
論文まとめ:Decoder Denoising Pretraining for Semantic Segmentation
Posted On 2022-07-21


- タイトル:Decoder Denoising Pretraining for Semantic Segmentation
- 論文:https://arxiv.org/abs/2205.11423
- 著者:Emmanuel Brempong Asiedu, Simon Kornblith, Ting Chen, Niki Parmar, Matthias Minderer, Mohammad Norouzi
- 所属:Google Research
目次
ざっくりいうと
- Few-shotのセマンティックセグメンテーションでの精度向上を研究した論文
- セマンティックセグメンテーションでは、通常はEncoderを訓練済みモデル(ImageNet等)、Decoderはランダムな重みで初期化して訓練する
- しかし、Decoderをランダムな重みで初期化するのはよくなく、セグメンテーションの前に、Denoisingの問題としてDecoderを訓練したほうが、特にFew-shotにおいていいことがわかった
- 拡散モデルに着想を得たものだが、従来のSoTAを上回る一貫した性能向上を示した
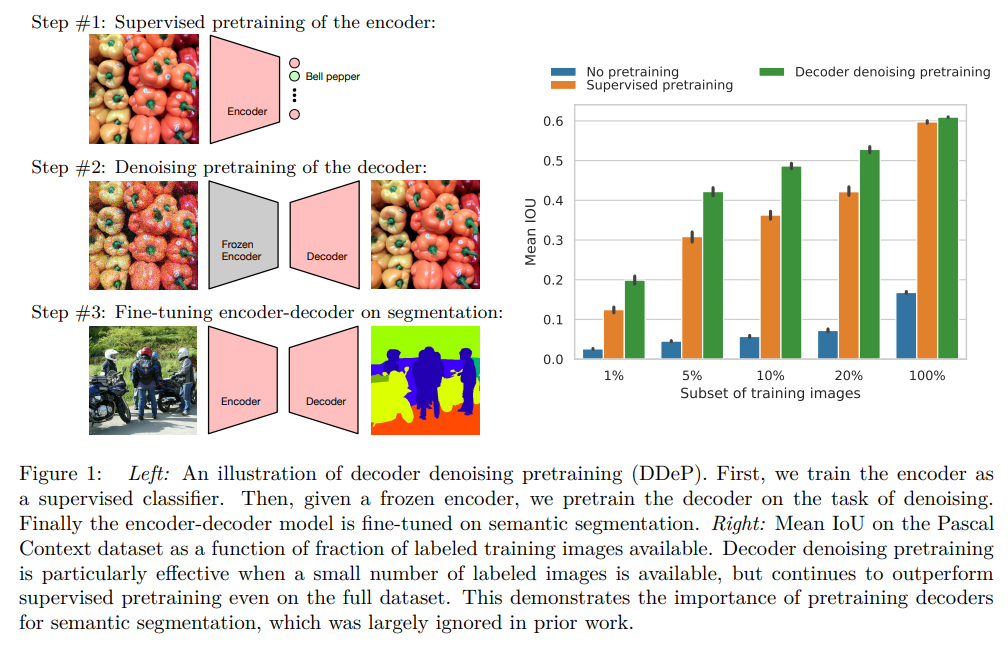
背景
- Denoisingは、ノイズのある画像をInputとして、ノイズのない画像をOutputとするもの
- 訓練は、一般的にはクリーンデータにノイズを加えInputとして学習させる
- モデルがデータ分布を学習する必要がある
- Denoisingは、ピクセル単位で簡単に定義できるため、セマンティックセグメンテーションのような高密度な予測モデルの学習に適している。
- Denoisingの考え方は古いが、ノイズ除去拡散確率モデルの文脈で新しい関心を集めている
事前訓練としてのDenoising
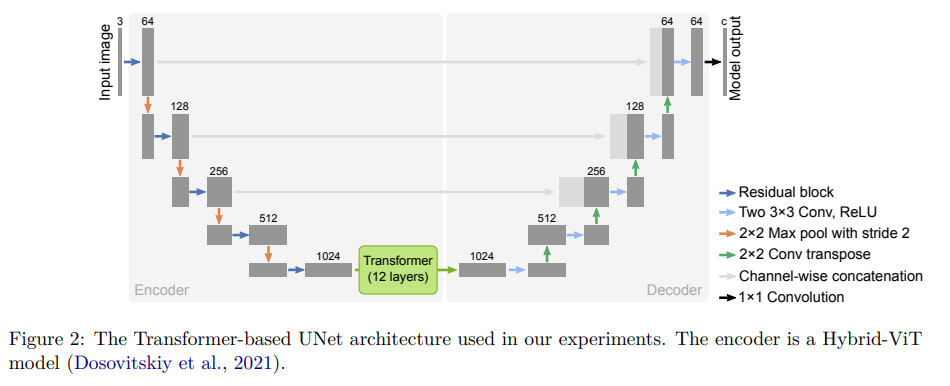
ネットワーク構造
Hybrid-ViT (Dosovitskiy et al., 2021)を使用。U-Netなのだが、ボトルネックレイヤーにTransformerのレイヤーが入っている。
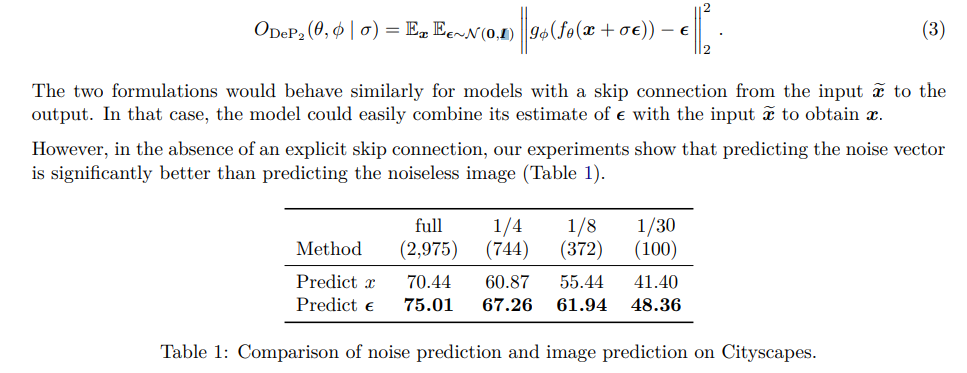
事前訓練として使う場合は、ノイズを予測したほうが良い
拡散モデルでは、通常クリーンな画像$x$ではなく、ノイズベクトル$\epsilon$を予測する。この実験でも同様で、ノイズベクトルを予測したほうが、あとのセマンティックセグメンテーションの精度が良かった。
Denoisingをモデル全体で学習させると悪化する
あくまで提案手法は、DenoisingをDecoderのみで訓練する。Denoisingにおいて、モデル全体で訓練すると、微妙な結果になった。
このケースでの、Few-shotの場合の利点はわずかで、データが多い場合はDenoisingなし(Supervised:ImageNetで訓練済みのEncoder+ランダム初期化のDecoder)より劣る結果となった。
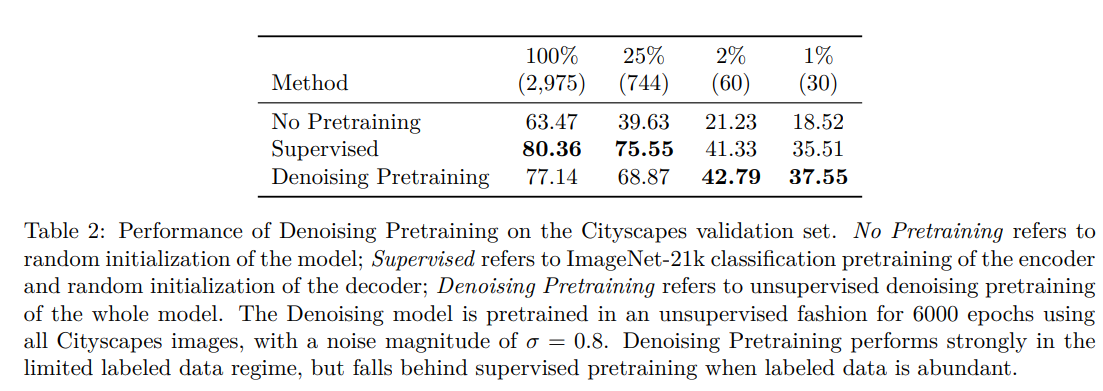
DecoderのみのDenoisingの訓練(DDeP)のほうがSupervisedに対して一貫して良い結果となった。
データセット=CitySpace
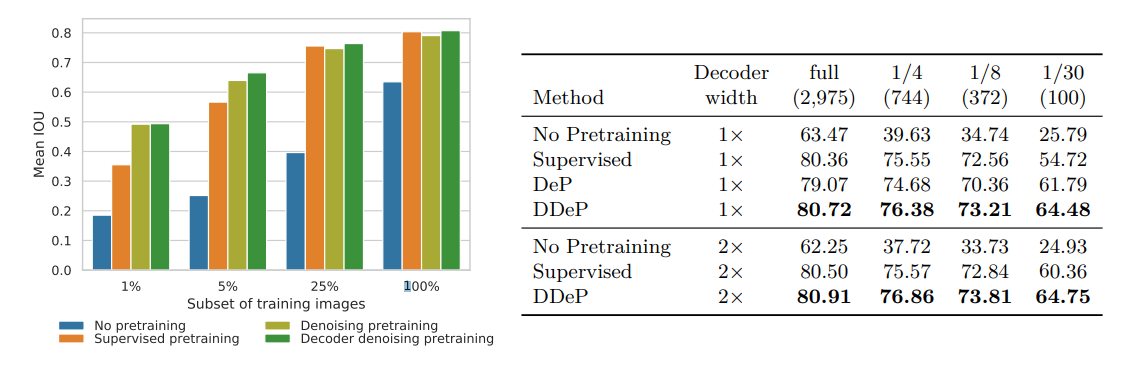
データセット=ADE20K

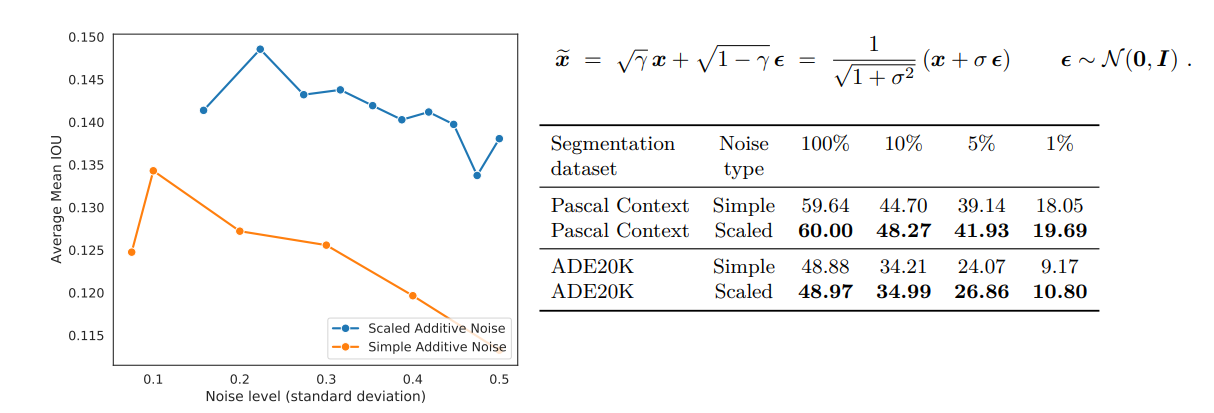
ノイズの工夫
ノイズのスケールに応じて、入力画像を定数倍するような処理を加えてあげると良い
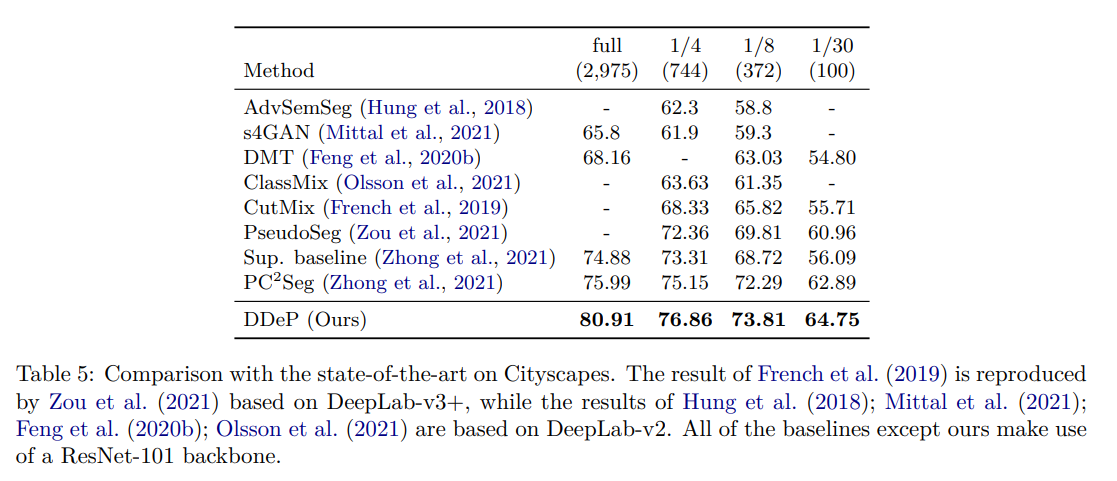
既存手法との比較
訓練画像の数に応じてみたときに、全てSoTAになった
まとめと感想
- 拡散モデルのDenoisingに着想を得て、Few-shotだけでなく、訓練データの数に関係なくロバストな精度向上手法を提案した
- Denoisingがどの程度意味を持つのかよくわからないケースもありそうだが、発想としては面白いし、Few-shotのときにやってみても面白いのではないか
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー