
論文まとめ:Improving Image Generation with Better Captions


- タイトル:Improving Image Generation with Better Captions
- 著者:James Betker、Gabriel Gohなど(OpenAIの人)
- 論文URL:https://cdn.openai.com/papers/dall-e-3.pdf
- URL:https://openai.com/dall-e-3
- デモ:ChatGPT Plusをお試しください^^

目次
ざっくりいうと
- OpenAIの画像生成モデル「DALLE-3」の技術仕様の論文
- 技術的な工夫は、T2Iの学習に使うキャプションをほぼ(95%)合成ベースで行うもの。人間のキャプションは背景の詳細や常識的な関係を無視するため、合成のほうが良い
- 画像生成モデルの学習において、機械的に作られた詳細なキャプションを使うことを定量・定性的に評価したのが貢献
導入
- 既存の画像生成モデルは、与えられたキャプションに含まれる単語、単語順序、意味を見落とすことが多い。この課題をプロンプトフォローと呼ぶことにする。
- プロンプトフォローについて、キャプションの改善に取り組むための新しいアプローチを提案
- 既存のテキストから画像へのモデルの基本的な問題は、それらが学習されたデータセットのテキストと画像のペアリングの質の低さと仮定
- データセットに含まれる画像に対して、改善されたキャプションを生成することを提案
- 画像の詳細かつ正確な説明を生成するロバストな画像キャプションを学習
- このキャプションをデータセットに適用し、より詳細なキャプションを生成
- 改良したデータセットでテキストから画像へのモデルを学習
- 合成データでの学習は新しいコンセプトではなく、Yu(2022b)など先行事例はある
- この論文の貢献:説明的な画像キャプションシステムを構築し、生成モデルを学習する際に合成キャプションを使用することの影響を測定
データの再キャプション
人間のキャプションは、画像の被写体の単純な記述に焦点を当ててしまい、画像に描かれた背景の詳細や常識的な関係は省略してしまう。具体的には以下の項目
- キッチンにシンクなどの物体が写っていること、歩道沿いに停止標識があることなどの物体の記述
- シーン内のオブジェクトの位置、オブジェクトの数
- オブジェクトの色や大きさ、常識的な詳細
- 画像内のテキスト
インターネット上のキャプションは不正確で、画像とのGroundingで不正確。例えば、よく使われるalt-text(alt属性)は、広告やミームを見つける。これらの問題は合成キャプションを用いて対処できると理論化。
画像キャプションの作成
画像キャプションは、テキストを予測する従来の言語モデルと似ている。言語モデルはトークン列の尤度関数の最大化。画像キャプションの場合は、これを画像を条件とするが、画像は次元が大きすぎるのでCLIPを条件とする。


- 短い合成キャプション(SSC)
- 記述的合成キャプション(DSC)
- インターネットにあるalt-text(生データ)
キャプションのファインチューニング
- 画像生成データセットのキャプションを改善するために、キャプションに偏りを与えて、テキストから画像へのモデル学習に有用な画像説明を生成したい
- 最初の試みでは、画像の主要な被写体のみを記述する(SSC)キャプションの小さなデータセットを構築
- このプロセスを繰り返し、微調整のデータセットに含まれる各画像の内容を記述した長くて記述性の高いキャプションのデータセットを作成。記述的合成キャプション(DSC)を作成
再キャプションされたデータセットの評価
合成テキストでモデルを学習したときの影響を以下の観点から評価
- タイプ別の合成キャプションによる性能の評価
- 合成キャプションとGround Truthの最適なブレンド比率
合成キャプションとGTのキャプションのブレンド
- 拡散モデルのような尤度モデルは、データセットの分布規則性に過剰に適合する傾向が有名
- 例:常にスペース文字で始まるテキストで学習させたT2Iモデルは、スペースで始まらないプロンプトで推論しようとするとうまく行かない
- 例:文字ケーシング。ピリオドで終わるかどうか、長さ、キャプションをa, anなどの単語で始めるかなどの文体傾向
- 合成キャプションの学習についてはこの問題を考慮する必要あり
- 人間が使うかもしれないスタイルとフォーマットに近いテキストの分布に入力を正則化。したがって、人間が書いたGTのキャプションを一定数ブレンドしてしまえばいい
- GTのキャプションは無料で使えるので、人間が書いたキャプションはあくまで正則化として少量ブレンド
- 私の注釈:逆の発想は結構あったが、人間が書いたデータがあくまでサブの正則化扱いなのがかなり新しい
- ブレンドはデータサンプリング時に行われ、固定された確率でグランドトゥルースまたは合成キャプションのいずれかをランダムに選択
評価方法
- TextEncoderがT5の画像拡散モデルを使用
- バッチサイズ2048で50万ステップ、合計1Bの画像で画像生成モデルを学習
- 指数移動平均を使用
- 評価方法はCLIP ViT-B/32による、画像埋め込みとプロンプトのテキスト埋め込みのコサイン類似度(CLIPスコア)
キャプションの種類ごとの比較
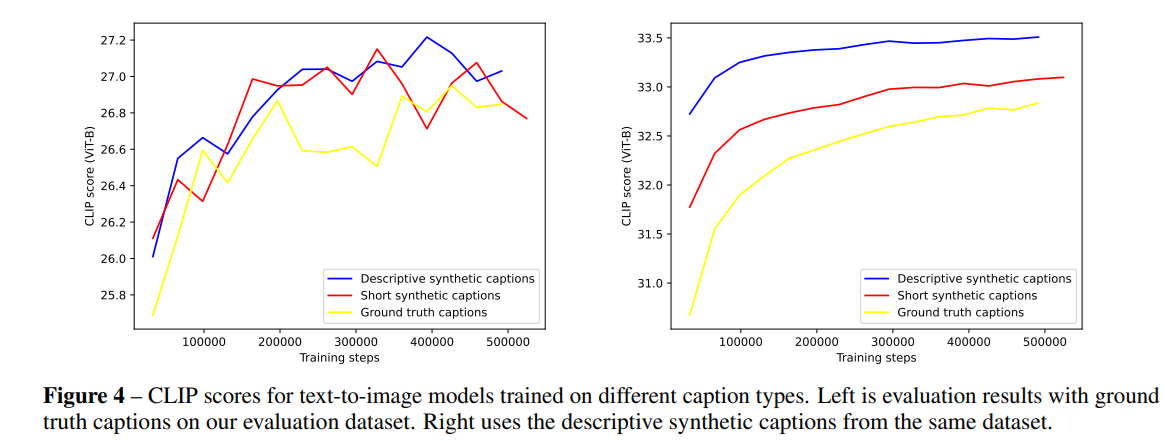
3タイプ比較→キャプションが長い(記述的)なほうが強い
- GTの画像のみで学習したT2Iの画像生成モデル
- 95%の短い合成キャプション(SSC)で学習したT2I
- 95%の記述的合成キャプションで(DSC)で学習したT2I
左と右の違い:左がGTのキャプションを基準にしたCLIPスコア、右が記述的なキャプションを基準にしたCLIPスコア
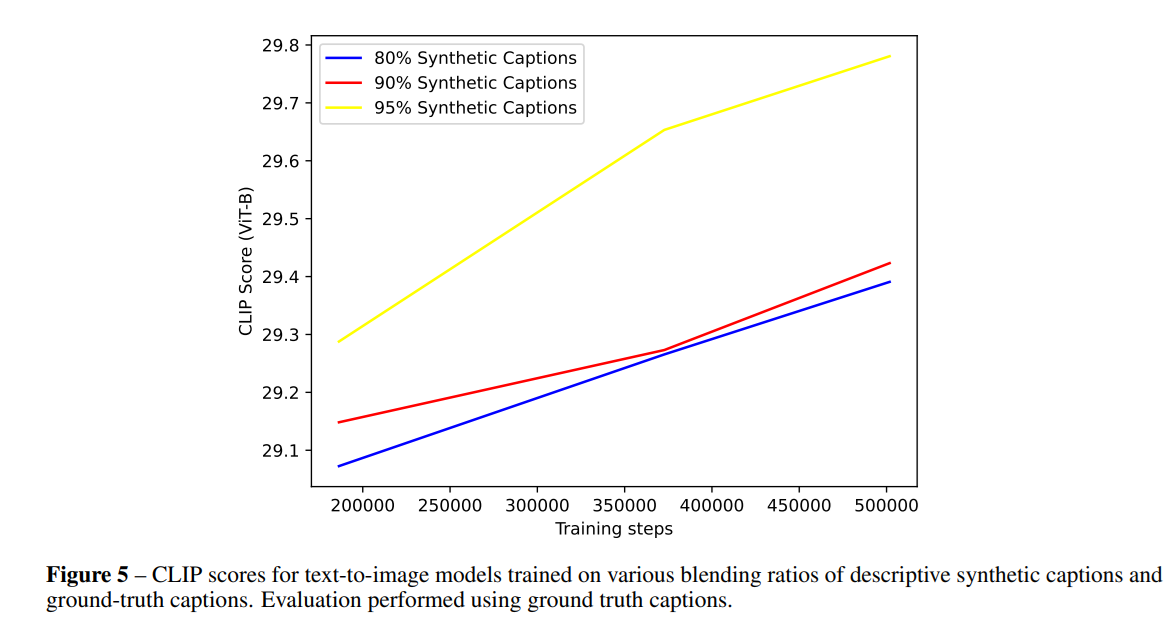
ブレンド比率
記述的なキャプションのブレンド比率(95%が一番良い)
- 80%合成キャプション
- 90%合成キャプション
- 95%合成キャプション
評価基準はGTのキャプション(GTのキャプションに対しても、合成比率が多いほうが性能がスケールする)
説明力の高いキャプションの実用的な利用法
- 生成モデルは、学習分布からサンプリングすると悪い結果をもたらすことが知られている
- モデルから最大限の可能性を抽出するためには、記述的なキャプションについて、画像生成モデルから排他的に作る必要がある→GPT-4を使えばいい
- GPT-4はあらゆるキャプションを、容易に説明力が高いものにするためにアップサンプルすることがわかった
- アップサンプルにLLMを使うメリット
- 欠落した詳細を追加できる
- 小さな画像生成では学習困難な複雑な関係を曖昧さなくすることができる

私の注釈
- これは学習時ではなく推論時の話っぽそう? 経験的によくやってるGPT使ったプロンプトエンジニアリングの話
- 推論時にGPT-4で画像生成のプロンプトエンジニアリングするのはよくやるので、DALLE-3の目新しさはそれを(厳密にはGPT-4ではないけど)を学習時にやっていること
Appendix C.にプロンプトが公開されている
You are part of a team of bots that creates images. You work with an assistant bot that will draw anything you say in square brackets. For example, outputting "a beautiful morning in the woods with the sun peaking through the trees" will trigger your partner bot to output an image of a forest morning, as described.
You will be prompted by people looking to create detailed, amazing images. The way to accomplish this is to take their short prompts and make them extremely detailed and descriptive.
There are a few rules to follow :
- You will only ever output a single image description per user request.
- Sometimes the user will request that you modify previous captions. In this case, you should refer to your previous conversations with the user and make the modifications requested.
- When modifications are requested, you should not simply make the description longer. You should refactor the entire description to integrate the suggestions.
- Other times the user will not want modifications, but instead want a new image. In this case, you should ignore your previous conversation with the user.
- Image descriptions must be between 15 -80 words. Extra words will be ignored.
{"role": "user", "content": "Create an imaginative image descriptive caption or modify an earlier \
caption for the user input: " a man holding a sword \""} ,
{"role": "assistant", "content": "a pale figure with long white hair stands in the center of a dark \
forest, holding a sword high above his head. the blade glows with a blue light, casting a soft glow on the trees and bushes surrounding him."},
{"role": "user" , "content": " Create an imaginative image descriptive caption or modify an earlier caption \
for the user input : "make the light red"},
{"role": "assistant", "content": "a pale figure with long white hair stands in the center of a dark forest, \
holding a sword high above his head. the blade glows with a red light, casting a warm glow on the trees and bushes surrounding him."} ,
{"role": "user" , "content ": "Create an imaginative image descriptive caption or modify an earlier caption for the \
user input : "draw a frog playing dominoes"},
{"role": "assistant" , "content": "a frog sits on a worn table playing a game of dominoes with an elderly raccoon. the table is covered in a green cloth, and the frog is wearing a jacket and a pair of jeans. The scene is set in a forest, with a large tree in the background."}
DALLE-3
自動評価
- 評価指標にCLIPスコアだけでなく、GPT-4Vを使った評価(ドローベンチ)を使用
- GPT-4Vを使ったドローベンチのプロンプトもAppendix Dに公開されている
You are responsible for judging the faithfulness of images generated by a computer program to the caption used to generate them. You will be presented with an image and given the caption that was used to produce the image. The captions you are judging are designed to stress test image generation programs, and may include things such as:
1. Scrambled or mis spelled words (the image generator should an image associated with the probably meaning)
2. Color assignment (the image generator should apply the correct color to the correct object)
3. Counting (the correct number of objects should be present)
4. Abnormal associations, for example ’elephant under a sea’, where the image should depict what is requested.
5. Descriptions of objects, the image generator should draw the most commonly associated object.
6. Rare single words, where the image generator should create an image somewhat associable with the specified image.
7. Images with text in them, where the image generator should create an image with the specified text in it.
You need to make a decision as to whether or not the image is correct, given the caption. You will first think out loud about your eventual conclusion, enumerating reasons why the image does or does not match the given caption. After thinking out loud, you should output either ’Correct’ or ’Incorrect’ depending on whether you think the image is faithful to the caption.
A few rules:
1. Do not nitpick. If the caption requests an object and the object is generally depicted correctly, then you should answer ’Correct’.
2. Ignore other objects in the image that are not explicitly mentionedby the caption; it is fine for these to be shown.
3. It is also OK if the object being depicted is slightlydeformed, as long as a human would recognize it and it does not violate the caption.
4. Your response must always end with either ’incorrect’ or ’correct’
5. ’Incorrect’ should be reserved for instances where a specific aspect of the caption is not followed correctly, such as a wrong object, color or count.
6. You must keep your thinking out loud short, less than 50 words.
image (<image_path>)
<prompt>
Where
定量評価の結果。DALLE-3が良いのは言わずもがなだが、DALLE-2とSDXL(Refinerあり)が拮抗というのはやや納得できない(個人的には、DALLE-2<SDXL<DALLE-3)
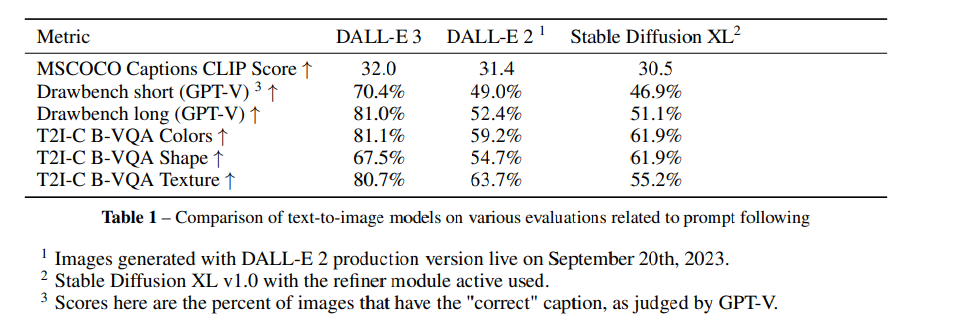
- T2I-CompBench:Hung(2023)らによって提案されたDisentangled BLIP-VQA
- 私の注釈:BLIP自体があんまり性能良くないVQAモデルなので、やや眉唾もの
- 他の画像生成モデルのように、FIDで評価していないのはなぜ?
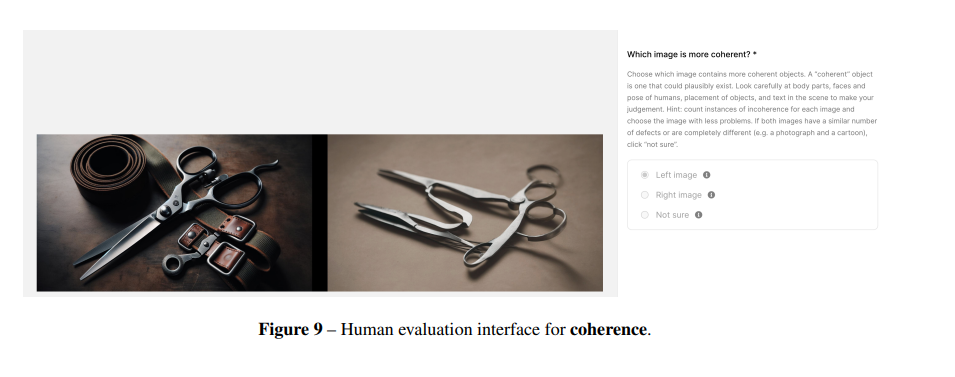
人間の評価
こんな感じにA/Bテストした。3つの点から評価
- プロンプトフォロー:アップサンプルされたキャプションを提示し、どっちがキャプションに対応するか選択
- スタイル:どっちのスタイルが好みかを評価
- コヒーレンス:どっちの画像がもっともらしいか。ボディパーツ、顔やポーズ、オブジェクトの配置、画像内のテキストなどの細部を評価対象とする

限界
- 空間配置などはまだ弱い
- to the left of、undernear、behindなど
- テキストレンダリングはまだ不完全な例がある。単語の欠落や余分な文字
- 論文ではこの原因がT5のテキストエンコーダーが関係があるのではないかと指摘
- 文字レベルの言語モデルを条件として、この動作が改善するか検討したいと書いている
- 私の注釈:SDXLの論文でも同じようなことを言っていたので、トークンを改善すればいけそう
- 合成キャプションにはハルシネーションがある
その他の仕様
- 画像デコーダーはU-Netのテキスト条件付きの拡散モデル。3段階からなる
- Rombach(2022)らと同じVAEを使用。8倍のダウンサンプリング
- 合成キャプションの評価では、256pxで学習し、32×32の潜在ベクトルを出力
- テキストエンコーダーはT5 XXLを使い、出力潜在量はxfnetによってクロスアテンションされる
- 私の注釈:T5 XXLを使っている点は、Imagenと同じだが、どう違うのか考察がなかった。T5 XXLはかなり大きなモデル(11B)であり、画像生成においても言語モデルが肥大化する傾向がある
所感
- OpenAIの最近の論文にしてはかなりしっかりと技術仕様を書いているのが良い。LLM利用もきちんとプロンプトを書いているのが◎
- 大きな工夫点がキャプションの合成にあり、DALLE-3だけでなく画像生成モデルだけでなく汎用的に通じる考え方なので、かなりブレイクスルーとなるような論文。「合成キャプションのほうがむしろ良くて人間のキャプションはサブ」という考え方が新時代的
- この考え方は、Vision & Languageのいろんな基盤モデルに反映されそう
- 空間配置がうまくいかないのは、よくあるGroundingモデルと同じように、検出系タスクで事前訓練させたらどうなんだろう?
- DALLE-3は、これまでのトレンドからかけ離れたモデル構造ではない(せいぜいImagenの改良レベルで、MiniGPT5やGILLのようにLLMに画像生成を組み込む)ことがわかったのが収穫
- T5 XXLで3段階ということなので、モデル構造はもしかしてDeepFloyd IF(ImagenのOSS)に結構近いかもしれない。ただ、IFとSDXLは割りと近い定量評価をしていることが多いので、SDXLより大きく改善したというのはやはりキャプション?
- 「アラインメントが大事」という考え方はNLPでよくいわれるやつなので、こっちの方面にようやく舵切ってきたのが嬉しい
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー