activation="softmax")
])
def conv_bn_relu(self, ch, reps):
l = []
for i in range(reps):
l.append(layers.Conv2D(ch, 3, padding="same"))
l.append(layers.BatchNormalization())
l.append(layers.ReLU())
return tf.keras.Sequential(l)
def __call__(self, inputs, training=None):
x = tf.nn.avg_pool2d(self.block1(inputs, training=training), 2, 2, "VALID")
x = tf.nn.avg_pool2d(self.block2(x, training=training), 2, 2, "VALID")
x = self.block3(x, training=training)
x = self.last(x)
return x
def data_augmentation(image):
x = tf.cast(image, tf.float32) / 255.0 # uint8 -> float32
x = tf.image.random_flip_left_right(x) # horizontal flip
x = tf.pad(x, tf.constant([[2, 2], [2, 2], [0, 0]]), "REFLECT") # pad 2 (outsize:36x36)
# 黒い領域を作らないようにReflect padとしている(KerasのImageDataGeneratorと同じ)
x = tf.image.random_crop(x, size=[32, 32, 3]) # random crop (outsize:32xx32)
return x
def load_dataset(batch_size):
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar10.load_data()
trainset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
trainset = trainset.map(
lambda image, label: (data_augmentation(image), tf.cast(label, tf.float32))
).shuffle(buffer_size=50000).batch(batch_size).prefetch(
buffer_size=tf.data.experimental.AUTOTUNE
)
testset = tf.data.Dataset.from_tensor_slices((X_test, y_test))
testset = testset.map(
lambda image, label: (tf.cast(image, tf.float32) / 255.0, tf.cast(label, tf.float32))
).batch(batch_size).prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
return trainset, testset
def main():
batch_size = 128
trainset, valset = load_dataset(batch_size)
result = {"val_acc": [], "lr": []}
with strategy.scope():
model = Model()
optim = tf.keras.optimizers.SGD(0.1, momentum=0.9)
loss_func = tf.keras.losses.SparseCategoricalCrossentropy(reduction=tf.keras.losses.Reduction.NONE)
acc = tf.keras.metrics.SparseCategoricalAccuracy()
def train_on_batch(X, y_true):
with tf.GradientTape() as tape:
y_pred = model(X, training=True)
per_sample_loss = loss_func(y_true, y_pred)
loss = tf.reduce_sum(per_sample_loss, keepdims=True) * (1. / batch_size)
gradient = tape.gradient(loss, model.trainable_weights)
optim.apply_gradients(zip(gradient, model.trainable_weights))
acc.update_state(y_true, y_pred)
return loss
@tf.function
def distributed_train_on_batch(X, y):
per_replica_losses = strategy.experimental_run_v2(train_on_batch, args=(X, y))
return strategy.reduce(tf.distribute.ReduceOp.SUM, per_replica_losses, axis=None)
def validation_on_batch(X, y_true):
y_pred = model(X, training=False)
acc.update_state(y_true, y_pred)
@tf.function
def distributed_validation_on_batch(X, y):
return strategy.experimental_run_v2(validation_on_batch, args=(X, y))
for i in range(100):
acc.reset_states()
print("Epoch = ", i)
for X, y in trainset:
distributed_train_on_batch(X, y)
train_acc = acc.result().numpy()
acc.reset_states()
for X, y in valset:
distributed_validation_on_batch(X, y)
print(f"Train acc = {train_acc}, Validation acc = {acc.result().numpy()}")
if i == 60:
optim.lr = 0.01
elif i == 85:
optim.lr = 0.001
result["val_acc"].append(acc.result().numpy())
result["lr"].append(optim.lr.numpy()) # numpyにしないとWeaker objectが云々言うから
with open("history_incorrect.dat", "wb") as fp:
pickle.dump(result, fp)
if __name__ == "__main__":
main()
Validation精度を見てみましょう。この間違った例では91.61%となりました。fitの場合より、1~1.5%ぐらい下がっています。
さらに困ったのは、このコード特にエラーも出さずに訓練が普通に進んでしまうのですよね(今後のTFで変わるかもしれません)。なので、いろんな可能性を疑わないといけないのがつらかったです。
間違いの原因
では答えを。この2行を入れなかったのが間違いでした。
# with strategy.scope() 以下に入れる
trainset = strategy.experimental_distribute_dataset(trainset)
valset = strategy.experimental_distribute_dataset(valset)
これはなにかというと、Distribute Training用にデータセットをコンバートするためのものです。TPUのように複数のデバイスで訓練する際は、この変換が必要なのです。
distribute_datasetへの返還前後での損失関数の挙動
もう少し挙動を詳しく見てみましょう。TPUでは損失計算時のReduceを切っているつまり
loss_func = tf.keras.losses.SparseCategoricalCrossentropy(reduction=tf.keras.losses.Reduction.NONE)
としているため、サンプル単位の損失値が計算されます。言い換えれば、損失値のshapeは「(デバイスあたりのバッチサイズ, )」となるはずです。デバイスあたりのバッチサイズとはなにかというと、バッチをデバイス数で割ったものです。例えばバッチサイズが128で、デバイス数が8なら、デバイスあたりのバッチサイズは16となります。
これを確認するには、train_on_batch()内での
per_sample_loss = loss_func(y_true, y_pred)
print(per_sample_loss)
この値のshapeを見ればいいわけです。間違った例では、
# Tensor("sparse_categorical_crossentropy/weighted_loss/Mul:0", shape=(128,), dtype=float32, device=/job:worker/replica:0/task:0/device:CPU:0)
このように、デバイスあたりのバッチサイズではなく、全体の(グローバルな)バッチサイズが損失計算上にあらわれているのです。
trian_on_batchはDistributeに(デバイス単位で分散されて)計算されています。これは何を意味するのかというと、デバイス単位でデータを分割せずに、全てのデバイスで同一のデータを参照して訓練しているということになります。
言い換えれば、同一データをデバイス数分だけ勾配降下法を適用しているといういびつな状態になっています(同一視していいかは疑問はあるが、デバイス数分学習率が大きくなったともとらえられる)
逆にこのコード
# with strategy.scope() 以下に入れる
trainset = strategy.experimental_distribute_dataset(trainset)
valset = strategy.experimental_distribute_dataset(valset)
を挿入したあとの、train_on_batchにおけるper_sample_lossのshapeは、
# Tensor("sparse_categorical_crossentropy/weighted_loss/Mul:0", shape=(16,), dtype=float32, device=/job:worker/replica:0/task:0/device:CPU:0)
shape=(16,)となり、デバイス単位でデータが分割されるようになりました。これで正しい結果になりました。
正しいコード
正しいコードの全体を張ります。誤ったコードに2行追加しただけです。
import tensorflow as tf
import os
# tpu用
# 詳細 https://www.tensorflow.org/guide/distributed_training#tpustrategy
tpu_grpc_url = "grpc://" + os.environ["COLAB_TPU_ADDR"]
tpu_cluster_resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu_grpc_url)
tf.config.experimental_connect_to_cluster(tpu_cluster_resolver) # TF2.0の場合、ここを追加
tf.tpu.experimental.initialize_tpu_system(tpu_cluster_resolver) # TF2.0の場合、今後experimentialが取れる可能性がある
strategy = tf.distribute.experimental.TPUStrategy(tpu_cluster_resolver) # ここも同様
from tensorflow.keras import layers
import pickle
class Model(layers.Layer):
def __init__(self):
super().__init__()
self.block1 = self.conv_bn_relu(64, 3)
self.block2 = self.conv_bn_relu(128, 3)
self.block3 = self.conv_bn_relu(256, 3)
self.last = tf.keras.Sequential([
layers.GlobalAveragePooling2D(),
layers.Dense(10, activation="softmax")
])
def conv_bn_relu(self, ch, reps):
l = []
for i in range(reps):
l.append(layers.Conv2D(ch, 3, padding="same"))
l.append(layers.BatchNormalization())
l.append(layers.ReLU())
return tf.keras.Sequential(l)
def __call__(self, inputs, training=None):
x = tf.nn.avg_pool2d(self.block1(inputs, training=training), 2, 2, "VALID")
x = tf.nn.avg_pool2d(self.block2(x, training=training), 2, 2, "VALID")
x = self.block3(x, training=training)
x = self.last(x)
return x
def data_augmentation(image):
x = tf.cast(image, tf.float32) / 255.0 # uint8 -> float32
x = tf.image.random_flip_left_right(x) # horizontal flip
x = tf.pad(x, tf.constant([[2, 2], [2, 2], [0, 0]]), "REFLECT") # pad 2 (outsize:36x36)
# 黒い領域を作らないようにReflect padとしている(KerasのImageDataGeneratorと同じ)
x = tf.image.random_crop(x, size=[32, 32, 3]) # random crop (outsize:32xx32)
return x
def load_dataset(batch_size):
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar10.load_data()
trainset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
trainset = trainset.map(
lambda image, label: (data_augmentation(image), tf.cast(label, tf.float32))
).shuffle(buffer_size=50000).batch(batch_size).prefetch(
buffer_size=tf.data.experimental.AUTOTUNE
)
testset = tf.data.Dataset.from_tensor_slices((X_test, y_test))
testset = testset.map(
lambda image, label: (tf.cast(image, tf.float32) / 255.0, tf.cast(label, tf.float32))
).batch(batch_size).prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
return trainset, testset
def main():
batch_size = 128
trainset, valset = load_dataset(batch_size)
result = {"val_acc": [], "lr": []}
with strategy.scope():
model = Model()
optim = tf.keras.optimizers.SGD(0.1, momentum=0.9)
# Distributed用のデータセットの変換を行う
trainset = strategy.experimental_distribute_dataset(trainset)
valset = strategy.experimental_distribute_dataset(valset)
loss_func = tf.keras.losses.SparseCategoricalCrossentropy(reduction=tf.keras.losses.Reduction.NONE)
acc = tf.keras.metrics.SparseCategoricalAccuracy()
def train_on_batch(X, y_true):
with tf.GradientTape() as tape:
y_pred = model(X, training=True)
per_sample_loss = loss_func(y_true, y_pred)
loss = tf.reduce_sum(per_sample_loss, keepdims=True) * (1. / batch_size)
gradient = tape.gradient(loss, model.trainable_weights)
optim.apply_gradients(zip(gradient, model.trainable_weights))
acc.update_state(y_true, y_pred)
return loss
@tf.function
def distributed_train_on_batch(X, y):
per_replica_losses = strategy.experimental_run_v2(train_on_batch, args=(X, y))
return strategy.reduce(tf.distribute.ReduceOp.SUM, per_replica_losses, axis=None)
def validation_on_batch(X, y_true):
y_pred = model(X, training=False)
acc.update_state(y_true, y_pred)
@tf.function
def distributed_validation_on_batch(X, y):
return strategy.experimental_run_v2(validation_on_batch, args=(X, y))
for i in range(100):
acc.reset_states()
print("Epoch = ", i)
for X, y in trainset:
distributed_train_on_batch(X, y)
train_acc = acc.result().numpy()
acc.reset_states()
for X, y in valset:
distributed_validation_on_batch(X, y)
print(f"Train acc = {train_acc}, Validation acc = {acc.result().numpy()}")
if i == 60:
optim.lr = 0.01
elif i == 85:
optim.lr = 0.001
result["val_acc"].append(acc.result().numpy())
result["lr"].append(optim.lr.numpy()) # numpyにしないとWeaker objectが云々言うから
with open("history_correct.dat", "wb") as fp:
pickle.dump(result, fp)
if __name__ == "__main__":
main()
Validation精度は92.64%となりました。これでやっとKerasのfitと同じ値が出ました。
学習曲線
Kerasのfit、カスタム訓練の間違った例、カスタム訓練の正しい例の学習曲線です。それぞれ別の学習なので、細かな差は出ています。
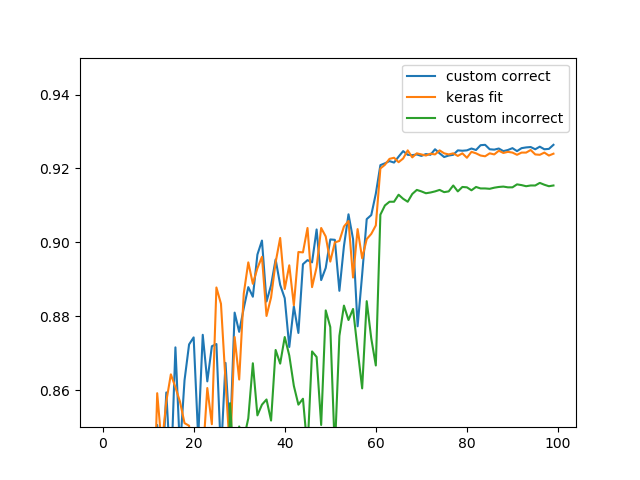
間違った例(custom_incorrect)の方が一歩精度が低いことが確認できるでしょう。
まとめ
- TF2.0のDistribute Trainingでは(2.0の現状としては)、Distribute Training用のデータセットに変換しないとかなり精度が落ちる。特に警告はしてくれない。
- こういうこと気にしたくなければ素直にKerasのfit()を使ったほうがいい
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー