
TensorFlow Data Validationを使ったお手軽で強力な探索的データ解析


特にテーブルデータで、実際の分析に入る前に欠損値やデータの分布の把握といった、探索的データ解析(EDA)というのは重要なプロセスになります。TensorFlow Data Validationというツールを使うとそれがたった数行で簡単にできます。その方法を紹介します。
目次
探索的データ解析(EDA)とは
欠損値や外れ値、値の分布などを調べること。これによって適切な前処理を選んでいくための重要なプロセス。Kaggleのテーブルコンペではほぼ必ずといっていいほどEDAのカーネルがあります。
つらいとこ
コードがめんどい。たかが前処理選ぶためのヒストグラムを書くのにいちいちコード書きたくない。いい感じに表形式でプロットするのをずばーっとやりたい。
TensorFlow Data Validation
TensorFlow Data Validation(TFDV)というのを使ってみましょう。ただし、Windows非対応(Ubuntu、MacOSのみ対応)なのでColab環境で行います。
インストール
インストールはpipから一発です。
!pip install tensorflow-data-validation
インストールが終わったら再起動を促すメッセージが表示されるので、ランタイムを再起動してみましょう。
タイタニックのデータを見てみる
おなじみのタイタニックのデータをTensorFlow Data Validationで見てみましょう。こちらのデータを使います。
データのダウンロード
wgetでデータをコピーします
!wget https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv
インポート
import tensorflow_data_validation as tfdv
統計量の可視化
たった2行でできます。
stats = tfdv.generate_statistics_from_csv("titanic.csv")
tfdv.visualize_statistics(stats)
CSVをそのままvisualize_statisticsに読ませることはできないので、TFDV用のstatisticsにコンバートしています。内部的にはスキーマーの推定などをやっているそうです。
TFDVの出力
TFDVの可視化にはNumeric Features(数値変数)と、Categorical Features(カテゴリー変数)に自動分類されます。それぞれどのような出力になるか見ていきます。
数値型の変数
1.デフォルトのプロット
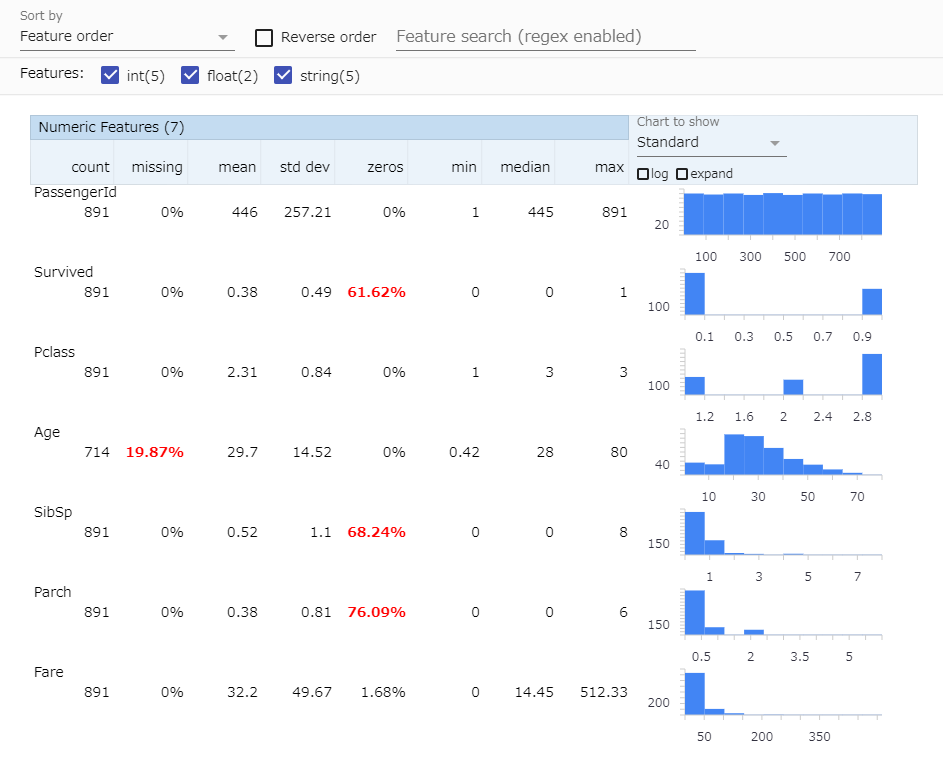
たった2行の割にここまで出してくれるのはすごい。見方は次の通りです。
- count: 有効データの数。欠損値があると減る
- missing : 欠損値の数。ここの数が0より大きいと欠損値対策する必要あり。
- mean : 平均
- std dev : 標準偏差
- zeros : ゼロの割合
- min : 最小値
- median : 中央値
- max : 最大値
欠損値が有益な情報ですね。右のヒストグラムで変数の分布も見ることができます。また他には「Sort by」で変数のソートや、「Feature search」で変数のフィルタリングもできます。
2.クォンタイル表示
「Chart to show」を「Quantiles」にします。こうするとクォンタイル値が表示できます。
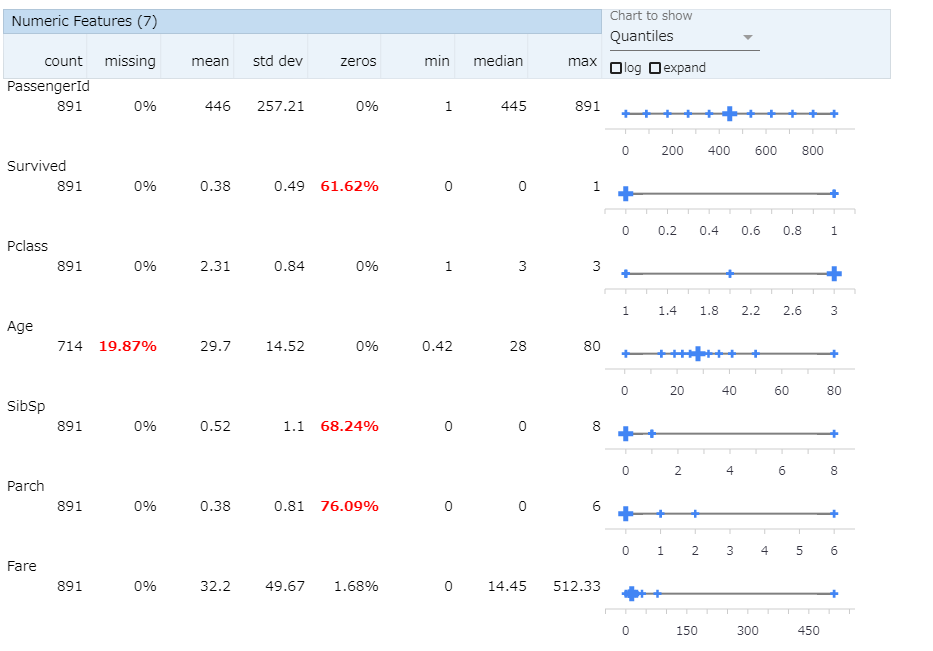
特にスケール調整する際に有効になりそうです。
3.logスケール表示
これは標準的な表示でもクォンタイル表示でもできますが、対数変換もできます。「log」ボタンにチェックを入れます。
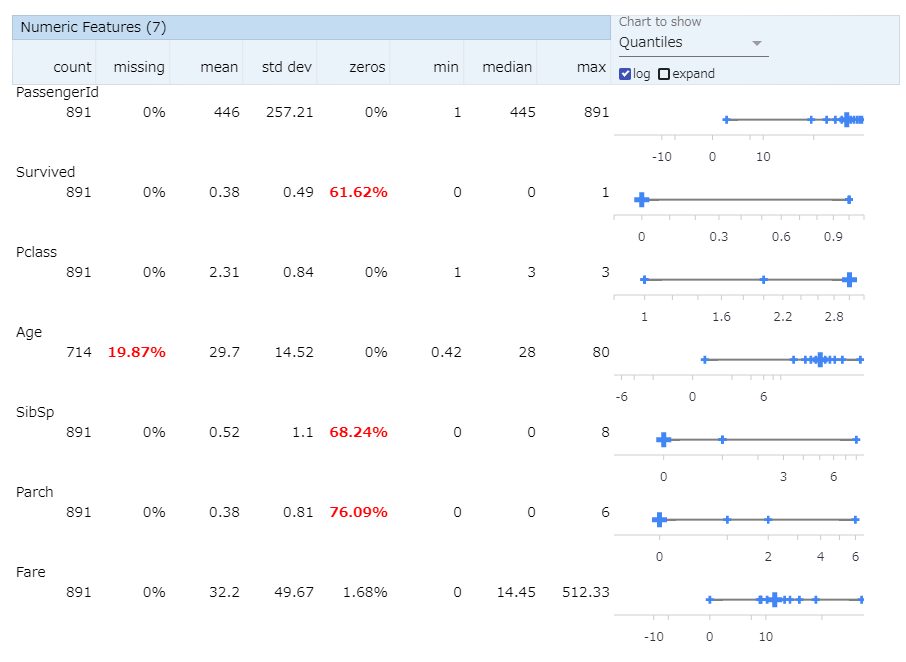
変数別に、線形スケールがいいか、対数スケールがいいか検討することもできるでしょう。これを見ると、Fare(運賃)は対数変換したほうが良さそうな感じがします(特にNNでやる場合)。
カテゴリー変数
下のほうをスクロールしていくとカテゴリー変数が表示されます。数値型かカテゴリー型かはTFDVが勝手に判別してくれます。あくまで自動判定なので、名前みたいなユニークカラムがこちらに入っていることもあります。
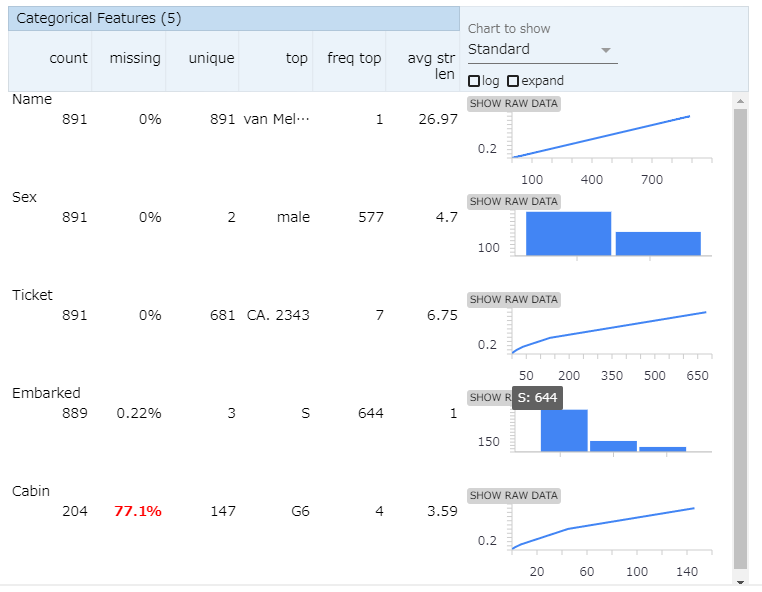
Embarked(乗船港)にこんな偏りがあったのは驚きですね。ほとんどがサウサンプトンから乗船だったというのがわかります。
まとめ
TFDV(TensorFlow Data Validation)を使うとたった数行で探索的データ解析ができる。
これだけでもかなり強力なように思いますが、その他の情報は「参考」のところのサイトを見てください。外れ値検出やスキーマーの表示なんかもできます。
参考
一番上の記事がわかりやすいです。公式ドキュメントはある程度使ってから読まないと多分理解しづらいと思います。
- TensorFlow Data Validationの紹介
https://medium.com/kazk1018-blog/tensorflow-data-validation%E3%81%AE%E7%B4%B9%E4%BB%8B-107fc4731a76 - Get started with Tensorflow Data Validation
https://www.tensorflow.org/tfx/data_validation/get_started - TensorFlow Data Validation: Checking and analyzing your data
https://www.tensorflow.org/tfx/guide/tfdv - TensorFlow Data Validation GitHub
https://github.com/tensorflow/data-validation
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー