
論文まとめ:Flamingo: a Visual Language Model for Few-Shot Learning
Posted On 2023-04-06


- タイトル:Flamingo: a Visual Language Model for Few-Shot Learning
- 著者:Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miechなど(多すぎるので割愛、DeepMind)
- カンファ:NeurIPS 2022
- 論文URL:https://arxiv.org/abs/2204.14198
目次
ざっくりいうと
- GPTライクなFew-shotを、画像/動画/テキストのクロスモーダルで行う研究
- 訓練済みの画像エンコーダーとLLMに、Perceiver ResamplerとGated XAttenを追加しつなぐ
- タスクに対応した「良いデータ」を作るための工夫が多数見受けられる

ニュース
- OpenFlamingoが公開された
- OpenFlamingo 9Bのモデルのみ公開されている(LLaMA-7Bを使っているため商用利用不可)
- 非常に参考になる解説:https://www.slideshare.net/DeepLearningJP2016/dlflamingo-a-visual-language-model-for-fewshot-learning-253636063
はじめに
- CLIPみたいなマルチモーダルモデルが出てるけど、テキストと画像の類似度を学習するだけで、キャプションやVQAみたいなタスクに適用できないよね
- 画像・動画とテキストを組み合わせて、GPTみたいななFew-shotをしたいよ(これらに着想を得た)
- Flamingoは、入力「画像や動画に挟まれたテキストトークン列」、出力「テキストを生成」。視覚条件付き自己回帰型テキスト生成モデル
- 私の所感:画像や動画を1つのトークンにしちゃうやり方あまり賢くないかもしれない
- 訓練済みのVisionモデルと、訓練済みのLLM(この論文ではLLMのことをLMと書いてある)を両方フリーズしたまま活用
- 私の所感:研究的にはあとだけど、BLIP-2と思想が近そう
- Flamingoの訓練方法が性能にとって重要
- アノテーションされたデータを一切使用せず、ウェブから得られる補完的な大規模マルチモーダルデータを慎重に選び混ぜて訓練
- この訓練だけで、下流タスク特化の訓練なく、GPTみたいなFew-shotができるようになった
アプローチ
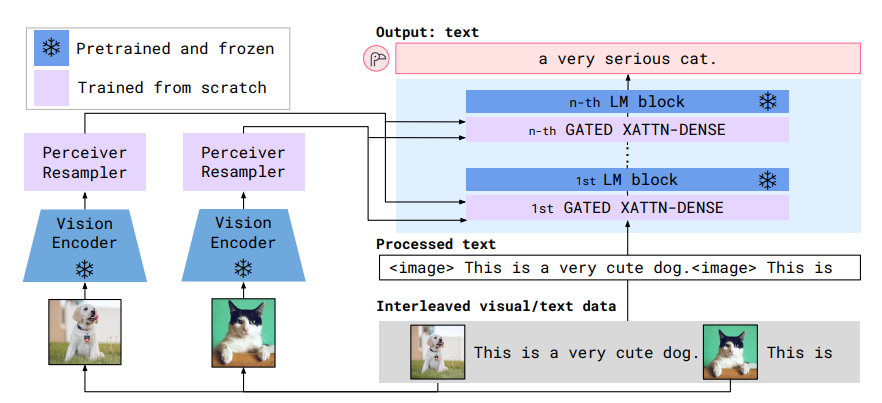
- Perceiver Resampler
- 画像/動画の空間的、時間的な情報を受け取る
- 固定サイズのVisual Tokenを出力する
- 私の所感:このVisual Tokenが静止画・動画共通の表現を持ってそう
- このVisual Tokenはクロスアテンションを使ってLLMのレイヤーに挟み込む
- 私の所感:LLMではないけどやり方が最近のStable Diffusionでよく見るやつ
Perceiver Resampler
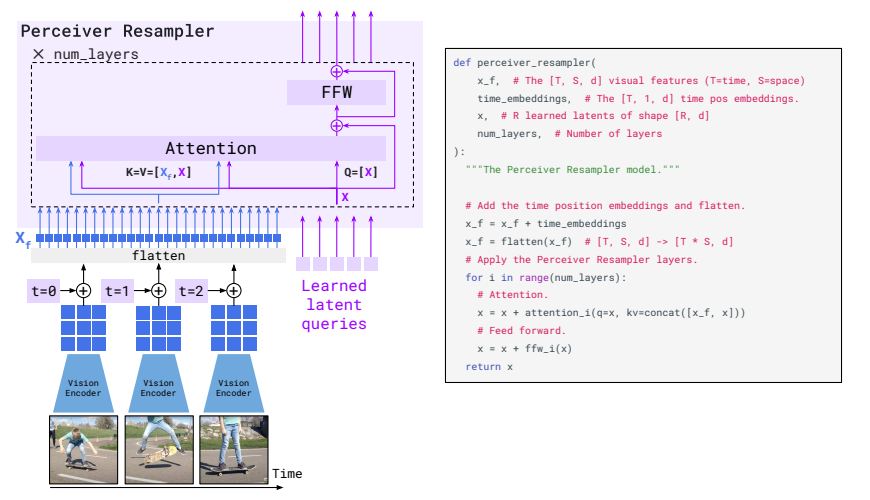
- 普通にフレーム単位で特徴量を取る(x_f)
- 時間単位のPositional Embeddingを追加する
- Perceiver Resamplerの中でLearned Latent Queryとくっつけて、Attentionをとる。これとFFWで固定長に変換する
- Latent QueryはPerceiverやDETRでもやってるらしい
- Perceiverという元ネタになった研究がある
Gated Cross Attention Layer
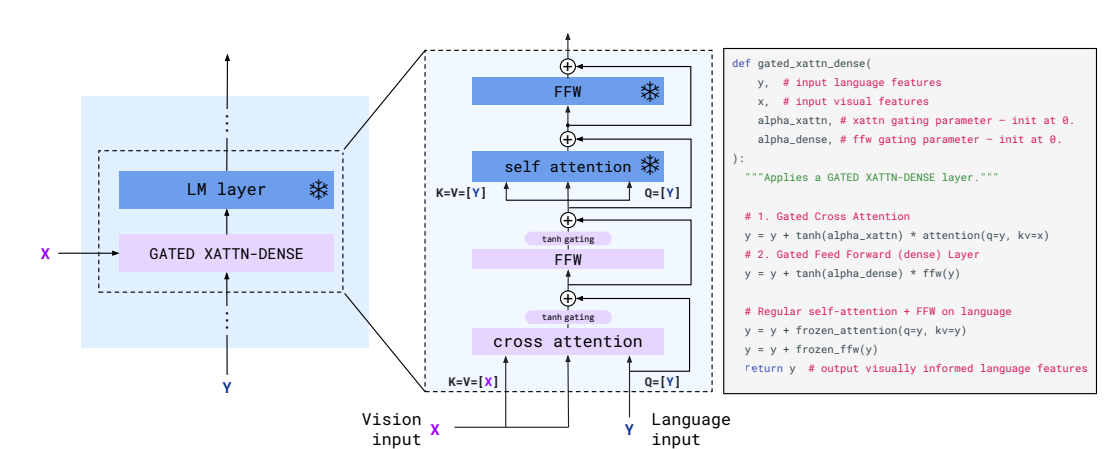
- フリーズしたLLMの層の間にGated Cross Attentionを入れて、そこだけ学習させるよ
- 前後にtanhによるGatingが入ったクロスアテンション
- tanhによるGatingを入れたい動機
- 初期化時にLLMがそのまま維持されてほしい。安定性と性能を向上させたい
- 初期化時に、条件付きモデルが元の言語モデルと同じ結果をもたらすことを保証したい。tanhならそれができる
- 私の所感:Stable DiffusionのControlNetのZero Convolutionと同じような気持ち
複数の画像のInput対応
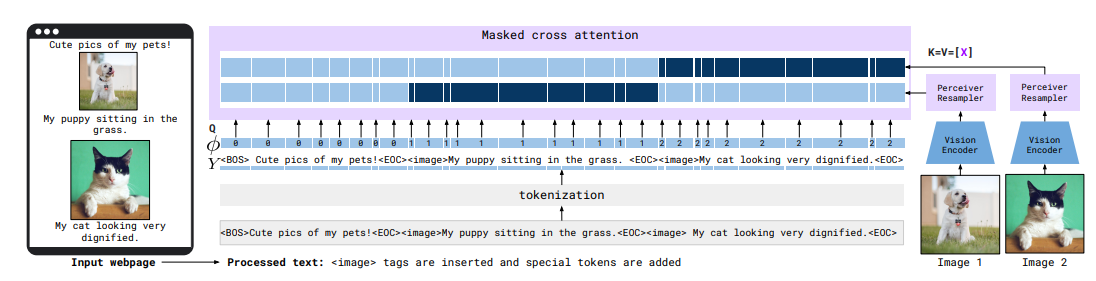
- 画像・動画のクロスアテンションを完全にマスクする
- お気持ち:マスクしないと全部の画像を見ちゃうよね。キャプションと画像の単一対応を明確にしたい
- 私の所感:当たり前かもしれないけど結構頭いい
ベースとなったモデル
- Vision Encoder:NormalizerFree ResNet (NFNet) のF6
- 私の所感:ViTではない!? ~どっちもDeepMindなのでNFNetのステマ?~ →普通に強かったですすみませんでした
- LLM:Chinchillaの1.4B, 7B, 70Bを使い、それぞれFlamingo-3B、Flamingo-9B、Flamingo-80Bとした
- 私の所感:正直何のLLMでも差し込めそうなので、Chinchillaでなくても良い
データセットをどうしたか
- M3W(MultiModal MassiveWeb)
- スクレイピングして作ったデータセット
- 43Mページからスクレイピング → DOM解析 → 泥臭い前処理 → 「image」や「EOC」のトークン付け
- こんな感じに、Webベージとキャプションの対応関係は必ずしも直後にあるわけではないので、対応を入れ替えるようなAugmentationをする

- ALIGN Dataset(画像・動画とテキストのペア)
- 1.8B枚の画像とAlt-Text(多分HTMLのalt属性)のペア
- Alt-Textでうまく説明されていないことも多く、ノイズが多い
- 補強データセットが必要
- これを補強するために
- LTIP(Long Text & Image Pair):312Mの長い文章と画像のペアのデータを追加
- VTP(Video & Text Pair):平均22秒の27Mの動画と文章のペアで構成
- 1.8B枚の画像とAlt-Text(多分HTMLのalt属性)のペア
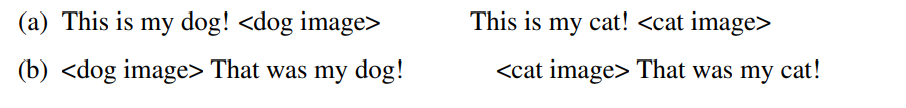
私の所感:思ったよりデータ数多い! ってかデータの作成部分がメインじゃないの?
ちなみにOpen Flamingoでは、訓練用のDatasetを用意していて準備中
結果
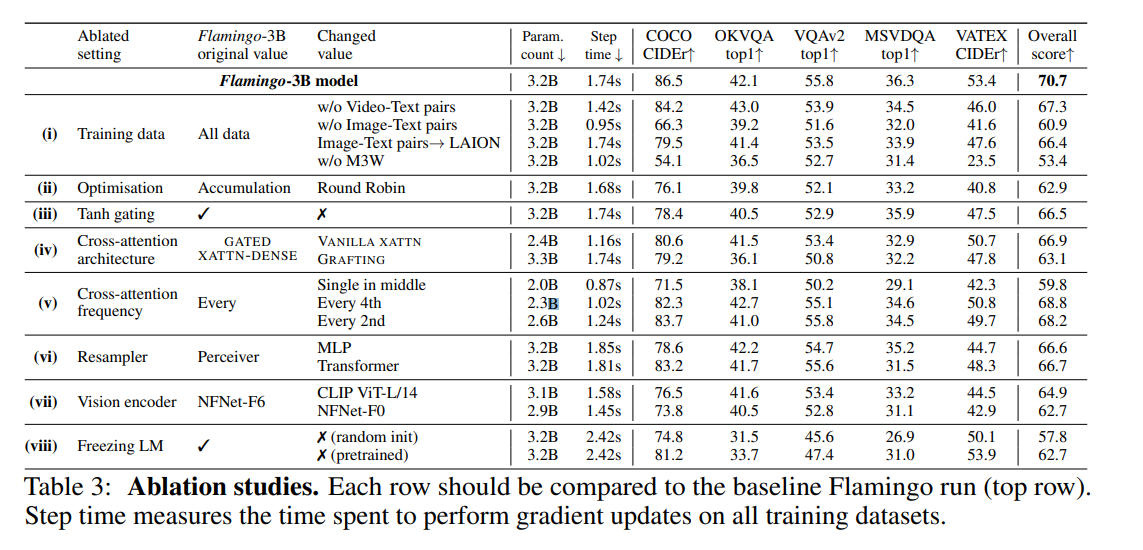
- 一 番 効 い て い る の は デ ー タ
- LAIONはLAION 400Mでちょっと落ちた
- 私の所感:データがノイジーだから割りと理解できる
- Tanh gatingを外すと結構落ちるのが示唆に富む
- NFNet-F6をCLIP ViT-L/14に落とすと結構落ちる
- NFNet-F6:438.4M / ViT-L/14:303.97M
訓練リソース
- Flamingoの訓練
- TPUv4が1536chipで15日
- 16デバイスでシェア
- Vision Encoderの事前訓練
- TPUv4が512chips
- 私の所感:Frozenしてるから計算量軽いかなーと思ったけどめちゃくちゃ膨大だった!
所感
- 動画も画像も同じ固定長の潜在変数に変換してるってのがなかなかいい
- LLaMA以外で訓練されたOpen Flamingoが出たら神
- 一番効いているのは「クリーンした膨大なデータで殴る」という身も蓋もない結果
- DeepMind先生のTPUじゃぶじゃぶ芸ハンパない
- GPT-4先生の画像Inputにご期待ください
Shikoan's ML Blogの中の人が運営しているサークル「じゅ~しぃ~すくりぷと」の本のご案内
技術書コーナー
北海道の駅巡りコーナー