
論文まとめ:Exploring Visual Prompts for Adapting Large-Scale Models
Posted On 2022-11-10


- タイトル:Exploring Visual Prompts for Adapting Large-Scale Models
- 著者:Hyojin Bahng, Ali Jahanian, Swami Sankaranarayanan, Phillip Isola
- 所属:MIT CSAIL
- プロジェクトページ:https://hjbahng.github.io/visual_prompting/
- コード:https://github.com/hjbahng/visual_prompting
- 論文URL:https://arxiv.org/abs/2203.17274
目次
ざっくりいうと
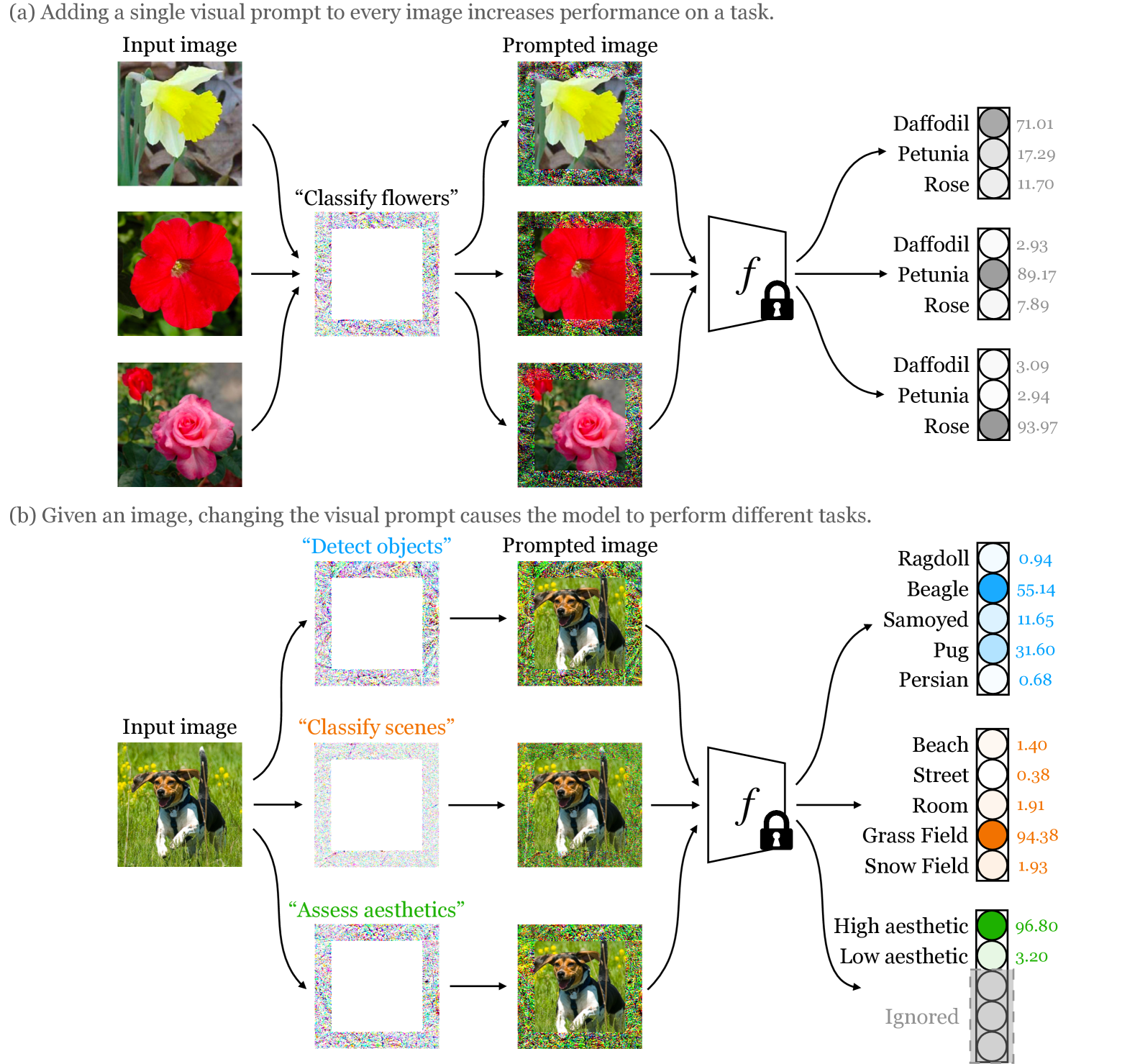
- CLIPを任意のデータセットに適応させるために、入力画像に対し、共通の画像を外挿する「Visual Prompting」を提唱
- ホワイトノイズ状のPaddingを適用するだけで、Fine-tuningに準じるような精度向上が見込まれる
- 提案手法によるCLIPのZero-shot精度からの精度改善が、データセットの分布ギャップによってもたらされることを定量的に示した

導入
- 着想として、NLPで広く使われているPromptingがある
- 人間は、新しいことを学ぶとき、現在の知識ベースで始めて、新しい知識を外挿する傾向がある
- 文章を理解して、話し始めた子供は、文章に付随する感情的な文脈を解釈する能力を急速に身につける
- 例)「スクールバスに乗り遅れた」「とても[mask]感じた」と続けると、子供は適切な感情表現ができる
- 提案するのは画像ベースのPrompting
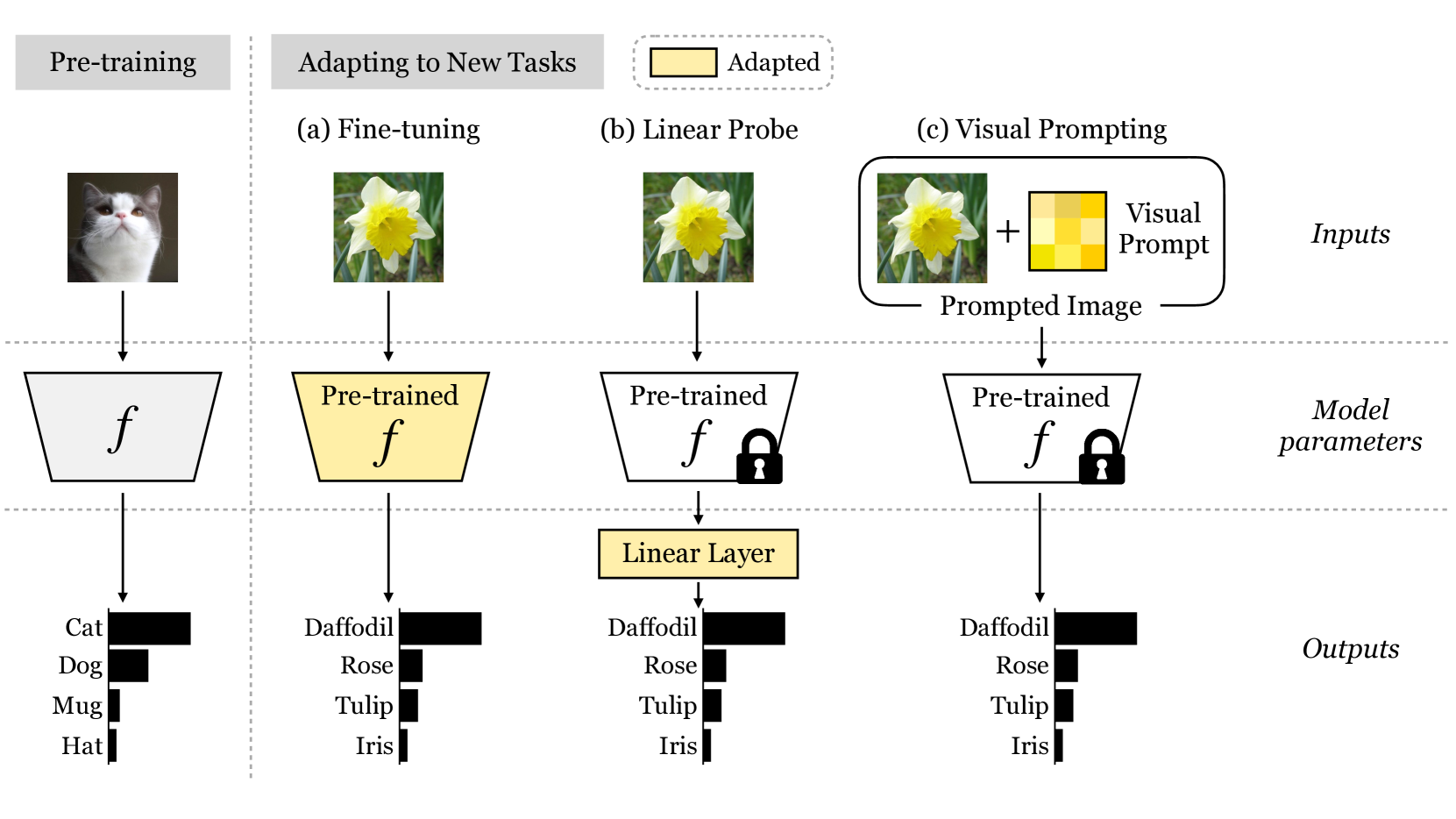
- 既存の手法として、Linear-ProbingやAdaptation手法がある
- Linear-Probe:CLIPのEmbeddingの行列積をとっているものを、線形分類にする
- 本質的にZero-shot推論はできなくなる
- Adaptation:訓練済みCLIPにいくつかのレイヤーを追加して、データに特化したよりリッチな特徴量マッピングを行い分類する(例:CoOp、Tip-Adapter)
- Visual Promptの場合、一度プロンプトを獲得してしまえば、テスト時にモデルにアクセスする必要がない
- 応用例:歩行者が、車のVisionシステムにアクセスすることなく、車からの視認性を向上させる
- Linear-Probe:CLIPのEmbeddingの行列積をとっているものを、線形分類にする
- Linear-Probeと同様、CLIPのレイヤーを再訓練することはないが、データセットによってはLinear-Probeを上回る精度を達成した
- 着想はAdversarial Exampleの逆の、「Unadversarial Examples」に近い
手法
定式化
全テスト画像に共通するプロンプト$v_\phi$を求めたい
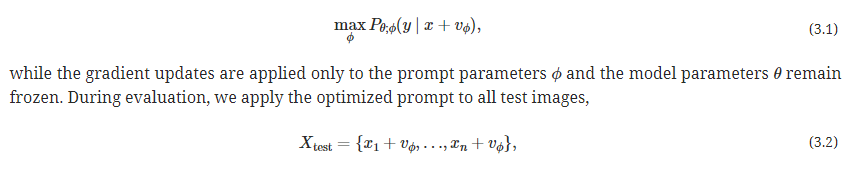
タスクごとに異なるVisual Promptを求められる
プロンプトの設計
- ランダムな位置のピクセルパッチ
- 固定位置のピクセルパッチ
- パディング
3つの視覚的テンプレートを検討。結果はPaddingが一番良かった
CLIPのモデルに一切変更を加えていないので、Zero-shot評価できるという点は一切変わらない
実装詳細
- Visual Promptは1,000エポックに学習
- Linear Probeの場合は、テキストエンコーダーを捨てて、係数を固定した画像エンコーダーに線形レイヤーをつける
- Linear Probeの場合、本質的にZero-shot推論はできなくなる
結果
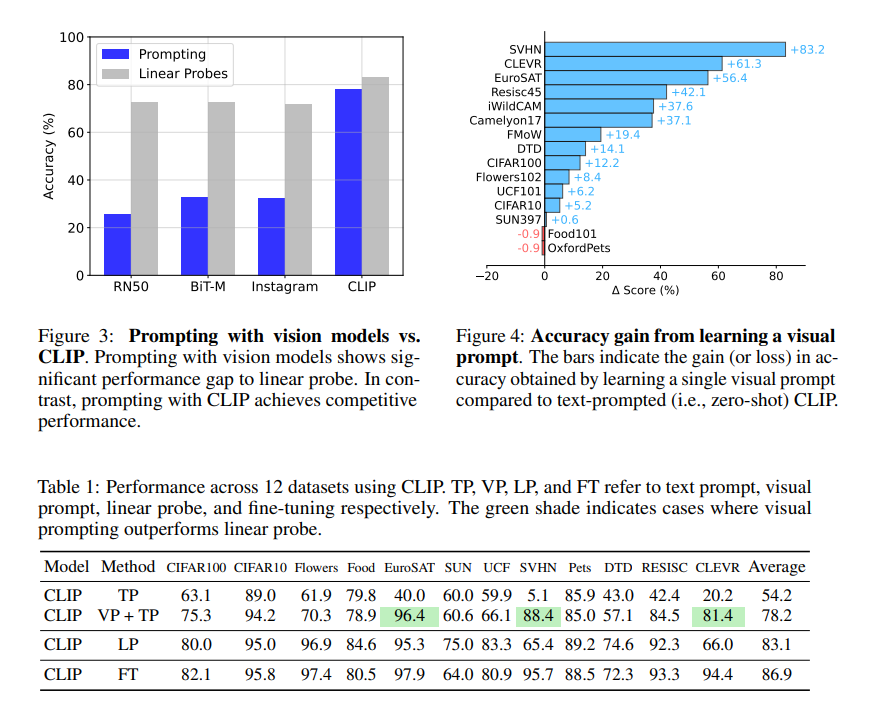
- 表記の説明
- TP:Text Promptだけ(CLIPの設定)
- VP+TP:Text Prompt+Visual Prompt(この論文の設定)
- LP:Linear Probe(CLIPの論文にあったもの。手軽だがZero-shotができなくなる)
- FT:モデル全体をFine tuning(計算量クソ重いし、Zero-shotが厳しくなる)
- VP+TPが良いか、Linear Probeが良いかはマチマチ。明らかにCLIPのText Promptのみよりかは良い
- Visual Promptの有効性は、CLIPのようなVision&Langのモデルで特に発揮される。RN50やBiT-MのようなVisionだけのモデルで使ってもあまり有効には機能しない
Visual Promptが良く機能するための状況とは?
- Visual Promptによる(TPに対する)ゲインはデータセットによってまちまちで、数%プラスのものもあれば、80%近く上がるものもある
- このゲインは、データセットの分布ギャップと相関がある
- データセットの分布ギャップを、ImageNetとのFIDやLPIPSによって定量化してみると、Visual Promptによるゲインと逆相関になることが確認された
- ちなみに、この論文の著者のPhillip Isola先生はPix2pixの著者。生成モデルでよく使われる指標で、分布ギャップを定量化するのが「らしい」やり方で面白い
- FIDやLPIPSが大きい→分布ギャップが大きい→Visual Promptによってギャップが埋められる
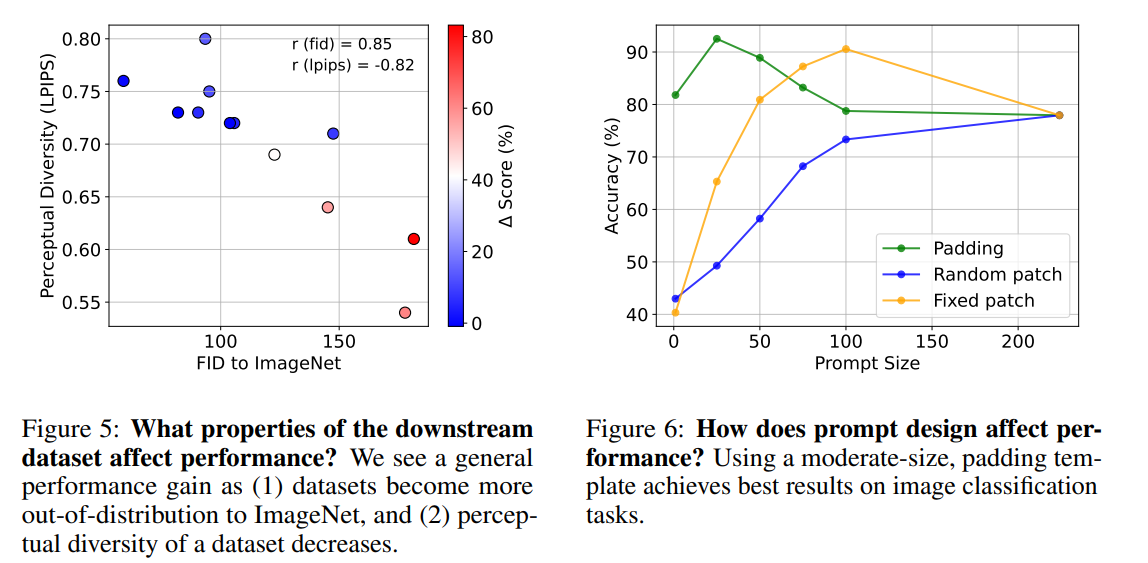
どのVisual Promptが良い?
→ Paddingが一番よい
極端な例だと、EuroSATに赤い点を1ピクセル入れただけで3%精度上がった

著者の補足
- Linear Probeに対してAverageで精度が負けているのは認めている
- どちらかというと、ビジョンモデルの新たな効果的な適応方法を明らかにしたいというお気持ち
- 精度上げたければ、既存のプロンプトエンジニアリングや、Adaptation、Linear Probeなどの手法と両立できる
まとめと(私の)感想
- 精度を上げるために、入力画像に共通の細工をするというのが、Vision&Langになると初めて有効に機能するようになったというのが面白い。やっていることはUnadversarial Exampleと同じというのも驚き
- 似たような議論は、VisionモデルだとTesting Time Augmentationがあるが、あれは上がって数%。Fine tuning一歩手前ぐらいの精度が上がるのは結構すごい
- Linear Probeに勝つぐらい精度を上げるには、もう少しリッチなプロンプト生成モデルを使わないとだめなのではないだろうか。既存のAdaptation手法と合わせて、今後の研究で出そう
- 顔認識の精度を上げるために、ホワイトノイズを顔に装備する日がくるのだろうか
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー