
論文まとめ:Discovering Underground Maps from Fashion


- タイトル:Discovering Underground Maps from Fashion
- 論文:https://arxiv.org/abs/2012.02897
https://ar5iv.labs.arxiv.org/html/2012.02897 - カンファ:WACV2022
- 補助資料:https://www.cs.cornell.edu/~utkarshm/underground_maps/supplementary.pdf
- 動画:https://www.cs.cornell.edu/~utkarshm/underground_maps/supplementary_video.mp4
※論文よりも、この動画の最初の2分を見るのをおすすめ
目次
ざっくりいうと
- SNSに投稿された写真から、似たようなファッションセンスを持つ領域を分割し、教師なしでボトムアップで近傍地図を自動作成する研究
- 従来の行政区画のようなトップダウンのアプローチとは異なり、あくまで衣服の特徴からのクラスタリング
- 同心円状に集合を作り、特徴をヒストグラムでまとめ、ヒストグラムに対してクラスタリングをかけるのがこの手法のポイント
やりたいこと
- 論文では地下地図(Underground map)と呼んでいる:ファッションスタイルの分布の可視化
- オフィスエリアならスーツ、ビーチの近くならサングラス、大学の近くならロゴカラーなど、ファッションと地域性は関係あるよねという話
手法
データセットと服装の特徴
地図を作るためには、GeoStyleデータセットから770万枚の画像を使用した。これらはInstagramとFlickerからのもの
- ${I_i}$を人々の画像の集合とする
- 位置情報を$\mathbf{l}_i\in\mathbb{R}^2$でつける
ただ、服装の属性を判定する必要があるため、2万7000枚の小さなデータセットを作り、マルチタスクなCNNを訓練する。
- ファッションについて、マルチクラスのアノテーションをつける。GoogLeNetを使用してつけた
- 服の種類:スーツ、Tシャツ、ドレス
- アクセサリの有無:サングラス、ネクタイ
- 服の色:赤、青
- 属性の数は$A$とし、$I_i$に対して$\mathbf{a}_i\in\mathbb{R}^A$とする
770万枚のすべての画像に対し、CNNの最後から2番目のレイヤーの特徴量を使い、クラスタリングをする。具体的にはK=400の混合ガウスモデルを使った。クラスタリングで得られた$I_i$に対するクラスを$\mathbf{s}_i\in[1, K]$とする。
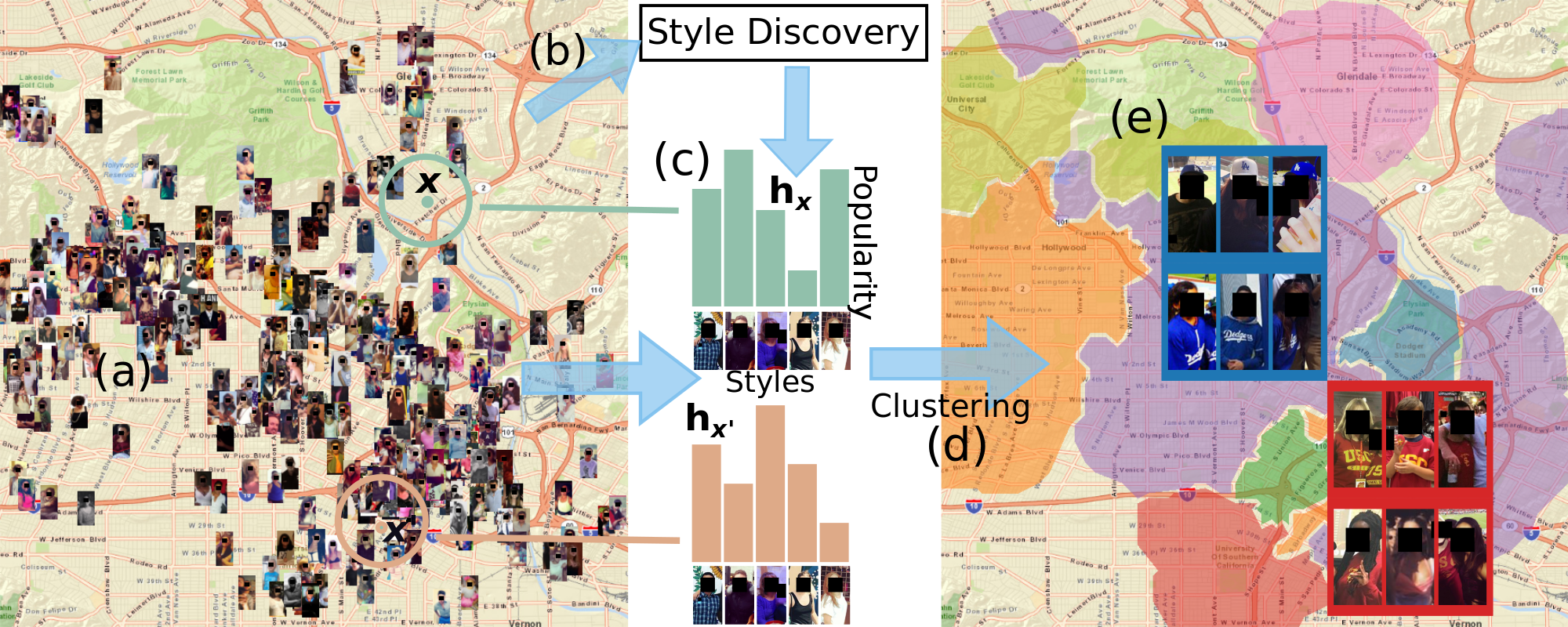
位置情報の特徴
場所は場所で同心円上の集合$T(\mathbf{x})$を作る。これは$x$の属する集合を示す。$r$はハイパーパラメーターで、大きく設定するとサンプル数を増やせ、信頼度の高い分布になる。信頼度と局所的な特徴を捉えるかのトレードオフになる。
$$T(\mathbf{x})={I_i:|\mathbf{l}_i-x|_2 < r}$$
→ 隣接する領域のIoUの和が0.5となるように$r$を決めた。
この手法はファッションのスタイルに対して、ヒストグラム$\mathbf{h}_x$を作るのがポイント。
- 集合$T$に属するファッション画像の属性を、ヒストグラムで集計したい。画像単位の特徴量から、地理空間上の集合についての特徴量に変換したい。
- 先程ファッションの属性について、$K$個のクラスタリングをしたので、$\mathbf{h}_x\in\mathbb{R}^K$なるヒストグラムを作る。
- このヒストグラムは隠れ層の特徴量の分布ではなく、単なる「あるクラス$K$に属する画像の頻度分布」を表したものと考えられる。
この論文がわかりづらいのは、同心円の集合とグリッドの集合を同時に語っていること。これは独立した別手法ではなく、グリッドとして可視化している集合は、実は同心円の集合と考えられる。
グリッド状のマップ
作りたいもの
地図全体を2Dのグリッドで敷き詰める。最終的に作りたいのはこういうもの
ヒストグラムのクラスタリング→ラベルの推定
ここで$(W, H)$は都市全体のBounding Boxのサイズで、$w, h$はBounding Boxの位置である。
$$\mathbf{x}_{ij}=(w+di, h+dj)\qquad \forall i\in\Bigl[0, \lfloor\frac{W}{d}\rfloor\Bigr], j\in\Bigl[0, \lfloor\frac{W}{d}\rfloor\Bigr]$$
この各グリッドに属する画像をすべて集めたものを$T(\mathbf{x}_{ij})$とし、このヒストグラムを$\mathbf{h}_{x_{ij}}$よする。このヒストグラムに対してK-Meansをかけ、各グリッドのラベルを得る。
各ヒストグラムの合計は1なので、L1距離をK-Meansの更新に使っている。
近傍の分析
論文の表記があまり明確に定義されておらず、よく理解できなかったので省略
結果得られた物
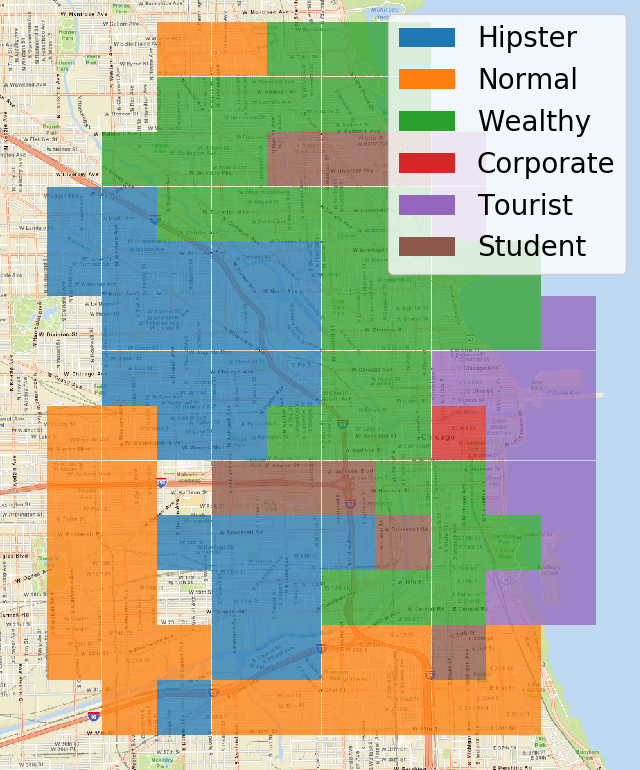
ファションからの地下地図は、従来の伝統的な分割(ダウンタウン、ミッドタウンなど)では捉えられなかった形質を捉えている。
ドジャースタジアムの周辺では、チームカラーにマッチするような特にユニークな服装が見られる。ボゴタはハイキングとアウトドアの旅行者による服装。

まとめと感想
- 位置情報と洋服のスタイルをつなげて、クラスタリングに落とし込むアプローチが面白い。汎用的に使えそう
- ユニークな近傍についての議論は、数式の定義がわからずよくわからなかった
- 行政区画のようなトップダウンのアプローチと、衣服によるボトムアップのアプローチで区域分けがかなり変わっているのが興味深い
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー